Introduction & Overview
What is a Load Balancer?
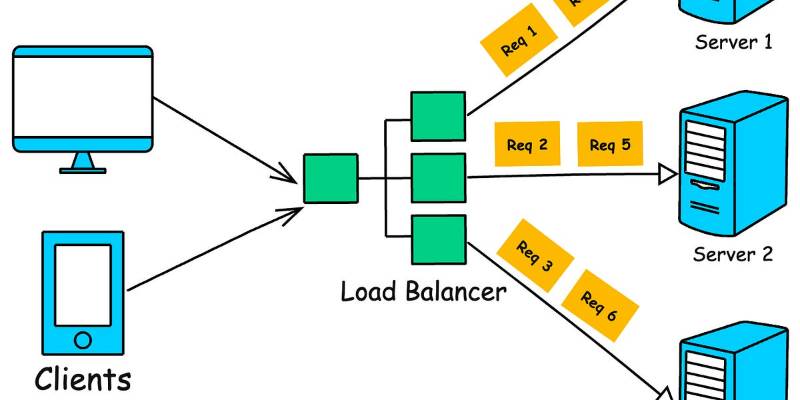
A load balancer is a critical component in distributed systems that evenly distributes incoming network traffic across multiple backend servers to ensure high availability, reliability, and performance. Acting as a reverse proxy, it directs client requests to the most appropriate server based on predefined algorithms, preventing any single server from becoming overwhelmed. Load balancers are essential for scaling applications, managing traffic surges, and maintaining uptime in modern infrastructures.
History or Background
Load balancing has evolved significantly since the 1990s:
- Early Days (1990s): Simple DNS round-robin techniques distributed traffic across servers but lacked dynamic routing capabilities.
- Hardware Era (2000s): Dedicated appliances like F5 BIG-IP and Citrix NetScaler offered robust load balancing with high performance.
- Cloud and Software Era (2010s–Present): The rise of cloud computing and containerization led to software-based solutions like NGINX, HAProxy, and cloud-native load balancers (e.g., AWS Elastic Load Balancer, Google Cloud Load Balancing). These solutions provide flexibility, scalability, and integration with modern microservices architectures.
Why is it Relevant in Site Reliability Engineering?
In Site Reliability Engineering (SRE), load balancers are pivotal for achieving scalability, reliability, and performance—core tenets of SRE. They help:
- Ensure High Availability: Distribute traffic to healthy servers, minimizing downtime.
- Enable Scalability: Support horizontal scaling by adding or removing servers dynamically.
- Optimize Performance: Reduce latency by routing requests to the least-loaded or geographically closest servers.
- Enhance Fault Tolerance: Redirect traffic away from failed servers, maintaining service continuity.
SRE teams rely on load balancers to meet Service Level Objectives (SLOs) and maintain robust, user-facing systems under varying workloads.
Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| Load Balancer | A device or software that distributes network traffic across multiple servers. |
| Backend Servers | Servers in the pool that process client requests forwarded by the load balancer. |
| Load Balancing Algorithm | Rules determining how traffic is distributed (e.g., Round Robin, Least Connections). |
| Health Checks | Periodic tests to verify server availability and performance. |
| Session Persistence | Ensures repeated client requests go to the same server for consistent experiences. |
| SSL/TLS Termination | Decrypting encrypted traffic at the load balancer to offload backend servers. |
| Virtual IP (VIP) | A single IP address clients use to access the load balancer. |
How it Fits into the Site Reliability Engineering Lifecycle
Load balancers align with SRE principles across the system lifecycle:
- Design: Incorporated into architecture to ensure scalability and fault tolerance.
- Deployment: Integrated with CI/CD pipelines for seamless updates (e.g., blue-green deployments).
- Monitoring: Health checks and metrics (e.g., latency, error rates) feed into SRE observability tools.
- Incident Response: Redirect traffic during failures to maintain SLOs.
- Capacity Planning: Enable dynamic scaling to handle traffic spikes.
Architecture & How It Works
Components
- Listener: Captures incoming client requests (e.g., HTTP, TCP).
- Rule Engine: Applies load balancing algorithms to route traffic.
- Health Checker: Monitors backend server health, removing unhealthy servers from the pool.
- Backend Pool: Group of servers handling requests.
- Session Persistence Module: Maintains consistent server assignments for stateful applications.
- SSL/TLS Module: Manages encryption/decryption for secure traffic.
Internal Workflow
- Client Request: A client sends a request to the load balancer’s Virtual IP (VIP).
- Algorithm Application: The load balancer evaluates the request using an algorithm (e.g., Round Robin, Least Connections) and health check data.
- Traffic Forwarding: The request is routed to a healthy backend server.
- Response Handling: The server processes the request and sends the response back through the load balancer to the client.
Architecture Diagram Description
The architecture consists of:
- Clients: Users or devices sending HTTP/TCP requests.
- Load Balancer: A single entry point (VIP) distributing traffic.
- Backend Servers: Multiple servers (e.g., running NGINX or application code) processing requests.
- Database/Cache Layer: Optional backend storage for data persistence.
[Clients] ----> [Load Balancer (VIP)] ----> [Backend Server 1]
----> [Backend Server 2]
----> [Backend Server 3]
----> [Database/Cache]
The load balancer sits between clients and servers, using health checks to monitor server status and routing traffic accordingly.
Integration Points with CI/CD or Cloud Tools
- CI/CD: Load balancers support zero-downtime deployments (e.g., blue-green or canary releases) by rerouting traffic during updates.
- Cloud Tools:
- AWS: Elastic Load Balancer (ELB) integrates with Auto Scaling groups.
- Google Cloud: Cloud Load Balancing works with Compute Engine and Kubernetes.
- Azure: Azure Load Balancer integrates with Virtual Machine Scale Sets.
- Monitoring: Tools like Prometheus and Grafana collect metrics from load balancers for observability.
Installation & Getting Started
Basic Setup or Prerequisites
- Hardware/Software Requirements:
- Server or cloud instance (e.g., Ubuntu 20.04, 2 vCPUs, 4GB RAM).
- Administrative access (root or sudo).
- Basic networking knowledge (e.g., DNS, IP configuration).
- Dependencies: Install
nginxorhaproxyfor software load balancing. - Network Setup: Ensure firewall rules allow traffic on ports 80 (HTTP) or 443 (HTTPS).
Hands-on: Step-by-Step Beginner-Friendly Setup Guide
This guide sets up a basic NGINX load balancer on Ubuntu 20.04.
- Install NGINX:
sudo apt update
sudo apt install nginx -y2. Configure Backend Servers:
Ensure at least two backend servers are running a web application (e.g., Node.js app on ports 3000 and 3001).
3. Edit NGINX Configuration:
Modify /etc/nginx/nginx.conf to include an upstream block and proxy settings:
http {
upstream backend {
server 192.168.1.101:3000; # Backend Server 1
server 192.168.1.102:3001; # Backend Server 2
}
server {
listen 80;
server_name example.com;
location / {
proxy_pass http://backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
}4. Validate Configuration:
sudo nginx -t5. Restart NGINX:
sudo systemctl restart nginx6. Test the Setup:
Access http://<load-balancer-ip> in a browser. Requests should alternate between backend servers.
Real-World Use Cases
- E-commerce Platform:
- Scenario: An online retailer experiences traffic spikes during sales events.
- Application: AWS ELB distributes traffic across multiple EC2 instances, with auto-scaling to handle surges. Health checks ensure only healthy instances receive traffic.
- Outcome: Reduced latency, zero downtime, and maintained SLOs during peak traffic.
- Microservices Architecture:
- Scenario: A streaming service uses microservices for user authentication, content delivery, and payment processing.
- Application: NGINX load balancers sit in front of each service, routing requests based on URL patterns (Layer 7). Session persistence ensures consistent user experiences.
- Outcome: Independent scaling of services, improved reliability.
- Global Content Delivery:
- Scenario: A news website serves users worldwide.
- Application: Google Cloud Load Balancing uses IP Hash to route users to the nearest data center, reducing latency. DNS-based global load balancing ensures fault tolerance across regions.
- Outcome: Faster content delivery, high availability.
- Database Replication:
- Scenario: A financial application uses a master-slave database setup.
- Application: HAProxy routes write requests to the master and read requests to slaves, optimizing database performance.
- Outcome: Balanced load, improved query response times.
Benefits & Limitations
Key Advantages
- Scalability: Enables horizontal scaling by distributing traffic across multiple servers.
- High Availability: Redirects traffic from failed servers, minimizing downtime.
- Performance Optimization: Reduces latency through intelligent routing (e.g., Least Connections).
- Security: Supports SSL/TLS termination and DDoS protection.
Common Challenges or Limitations
- Single Point of Failure: The load balancer itself can fail unless configured in a high-availability setup.
- Configuration Complexity: Advanced setups (e.g., Layer 7 routing) require expertise.
- Overhead: SSL termination and health checks add processing latency.
- Cost: Hardware load balancers and cloud-native solutions can be expensive.
Best Practices & Recommendations
Security Tips
- Enable SSL/TLS termination to secure traffic.
- Implement Web Application Firewalls (WAF) to protect against attacks.
- Restrict backend server access to only the load balancer’s IP range.
Performance
- Use Least Connections or Weighted Round Robin for uneven server capacities.
- Enable caching at the load balancer (e.g., NGINX caching) to reduce backend load.
- Optimize health check intervals to balance monitoring and overhead.
Maintenance
- Monitor metrics like request latency, error rates, and server health using tools like Prometheus.
- Regularly update load balancer software to patch vulnerabilities.
- Automate scaling with cloud provider APIs (e.g., AWS Auto Scaling).
Compliance Alignment
- Ensure logging complies with regulations (e.g., GDPR for user data).
- Use encrypted connections to meet compliance standards (e.g., PCI DSS).
Automation Ideas
- Integrate with Terraform or Ansible for automated configuration.
- Use CI/CD pipelines to update backend servers without downtime.
Comparison with Alternatives
| Feature/Aspect | Load Balancer (e.g., NGINX, AWS ELB) | API Gateway | DNS Round-Robin |
|---|---|---|---|
| Layer | Layer 4 or 7 | Layer 7 | Layer 3 |
| Routing Flexibility | High (content-based, URL patterns) | Very High | Low |
| Health Checks | Yes | Limited | No |
| Scalability | Horizontal scaling | Service-specific | Basic |
| Use Case | General traffic distribution | Microservices API | Simple distribution |
When to Choose a Load Balancer
- Load Balancer: Ideal for general traffic distribution, high availability, and horizontal scaling in web applications or microservices.
- API Gateway: Better for managing APIs, authentication, and rate limiting in microservices.
- DNS Round-Robin: Suitable for simple, low-cost setups without dynamic routing needs.
Conclusion
Load balancers are indispensable in SRE for building scalable, reliable, and performant systems. They enable horizontal scaling, ensure high availability, and optimize resource utilization, aligning with SRE goals of minimizing toil and meeting SLOs. As cloud-native and containerized environments grow, load balancers will evolve with AI-driven routing and tighter integration with orchestration tools like Kubernetes.
Next Steps
- Explore advanced configurations like Layer 7 routing or global load balancing.
- Experiment with cloud-native solutions (e.g., AWS ELB, Google Cloud Load Balancing).
- Monitor load balancer metrics to optimize performance and reliability.
Resources
- Official Docs:
- NGINX Documentation
- HAProxy Documentation
- AWS Elastic Load Balancing
- Communities:
- NGINX Community
- SRE Reddit
- Stack Overflow