1. Introduction & Overview

What is Fault Tolerance?
Fault Tolerance is the ability of a system, network, or application to continue functioning properly in the event of the failure of some of its components. It is a foundational concept in resilient system design and plays a vital role in ensuring high availability, reliability, and service continuity.
History or Background
Fault Tolerance emerged from the domain of distributed computing in the 1970s and 1980s, when researchers began to design systems that could recover from hardware or software faults without interrupting services. As systems became more complex and moved to the cloud, the concept evolved into a cornerstone of site reliability engineering (SRE), high-availability architecture, and, more recently, DevSecOps pipelines.
Why is it Relevant in DevSecOps?
In DevSecOps, which merges development, security, and operations, fault tolerance ensures that:
- Security monitoring tools remain operational even during infrastructure failures.
- Pipelines self-recover from build, test, or deployment failures.
- Systems can withstand attacks or misconfigurations without complete service degradation.
- Compliance and audit logging continues uninterrupted.
2. Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| Fault | An abnormal condition or defect at the component, equipment, or sub-system level. |
| Failure | The inability of a system to perform its required function. |
| Redundancy | Duplication of critical components to ensure fault tolerance. |
| Failover | Automatic switching to a standby system or component in case of failure. |
| Graceful Degradation | Maintaining partial service functionality when parts of a system fail. |
| Resilience | The system’s ability to recover quickly from faults. |
How it Fits into the DevSecOps Lifecycle
| Stage | Role of Fault Tolerance |
|---|---|
| Plan | Include fault models, disaster recovery strategies in architecture decisions. |
| Develop | Code defensively and include retry mechanisms, circuit breakers. |
| Build & Test | Automated testing of failover scenarios and edge cases. |
| Release & Deploy | Use rolling deployments, blue/green or canary strategies to reduce blast radius. |
| Operate & Monitor | Monitor for anomalies, trigger alerts, and auto-heal components. |
| Secure | Maintain security controls and alerts even under partial system failure. |
3. Architecture & How It Works
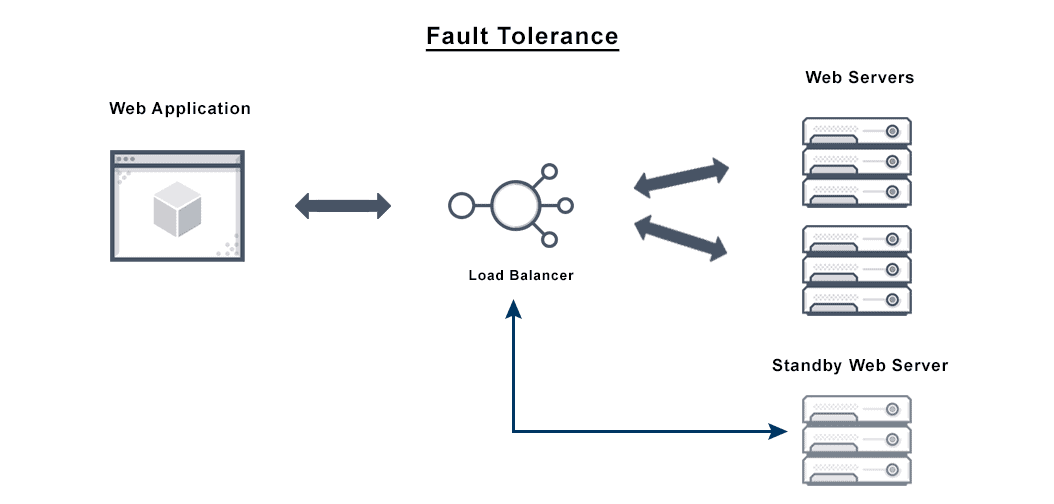
Components
- Load Balancers: Distribute traffic among healthy instances.
- Redundant Nodes: Multiple instances of services or applications.
- Health Checks: Monitor system/component status.
- Failover Mechanisms: Switch to healthy alternatives on failure.
- State Replication: Keeps data consistent across replicas.
- Auto-Healing Scripts: Trigger corrective actions automatically.
Internal Workflow
- A component fails (e.g., database instance crashes).
- Health checks detect the failure.
- Load balancer stops routing to the failed component.
- Redundant instance or failover node takes over.
- Alerts are triggered; auto-heal script may be executed.
- System continues operating without visible downtime.
Architecture Diagram (Textual Description)

+------------------+
| Load Balancer |
+--------+---------+
|
+-----------------+-------------------+
| |
+----v----+ +------v-----+
| Service | | Service |
| Node A | <---- Replication ----> | Node B |
+---------+ +------------+
| |
+----v----+ +------v-----+
| DB A | <---- Replication ----> | DB B |
+---------+ +------------+
If Node A or DB A fails, traffic automatically reroutes to Node B and DB B.
Integration Points with CI/CD or Cloud Tools
- CI/CD Pipelines (GitLab, GitHub Actions, Jenkins):
- Retry failed jobs
- Test failover scenarios in staging
- Cloud Platforms (AWS, Azure, GCP):
- Use managed services with built-in fault tolerance (e.g., AWS RDS Multi-AZ)
- Auto-scaling groups and instance health monitoring
- Monitoring Tools:
- Prometheus/Grafana for tracking health
- Alertmanager or PagerDuty for incident response
4. Installation & Getting Started
Basic Setup or Prerequisites
- Kubernetes or cloud infrastructure (e.g., AWS/GCP)
- CI/CD system (Jenkins/GitHub Actions)
- Monitoring setup (Prometheus + Grafana)
- Basic microservices or web app for testing
Hands-on: Step-by-Step Setup Guide
Scenario: Building Fault Tolerance into a Node.js App on Kubernetes
# Step 1: Clone app repository
git clone https://github.com/example/fault-tolerant-app.git
cd fault-tolerant-app
# Step 2: Deploy to Kubernetes with 2 replicas
kubectl apply -f k8s/deployment.yaml
# k8s/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: app
spec:
replicas: 2
selector:
matchLabels:
app: fault-app
template:
metadata:
labels:
app: fault-app
spec:
containers:
- name: app
image: your-registry/fault-app:latest
readinessProbe:
httpGet:
path: /health
port: 3000
initialDelaySeconds: 5
periodSeconds: 10
# Step 3: Add a Service and Load Balancer
apiVersion: v1
kind: Service
metadata:
name: fault-app-service
spec:
selector:
app: fault-app
type: LoadBalancer
ports:
- protocol: TCP
port: 80
targetPort: 3000
Test: Kill one pod. Kubernetes routes traffic to healthy pod automatically.
5. Real-World Use Cases
1. CI/CD Resilience
- Jenkins pipeline jobs automatically retry failed steps (e.g., flaky tests).
- GitHub Actions using
continue-on-errorfor non-critical steps.
2. Cloud-native Web Applications
- AWS ALB with EC2 Auto Scaling + RDS Multi-AZ setup.
- Ensures application and database failover during outages.
3. Container Orchestration
- Kubernetes ensures pods are self-healing.
- Deployments configured with readiness/liveness probes.
4. Security Monitoring Infrastructure
- SIEM tools deployed with redundancy.
- Alerting systems like Prometheus Alertmanager run in HA mode.
6. Benefits & Limitations
Key Advantages
- High availability & uptime
- Resilience to attacks or hardware failures
- Maintains compliance by preserving audit/logging systems
- Boosts user confidence and reliability
Common Challenges
- Increased cost due to redundancy
- Complexity in failover testing and orchestration
- Need for robust monitoring to detect silent failures
- Some stateful components (e.g., legacy databases) may require extra configuration
7. Best Practices & Recommendations
Security Tips
- Ensure encrypted communication even during failover.
- Avoid single points of failure in authentication or secret management.
- Use RBAC to secure failover scripts or tooling.
Performance & Maintenance
- Test failover regularly (chaos engineering).
- Monitor replication lag and health metrics.
- Automate patching and updates across redundant components.
Compliance & Automation
- Automate compliance checks (e.g., backups, replication).
- Maintain immutable infrastructure via IaC (e.g., Terraform).
- Include fault-injection tests in CI/CD.
8. Comparison with Alternatives
| Approach | Resilience | Complexity | Best For |
|---|---|---|---|
| Fault Tolerance | High | Medium-High | Real-time systems, financial platforms |
| Disaster Recovery (DR) | Medium | High | Non-critical apps needing slow recovery |
| High Availability (HA) | High | Medium | Web apps, backend APIs |
| Chaos Engineering | N/A (testing tool) | High | Simulated fault testing |
When to Choose Fault Tolerance:
- For mission-critical systems requiring zero downtime
- When immediate failover is a compliance or SLA requirement
- When systems must remain secure and auditable during faults
9. Conclusion
Fault tolerance is not just a luxury—it’s a necessity in modern DevSecOps workflows. It ensures services remain reliable, secure, and compliant even under adverse conditions. Integrating fault tolerance practices early in development and automating them across CI/CD and operations pipelines boosts system resilience and team productivity.
Next Steps
- Introduce chaos testing (e.g., Chaos Mesh, Gremlin)
- Automate fault-tolerant designs using Terraform or Helm
- Expand monitoring and alerting to predict failures