Introduction & Overview
What is an Incident Commander?
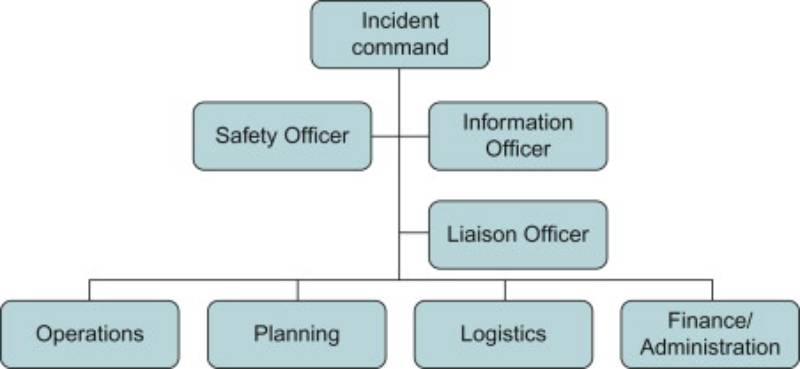
The Incident Commander (IC) is a pivotal role in Site Reliability Engineering (SRE) incident management, responsible for coordinating and leading the response to critical system incidents. The IC acts as the central point of authority during an outage or service disruption, ensuring effective communication, decision-making, and resolution to minimize downtime and impact on users. This role is rooted in structured incident response frameworks, such as the Incident Command System (ICS), adapted from emergency response disciplines like firefighting and applied to IT operations.
History or Background
The concept of the Incident Commander originates from the Incident Command System, developed in the 1970s in the United States to manage wildfires and other large-scale emergencies. Google adopted and refined this framework for SRE, formalizing it as part of their Incident Management at Google (IMAG) system. The IC role became a cornerstone of SRE practices, as outlined in Google’s Site Reliability Engineering book, to handle the complexity of modern, distributed systems. Over time, other tech giants like Amazon, Microsoft, and Netflix have adopted similar roles, tailoring them to their operational needs.
Why is it Relevant in Site Reliability Engineering?
In SRE, where system reliability and uptime are paramount, incidents are inevitable due to the complexity of distributed systems. The IC role is critical for:
- Minimizing Downtime: Rapid coordination reduces Mean Time to Resolution (MTTR).
- Clear Communication: Ensures stakeholders and teams are aligned during chaotic incidents.
- Learning and Improvement: Facilitates blameless postmortems to prevent recurrence.
- Scalability: Enables structured responses in large, cross-functional teams managing global services.
Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| Incident | An unplanned disruption or degradation of service impacting users or systems. |
| Incident Commander (IC) | The individual responsible for coordinating and leading incident response. |
| Incident Management | The process of detecting, responding to, and resolving incidents to restore service. |
| Mean Time to Resolution (MTTR) | The average time taken to resolve an incident. |
| Blameless Postmortem | A review process post-incident to analyze root causes without assigning blame. |
| Service Level Objective (SLO) | A target level of service reliability, often tied to alerting mechanisms. |
| Runbook | A documented guide with steps to troubleshoot and mitigate specific issues. |
| Communications Lead (CL) | Role responsible for stakeholder updates during an incident. |
| Operations Lead (OL) | Role focused on technical mitigation and resolution during an incident. |
Incident Occurs → Detection → Declare Incident → IC Assigned
→ Roles Assigned → Mitigation → Resolution → Postmortem → Prevention
How It Fits into the Site Reliability Engineering Lifecycle
The IC role is integral to the SRE lifecycle, which includes system design, monitoring, incident response, and continuous improvement:
- Preparation: The IC ensures runbooks, on-call schedules, and alerting systems are in place.
- Response: The IC leads the response, coordinating between technical teams and stakeholders.
- Recovery: The IC oversees service restoration and documentation.
- Learning: The IC drives postmortems to identify root causes and implement preventive measures.
Architecture & How It Works
Components and Internal Workflow
The IC operates within a structured incident response framework, typically involving:
- Incident Detection: Alerts from monitoring tools (e.g., Prometheus, PagerDuty) trigger the response.
- Incident Declaration: The IC assesses severity (e.g., SEV-0 to SEV-4) and declares the incident.
- Role Assignment: The IC assigns roles like Communications Lead, Operations Lead, and Scribe.
- Coordination: The IC manages communication channels (e.g., Slack, Zoom bridges) and delegates tasks.
- Mitigation: The IC oversees technical efforts to restore service, often using runbooks or automated tools.
- Resolution and Postmortem: The IC ensures documentation and a blameless postmortem to prevent recurrence.
Architecture Diagram
Below is a textual description of the Incident Command architecture, as images cannot be included:
[Monitoring Systems: Prometheus, Grafana, Zabbix]
↓ (Alerts)
[Incident Detection: PagerDuty, OpsGenie]
↓ (Notifies)
[Incident Commander]
↕ (Coordinates)
[Roles: Communications Lead, Operations Lead, Scribe, SMEs]
↕ (Tasks via)
[Communication Channels: Slack, Zoom, Email]
↕ (Mitigation via)
[Runbooks, Automation Tools, CI/CD Pipelines]
↓ (Restores)
[Service Restoration]
↓ (Documents)
[Postmortem and Root Cause Analysis]
- Monitoring Systems detect anomalies and send alerts.
- Incident Detection tools notify the on-call team.
- IC coordinates with assigned roles via communication channels.
- Runbooks and Automation Tools guide mitigation.
- Postmortem documents lessons learned.
Integration Points with CI/CD or Cloud Tools
- CI/CD: The IC may trigger rollbacks or redeployments via tools like Jenkins or GitLab CI to revert faulty releases.
- Cloud Tools: Integration with cloud platforms (e.g., AWS CloudWatch, Google Cloud Monitoring) for real-time metrics and automated scaling during incidents.
- Incident Management Platforms: Tools like PagerDuty or OpsGenie automate notifications and role assignments, streamlining the IC’s workflow.
Installation & Getting Started
Basic Setup or Prerequisites
To implement an IC-led incident response process:
- Monitoring Tools: Install Prometheus, Grafana, or Zabbix for real-time monitoring.
- Incident Management Platform: Set up PagerDuty or OpsGenie for alerting and escalation.
- Communication Tools: Configure Slack or Microsoft Teams for incident channels.
- Runbooks: Document service-specific runbooks in a centralized repository (e.g., Confluence).
- Training: Train SREs on the IC role through simulations like “Wheel of Misfortune.”
Hands-on: Step-by-Step Beginner-Friendly Setup Guide
- Set Up Monitoring:
- Install Prometheus:
wget https://github.com/prometheus/prometheus/releases/download/v2.47.0/prometheus-2.47.0.linux-amd64.tar.gz
tar xvfz prometheus-2.47.0.linux-amd64.tar.gz
cd prometheus-2.47.0.linux-amd64
./prometheus --config.file=prometheus.ymlConfigure alerts in prometheus.yml to monitor SLOs.
2. Configure PagerDuty:
- Create a PagerDuty account and add an escalation policy.
- Integrate with Prometheus:
curl -X POST https://events.pagerduty.com/v2/enqueue \
-H "Content-Type: application/json" \
-d '{"event_action":"trigger","payload":{"summary":"High latency detected","severity":"critical","source":"Prometheus"}}'3. Create a Runbook:
- Document a sample runbook in Markdown:
# Database Outage Runbook
## Symptoms
- High latency (>500ms) on database queries.
## Steps
1. Check database logs: `tail -f /var/log/mysql.log`
2. Restart database: `sudo systemctl restart mysql`
3. Escalate to DBA if unresolved.4. Set Up Communication Channels:
- Create a dedicated Slack channel (
#incident-response). - Configure Slack notifications from PagerDuty.
5. Train the IC:
- Simulate an incident using a tabletop exercise.
- Assign an IC to coordinate and document actions.
Real-World Use Cases
Scenario 1: E-commerce Platform Outage
- Context: During a peak sales event, an e-commerce platform’s payment gateway fails due to a faulty code deployment.
- IC Role: The IC declares a SEV-0 incident, assigns an Operations Lead to roll back the deployment, and a Communications Lead to update customers via status pages. The IC coordinates with the development team to patch the issue, resolving it in 15 minutes, saving millions in revenue.
Scenario 2: Social Media DDoS Attack
- Context: A social media platform faces a DDoS attack, overwhelming DNS servers.
- IC Role: The IC activates the DDoS runbook, assigns security SREs to scrub malicious traffic, and coordinates with cloud engineers to reroute traffic. The IC ensures regular stakeholder updates, restoring service in hours.
Scenario 3: Healthcare System Data Breach
- Context: A healthcare application detects unauthorized access to patient data.
- IC Role: The IC declares a SEV-0 incident, isolates affected systems, and assigns a security SME to investigate. The Communications Lead notifies compliance teams, ensuring regulatory adherence. The IC drives a postmortem to enhance security measures.
Industry-Specific Example: Finance
In financial services, where downtime can cost millions per minute, the IC ensures rapid response to trading platform outages by coordinating with quants, developers, and compliance teams to meet stringent regulatory requirements.
Benefits & Limitations
Key Advantages
- Rapid Response: The IC’s centralized coordination reduces MTTR.
- Clear Accountability: Defined roles prevent confusion during incidents.
- Improved Communication: Ensures stakeholders receive timely, accurate updates.
- Learning Culture: Blameless postmortems drive system improvements.
Common Challenges or Limitations
- Role Overload: The IC may be overwhelmed in large-scale incidents without proper delegation.
- Training Needs: Requires regular training to maintain effectiveness.
- Dependency on Tools: Relies on robust monitoring and communication tools, which may fail.
- Cultural Resistance: Teams may resist structured processes in fast-paced environments.
Best Practices & Recommendations
Security Tips
- Access Control: Restrict IC access to critical systems to prevent misuse.
- Audit Trails: Log all IC actions in tools like PagerDuty for accountability.
- Encryption: Use encrypted communication channels (e.g., Slack with enterprise security).
Performance
- Prioritize SLO-Based Alerts: Focus on user-facing symptoms to reduce noise.
- Automate Routine Tasks: Use tools like Ansible for automated rollbacks.
- Regular Drills: Conduct “Wheel of Misfortune” exercises to keep IC skills sharp.
Maintenance
- Update Runbooks: Regularly revise runbooks to reflect system changes.
- Monitor Tool Health: Ensure monitoring tools are operational to avoid blind spots.
Compliance Alignment
- Align with standards like GDPR or HIPAA by documenting IC actions and involving compliance teams during incidents.
Automation Ideas
- Auto-Declare Incidents: Use AI-driven anomaly detection to trigger incidents.
- Automated Runbooks: Integrate runbooks with CI/CD pipelines for automated mitigations.
Comparison with Alternatives
| Aspect | Incident Commander (IC) | Ad-Hoc Response | DevOps On-Call |
|---|---|---|---|
| Structure | Highly structured with defined roles | Informal, chaotic | Semi-structured |
| Coordination | Centralized via IC | No clear leader | Team-based |
| Scalability | Scales for large incidents | Poor for complex systems | Moderate |
| Speed | Fast due to clear roles | Slow due to confusion | Variable |
| Tool Integration | Strong (PagerDuty, Slack) | Limited | Moderate |
| Learning | Blameless postmortems | Inconsistent | Variable |
When to Choose Incident Commander
- Choose IC: For large-scale, complex systems requiring coordinated responses across multiple teams.
- Choose Alternatives: For small teams with simple systems where ad-hoc responses suffice.
Conclusion
The Incident Commander role is a cornerstone of effective SRE incident management, ensuring rapid, coordinated responses to outages while fostering a culture of continuous improvement. As systems grow in complexity, the IC’s role will evolve with advancements in AI-driven automation and predictive analytics. To get started, train your team, integrate robust tools, and practice regularly.
- Official Docs: Google SRE Book (https://sre.google/sre-book/table-of-contents/)[](https://sre.google/workbook/index/)
- Communities: Join SRE communities on Slack (e.g., SREcon) or Reddit for peer insights.