Introduction & Overview
In Site Reliability Engineering (SRE), ensuring system reliability and continuous improvement is paramount. A Blameless Postmortem is a structured, collaborative process to analyze incidents without pointing fingers, fostering a culture of learning and system improvement. This tutorial provides an in-depth exploration of blameless postmortems, detailing their role in SRE, architecture, implementation, and practical applications. Designed for technical readers, it includes theoretical explanations, practical guides, and visual aids to ensure a thorough understanding.
- Purpose: Equip SREs, DevOps engineers, and IT professionals with the knowledge to implement blameless postmortems effectively.
- Scope: Covers concepts, setup, real-world applications, and best practices with a focus on actionable insights.
- Audience: Engineers, SREs, and managers seeking to enhance incident management and system reliability.
What is a Blameless Postmortem?
Definition
A blameless postmortem is a retrospective analysis conducted after a significant system incident (e.g., outage, data loss) to understand what happened, why it happened, and how to prevent recurrence, without attributing fault to individuals. It emphasizes systemic issues and process improvements, fostering psychological safety and open communication.
History or Background
The concept of postmortems originated in medical and aviation fields, where analyzing failures without blame improved safety. In software engineering, John Allspaw’s 2012 article, “Blameless Postmortems and a Just Culture,” popularized the approach in tech, with companies like Google, Etsy, and Atlassian adopting it as a cornerstone of SRE.
- Evolution: From blame-oriented “witch hunts” to collaborative learning exercises.
- Adoption: Tech giants like Google institutionalized blameless postmortems to enhance system resilience and team morale.
Why is it Relevant in Site Reliability Engineering?
SRE balances operational reliability with rapid development, and blameless postmortems are critical for:
- Learning from Failures: Identifying systemic weaknesses to prevent recurring incidents.
- Cultural Impact: Encouraging transparency and reducing fear of reprisal, which boosts team collaboration.
- System Resilience: Driving actionable improvements to infrastructure and processes, aligning with SRE goals of high availability and low toil.
- Customer Trust: Transparent postmortems (when shared externally) enhance customer confidence, as practiced by Google Cloud.
Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| Blameless Postmortem | A review process post-incident focusing on system/process issues, not individual fault. |
| Root Cause Analysis (RCA) | A method to identify underlying causes of an incident, e.g., using 5 Whys or Fishbone Diagrams. |
| Incident Timeline | A chronological record of events during an incident, used to reconstruct what happened. |
| Action Items | Specific, measurable tasks assigned post-incident to prevent recurrence. |
| Psychological Safety | An environment where team members feel safe to share mistakes without fear of blame. |
| Service Level Objective (SLO) | A target metric for system reliability, often used to trigger postmortems if breached. |
How It Fits into the SRE Lifecycle
Blameless postmortems integrate across the SRE lifecycle:
- Design Phase: Premortems (pre-incident analysis) anticipate risks, complementing postmortems.
- Monitoring & Incident Response: Postmortems rely on data from observability tools (e.g., Prometheus, New Relic) to analyze incidents.
- Post-Incident Analysis: Central to learning and reducing Mean Time to Recovery (MTTR).
- Continuous Improvement: Action items from postmortems feed into system updates, automation, and process refinement.
Architecture & How It Works
Components
A blameless postmortem process comprises:
- Incident Data: Logs, metrics, and monitoring data (e.g., from Prometheus, Grafana).
- Stakeholders: Incident responders, engineers, managers, and subject matter experts (SMEs).
- Timeline: A detailed sequence of events, often visualized with graphs or charts.
- Root Cause Analysis Tools: Techniques like 5 Whys, Fishbone Diagrams, or Fault Tree Analysis.
- Collaboration Platform: Tools like Google Docs, Confluence, or PagerDuty for real-time collaboration.
Internal Workflow
- Incident Detection: An incident (e.g., outage) triggers a postmortem based on predefined criteria (e.g., SLO breach, user impact).
- Data Collection: Gather logs, metrics, and stakeholder input. Observability tools provide real-time and historical data.
- Timeline Creation: Document events chronologically, including actions taken and their impact.
- Root Cause Analysis: Use structured methods to identify systemic issues, avoiding blameful language.
- Action Items: Define specific, measurable tasks with owners and deadlines.
- Review & Sharing: Share the postmortem internally (or externally for transparency) and archive it in a repository.
- Follow-Up: Track action item progress to ensure implementation.
Architecture Diagram Description
Below is a textual representation of a blameless postmortem architecture, as images cannot be generated:
Diagram Components:
- Incident Trigger: An SLO breach or outage detected via monitoring tools (e.g., Prometheus, Grafana).
- Data Sources: Logs, metrics, and stakeholder interviews feed into a central repository.
- Collaboration Platform: Tools like Google Docs or Confluence host the postmortem document.
- Analysis Tools: RCA methods (5 Whys, Fishbone) process data to identify causes.
- Action Item Tracker: A system (e.g., Jira, Trello) tracks tasks and their progress.
- Output: Postmortem report shared via internal mailing lists or external blogs.
Flow:
[Incident] --> [Monitoring Tools] --> [Data Collection] --> [Collaboration Platform]
| |
v v
[Timeline Creation] --> [RCA Analysis] --> [Action Items] --> [Review & Share]
| |
v v
[Archive Repository] <-- [Follow-Up in Task Tracker]
Integration Points with CI/CD or Cloud Tools
- CI/CD: Postmortems may identify pipeline issues (e.g., faulty deployments), leading to automated testing or canarying improvements.
- Cloud Tools:
Installation & Getting Started
Basic Setup or Prerequisites
- Tools Needed:
- Observability: Prometheus, Grafana, or New Relic for metrics and logs.
- Collaboration: Google Docs, Confluence, or PagerDuty Postmortem Toolkit.
- Task Management: Jira, Trello, or Asana for action item tracking.
- Team Setup: Assemble a diverse team (SREs, developers, managers) with clear roles (e.g., scribe, incident commander).
- Cultural Prerequisites: Leadership buy-in to enforce blamelessness and psychological safety.
Hands-On: Step-by-Step Beginner-Friendly Setup Guide
- Define Postmortem Criteria:
- Set triggers (e.g., outages > 30 minutes, SLO breaches).
- Example:
if user-facing downtime > 30 min or revenue loss > $10K, initiate postmortem.
- Set Up Tools:
- Install Prometheus for monitoring:
# Install Prometheus on a Linux server
wget https://github.com/prometheus/prometheus/releases/download/v2.47.0/prometheus-2.47.0.linux-amd64.tar.gz
tar -xzf prometheus-2.47.0.linux-amd64.tar.gz
cd prometheus-2.47.0.linux-amd64
./prometheus --config.file=prometheus.ymlConfigure Grafana for visualization:
# Install Grafana
sudo apt-get install -y grafana
sudo systemctl start grafana-serverUse a Google Doc template (e.g., Google’s postmortem template).
3. Conduct the Postmortem:
- Gather stakeholders in a meeting.
- Use a template:
# Postmortem: [Incident Name]
## Incident Summary
[Brief description]
## Timeline
| Time | Event |
|------|-------|
| [Time] | [Event] |
## Root Cause
[Explanation]
## Action Items
| Owner | Task | Due Date |
|-------|------|----------|
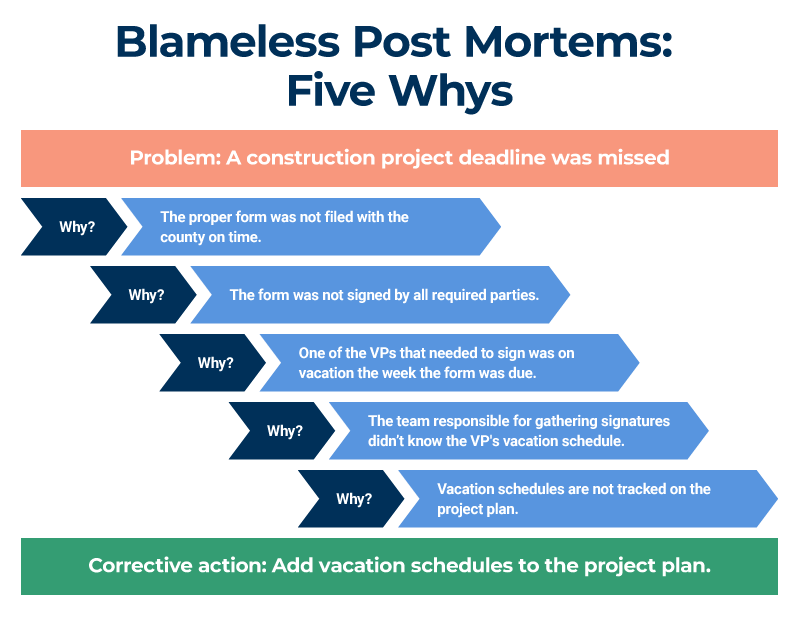
| [Name] | [Task] | [Date] |- Perform RCA using the 5 Whys:
Problem: Service outage occurred.
Why? Deployment introduced a bug.
Why? No pre-deployment validation.
Why? Lack of automated testing.
Why? Testing framework not prioritized.
Why? Resource constraints in sprint planning.
Action: Implement automated testing in CI/CD.4. Share and Archive:
- Share via internal mailing list or Confluence.
- Archive in a repository (e.g., GitHub repo with markdown files).
5. Track Action Items:
- Create Jira tickets:
# Example Jira CLI command
jira create -t Task -p MYPROJECT --summary "Implement automated testing" --description "From postmortem [ID]"Real-World Use Cases
Scenario 1: E-Commerce Platform Outage
- Context: A retail website crashed during a Black Friday sale due to a database overload.
- Postmortem:
- Timeline: Traffic spiked 10x, database queries timed out.
- Root Cause: Insufficient database scaling and no rate-limiting.
- Action Items: Implement auto-scaling, add rate-limiting middleware.
- Outcome: Reduced future downtime by 50%.
Scenario 2: Cloud Service Disruption (Google Cloud Example)
- Context: A Google Compute Engine outage dropped inbound traffic for 45 minutes.
- Postmortem:
- Timeline: Misconfigured firewall rules blocked traffic.
- Root Cause: Lack of automated configuration validation.
- Action Items: Add pre-deployment checks, automate rollback.
- Outcome: Enhanced configuration-as-code practices, preventing recurrence.
Scenario 3: Streaming Service Latency
- Context: A video streaming platform experienced buffering due to a resource leak.
- Postmortem:
- Outcome: Improved user experience and system stability.
Industry-Specific Example: Healthcare
- Context: A hospital’s patient management system failed, delaying critical updates.
- Postmortem:
- Outcome: Ensured compliance with healthcare reliability standards.
Benefits & Limitations
Key Advantages
- Improved Reliability: Systemic fixes reduce MTTR by up to 30%.
- Cultural Benefits: Fosters trust, transparency, and collaboration.
- Proactive Learning: Prevents recurrence through actionable insights.
- Customer Trust: External postmortems (e.g., Google Cloud) enhance transparency.
Common Challenges or Limitations
| Challenge | Description |
|---|---|
| Time Constraints | Postmortems require significant time, competing with other priorities. |
| Cultural Resistance | Shifting from blame to blamelessness can face pushback. |
| Poor Documentation | Incomplete data can hinder analysis. |
| Cognitive Bias | Human tendency to blame can undermine blamelessness. |
Best Practices & Recommendations
Security Tips
- Anonymize Data: Avoid including sensitive customer or system names in external postmortems.
- Access Control: Restrict postmortem documents to authorized personnel during drafting.
Performance
- Real-Time Data: Use observability tools for accurate, real-time incident data.
- Concise Reports: Focus on relevant details, moving supplementary data to appendices.
Maintenance
- Regular Reviews: Schedule monthly postmortem reviews to ensure action items are completed.
- Central Repository: Archive postmortems in a searchable database (e.g., GitHub, Confluence).
Compliance Alignment
- Align with standards like ISO 27001 or HIPAA by documenting incident responses and fixes.
- Use blameless postmortems to demonstrate proactive risk management during audits.
Automation Ideas
- Automated Templates: Use scripts to populate postmortem templates with monitoring data.
# Python script to generate postmortem template
import datetime
template = f"""
# Postmortem: {datetime.datetime.now().strftime('%Y-%m-%d')}
## Incident Summary
[Describe incident]
## Timeline
| Time | Event |
|------|-------|
| {datetime.datetime.now().strftime('%H:%M')} | [Event] |
"""
with open("postmortem.md", "w") as f:
f.write(template)Comparison with Alternatives
| Approach | Blameless Postmortem | Traditional Postmortem | No Postmortem |
|---|---|---|---|
| Focus | Systemic issues, process improvement | Often blames individuals | No analysis, no learning |
| Cultural Impact | Fosters trust, transparency | Can create fear, risk-aversion | Missed opportunities for improvement |
| Effectiveness | Prevents recurrence (40% reduction in incidents) | Limited by defensive behavior | High risk of recurring issues |
| Tool Support | Integrates with observability, CI/CD tools | May use similar tools but less collaboratively | None |
| When to Choose | Complex systems, high-reliability needs | Small teams with low incident volume | Not recommended |
When to Choose Blameless Postmortems:
- Ideal for SRE-driven organizations with complex, distributed systems.
- Best for fostering a learning culture and ensuring compliance with reliability standards.
Conclusion
Blameless postmortems are a cornerstone of SRE, transforming incidents into opportunities for growth and resilience. By focusing on systems rather than individuals, they foster trust, improve reliability, and align with SRE’s goal of balancing innovation with stability. As organizations increasingly adopt cloud-native and distributed architectures, blameless postmortems will remain critical for managing complexity.
Future Trends
- AI-Driven Postmortems: Tools like New Relic’s Incident Intelligence may automate RCA and timeline creation.
- Chaos Engineering: Integrating postmortems with chaos experiments to proactively identify weaknesses.
- Global Collaboration: Increased use of real-time collaboration tools for distributed teams.
Next Steps
- Start with a simple postmortem template and pilot it on a recent incident.
- Train teams on blameless language and RCA techniques.
- Explore tools like PagerDuty or New Relic for streamlined workflows.