1. Introduction & Overview
What is Chaos Engineering?
Chaos Engineering is the practice of deliberately introducing faults or unpredictable conditions into a system to test its resilience, performance, and observability. The goal is to identify weaknesses before they become systemic failures in production.
In the context of DevSecOps, Chaos Engineering plays a crucial role in ensuring secure, resilient, and compliant software delivery pipelines.
History or Background
- Origin: Born at Netflix around 2011 with the creation of “Chaos Monkey” under their Simian Army suite.
- Purpose: Initially aimed at ensuring availability and fault-tolerance in cloud-native microservices.
- Evolution: Expanded to more formal methodologies involving hypothesis, blast radius, observability, and rollback mechanisms.
Why is it Relevant in DevSecOps?
- Security Resilience: Tests how security controls behave under stress or outage.
- Compliance Validation: Verifies if compliance rules (e.g., logging, access control) hold during faults.
- Automation-Friendly: Can be embedded in CI/CD pipelines for proactive reliability and security testing.
- Shift-Left Reliability: Encourages early testing of system degradation scenarios.
2. Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| Fault Injection | Introducing errors (e.g., latency, packet loss) to observe system behavior. |
| Blast Radius | The scope/extent of a chaos experiment’s impact. |
| Steady State | The baseline behavior or normal operating condition. |
| Hypothesis | The expected outcome assuming system resilience. |
| Abort Conditions | Predefined rules to halt the chaos test if danger thresholds are crossed. |
How It Fits into the DevSecOps Lifecycle
| Phase | Chaos Engineering Role |
|---|---|
| Plan | Define resilience objectives and threat modeling. |
| Develop | Integrate fault simulation in unit/integration tests. |
| Build | Test builds against failure conditions. |
| Test | Run chaos experiments in test environments. |
| Release | Validate system integrity before deployment. |
| Deploy | Chaos in staging or canary releases. |
| Operate | Real-time chaos for observability and incident response. |
| Monitor | Validate logs, metrics, and alerts during chaos. |
| Secure | Test security responses under fault conditions. |
3. Architecture & How It Works
Components
- Chaos Controller: Orchestrates and manages experiments (e.g., LitmusChaos, Gremlin).
- Target Systems: Microservices, databases, networks, or containers.
- Observability Stack: Prometheus, Grafana, ELK for metrics and alerts.
- Experiment Engine: Executes actions such as CPU stress, pod kill, or network latency.
- Rollback Mechanism: Reverts changes post-experiment.
Internal Workflow
- Define Steady State
- Form Hypothesis
- Design Experiment
- Run Chaos Injection
- Observe Behavior
- Analyze Outcome
- Mitigate and Harden
Architecture Diagram Description
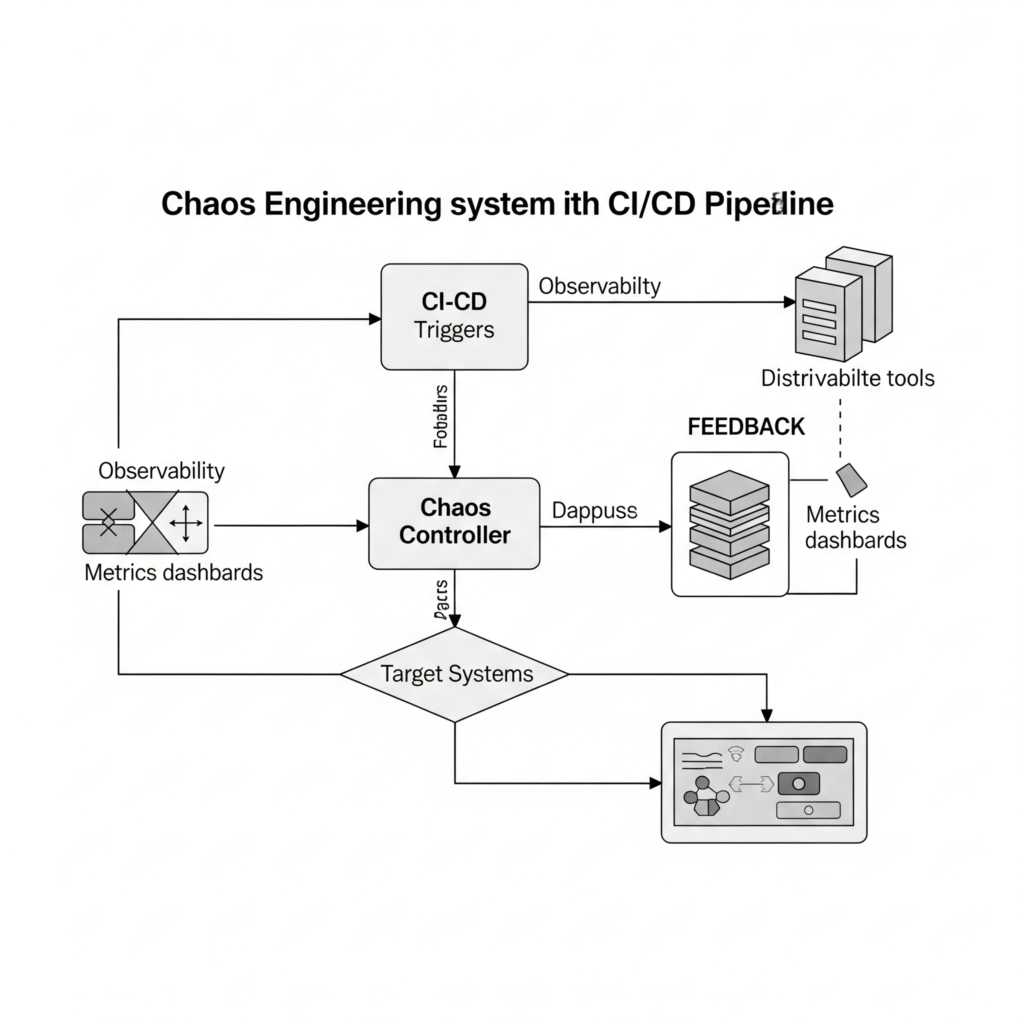
Textual Description:
- CI/CD pipeline triggers the Chaos Controller.
- The controller interacts with Target Systems (Kubernetes pods, cloud VMs, APIs).
- Simultaneously, Observability tools track metrics.
- Post-experiment, results are logged, and alerts are analyzed.
- Feedback is looped back to development for fixing resiliency gaps.
Integration Points with CI/CD or Cloud Tools
| Tool | Integration |
|---|---|
| Jenkins/GitLab CI | Chaos stages in pipeline using plugins or scripts. |
| ArgoCD | Run chaos as a pre-deployment hook. |
| AWS Fault Injection Simulator | Native chaos for EC2, RDS, etc. |
| Kubernetes | Run chaos in pods/nodes using Litmus or Chaos Mesh. |
4. Installation & Getting Started
Basic Setup or Prerequisites
- Kubernetes Cluster (minikube or cloud-based)
- kubectl installed
- Chaos tool (e.g., LitmusChaos)
Hands-on: Step-by-Step Setup with LitmusChaos
# Step 1: Install Litmus on Kubernetes
kubectl apply -f https://litmuschaos.github.io/litmus/litmus-operator-v3.yaml
# Step 2: Verify Pods
kubectl get pods -n litmus
# Step 3: Create a Chaos Experiment (Pod Delete)
kubectl apply -f https://hub.litmuschaos.io/api/chaos/1.13.8?file=pod-delete/experiment.yaml
# Step 4: Create a Chaos Engine
kubectl apply -f https://hub.litmuschaos.io/api/chaos/1.13.8?file=pod-delete/engine.yaml
# Step 5: Monitor Results
kubectl get chaosresults -n litmus
5. Real-World Use Cases
DevSecOps Scenario 1: Kubernetes Pod Kill
- Goal: Test whether security monitoring agents restart properly.
- Outcome: Revealed improper init container configuration that bypassed logging.
Scenario 2: API Latency Injection
- Goal: Introduce 1s delay in API response to test timeout handling.
- Outcome: Highlighted missing retry logic in frontend.
Scenario 3: Network Partitioning
- Goal: Simulate inter-region traffic loss in cloud.
- Outcome: Detected unencrypted fallback routes during failover.
Scenario 4: Security Token Expiry During Failure
- Goal: See how expired IAM roles affect app behavior during chaos.
- Outcome: Auth failures were not gracefully handled; fix implemented.
6. Benefits & Limitations
Key Advantages
- Uncover hidden bugs before they impact users
- Improve incident response preparedness
- Validate security and compliance controls
- Strengthen defense-in-depth strategy
Common Challenges or Limitations
- Misconfigured chaos can cause outages
- Requires strong observability
- Hard to define “steady state” for complex apps
- Limited support in traditional (non-cloud-native) systems
7. Best Practices & Recommendations
Security Tips
- Isolate test environments or use sandboxing
- Limit blast radius to reduce risk
- Define clear abort conditions
- Use role-based access control for chaos permissions
Performance and Maintenance
- Regularly tune observability and thresholds
- Version-control chaos experiments
- Schedule during low-traffic hours in production
Compliance & Automation
- Audit logs of chaos runs
- Use policy-as-code (OPA, Kyverno) to restrict unsafe experiments
- Automate via GitOps or CI/CD (e.g., Jenkins or ArgoCD integration)
8. Comparison with Alternatives
| Approach | Chaos Engineering | Load Testing | Monitoring |
|---|---|---|---|
| Focus | Failure simulation | Performance limits | Observability |
| Timing | Pre/post-deploy | Pre-production | Continuous |
| Security Testing | Yes | No | Indirect |
| Tool Examples | Litmus, Gremlin | JMeter, Gatling | Prometheus, Datadog |
When to Choose Chaos Engineering
- When testing system resilience is a priority
- When security under fault conditions must be validated
- When CI/CD resilience and rollback capability are critical
9. Conclusion
Chaos Engineering is a powerful tool for proactive fault analysis, especially when integrated into a DevSecOps pipeline. It helps uncover potential vulnerabilities and system weaknesses before they escalate into major incidents. By simulating real-world faults—be it pod crashes, network failures, or security breakdowns—teams can better design resilient, secure systems.
Future Trends
- Integration with AI for adaptive chaos experiments
- Fine-grained policy-driven chaos governance
- Expansion in regulated industries (banking, healthcare)