Introduction & Overview
What is DNS Failover?
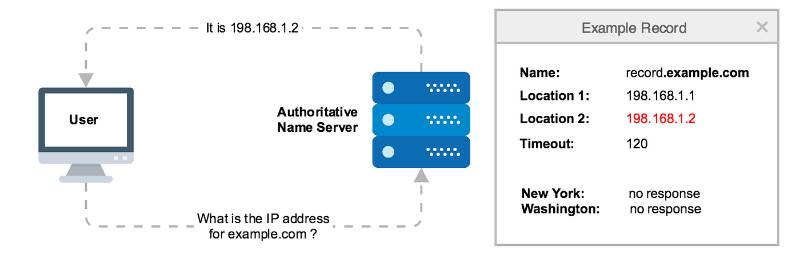
DNS Failover is an automated mechanism that redirects network traffic from a failed or unreachable server to a healthy, operational server using the Domain Name System (DNS). It ensures high availability and minimal downtime by rerouting user requests when a primary server experiences issues like hardware failures, network outages, or cyberattacks such as Distributed Denial of Service (DDoS) attacks. In essence, DNS Failover acts as a critical component of disaster recovery and business continuity strategies, maintaining service availability for users.
History or Background
DNS Failover emerged as a response to the growing need for reliable internet services in the late 1990s and early 2000s. As businesses increasingly relied on online platforms, downtime became costly, prompting the development of redundancy mechanisms. The introduction of Anycast DNS and multi-provider setups further enhanced failover capabilities, allowing traffic to be rerouted seamlessly across geographically distributed servers. Today, DNS Failover is a standard practice for ensuring resilience in modern cloud-based and distributed systems, supported by providers like AWS Route 53, Cloudflare, and IBM NS1 Connect.
Why is it Relevant in Site Reliability Engineering?
Site Reliability Engineering (SRE) focuses on ensuring systems are scalable, reliable, and efficient. DNS Failover aligns with SRE principles by:
- Enhancing Reliability: Minimizes downtime, aligning with SRE’s goal of meeting Service Level Objectives (SLOs).
- Automating Recovery: Reduces manual intervention, a core SRE practice for operational efficiency.
- Supporting Scalability: Works with distributed systems and microservices, common in modern SRE architectures.
- Mitigating Risks: Protects against outages and cyberattacks, ensuring business continuity.
Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| DNS Failover | A mechanism that redirects traffic to a backup server when the primary server fails. |
| Authoritative DNS | DNS servers that hold the definitive records for a domain, responding to queries with IP addresses. |
| Secondary DNS | A read-only DNS server that syncs with the primary for redundancy. |
| Anycast DNS | A routing technique where multiple servers share the same IP address, allowing automatic traffic redirection to the nearest healthy server. |
| Time-to-Live (TTL) | The duration a DNS record is cached, impacting how quickly failover occurs. |
| Health Checks | Automated monitoring to detect server availability and performance issues. |
| Recovery Time Objective (RTO) | The maximum acceptable downtime before recovery. |
| Recovery Point Objective (RPO) | The maximum acceptable data loss during failover. |
How it Fits into the Site Reliability Engineering Lifecycle
DNS Failover integrates into the SRE lifecycle as follows:
- Design: Incorporate redundancy and failover in system architecture for high availability.
- Implementation: Configure DNS providers and health checks to automate failover.
- Monitoring: Continuously monitor DNS performance and server health to trigger failover when needed.
- Incident Response: Use failover to minimize downtime during outages, aligning with error budget goals.
- Postmortems: Analyze failover events to improve configurations and reduce future risks.
Architecture & How It Works
Components
- Primary DNS Server: Holds the authoritative DNS records for a domain.
- Secondary DNS Server(s): Mirrors the primary server’s records for redundancy.
- Health Monitoring System: Checks server availability and performance (e.g., HTTP response, ping).
- Load Balancer/Traffic Manager: Routes traffic to healthy servers based on DNS responses.
- DNS Provider: Hosts DNS records and supports failover configurations (e.g., AWS Route 53, Cloudflare).
Internal Workflow
- A user queries a domain (e.g., example.com) via their browser.
- The DNS resolver queries the authoritative DNS server.
- Health checks monitor the primary server’s status.
- If the primary server fails, the DNS provider updates the DNS record to point to a backup server’s IP.
- Traffic is rerouted to the backup server, ensuring continuity.
- Once the primary server is restored, traffic can revert (optional, based on configuration).
Architecture Diagram Description
The architecture consists of:
- Client: Initiates DNS queries.
- DNS Resolver: Queries the authoritative DNS server.
- Primary and Secondary DNS Servers: Hosted in different regions or data centers.
- Health Monitoring System: Continuously pings servers and updates DNS records.
- Load Balancer: Distributes traffic to healthy servers.
- Cloud Provider Integration: Syncs with tools like AWS Route 53 or Google Cloud DNS.
Diagram Layout:
[Client] --> [DNS Resolver] --> [Authoritative DNS Server]
|
v
[Health Monitoring] <--> [Primary Server | Secondary Server]
|
v
[Load Balancer] --> [Healthy Server Instance]
Integration Points with CI/CD or Cloud Tools
- CI/CD Pipelines: Automate DNS record updates using Infrastructure as Code (IaC) tools like Terraform or AWS CloudFormation.
- Cloud Tools: Integrate with AWS Route 53 health checks, Google Cloud DNS policies, or Cloudflare’s traffic steering for automated failover.
- Monitoring Tools: Use Prometheus or Datadog to monitor server health and trigger failover via API calls.
Installation & Getting Started
Basic Setup or Prerequisites
- A registered domain with a DNS provider (e.g., AWS Route 53, Cloudflare).
- At least two servers (primary and backup) in different regions or data centers.
- A health monitoring tool or service (e.g., AWS Route 53 Health Checks, Pingdom).
- Access to DNS provider’s management console or API.
- Basic knowledge of DNS records (A, CNAME) and TTL settings.
Hands-on: Step-by-Step Beginner-Friendly Setup Guide
This guide uses AWS Route 53 for DNS Failover configuration.
- Create a Hosted Zone in Route 53:
- Log in to the AWS Management Console.
- Navigate to Route 53 > Hosted Zones > Create Hosted Zone.
- Enter your domain (e.g., example.com) and select “Public Hosted Zone.”
- Set Up Health Checks:
- Go to Route 53 > Health Checks > Create Health Check.
- Configure:
- Name: Primary-Server-Check
- Endpoint: Primary server IP (e.g., 192.0.2.1)
- Protocol: HTTP
- Path: /health (ensure your server has a health endpoint)
- Interval: 10 seconds
- Create a second health check for the backup server (e.g., 203.0.113.1).
- Configure DNS Records:
- In the Hosted Zone, create an A record:
- Name: www.example.com
- Type: A
- Value: Primary server IP (192.0.2.1)
- Routing Policy: Failover
- Failover Type: Primary
- Health Check: Select Primary-Server-Check
- Create a second A record for the backup server:
- Failover Type: Secondary
- Value: Backup server IP (203.0.113.1)
- Health Check: Select Secondary-Server-Check
- In the Hosted Zone, create an A record:
- Set TTL:
- Set a low TTL (e.g., 60 seconds) to ensure quick failover.
- Test the Configuration:
- Simulate a failure by stopping the primary server.
- Use
dig www.example.comorping www.example.comto verify traffic routes to the backup server.
Code Snippet (Terraform for Route 53 Failover):
resource "aws_route53_health_check" "primary" {
ip_address = "192.0.2.1"
port = 80
type = "HTTP"
resource_path = "/health"
failure_threshold = 3
request_interval = 10
}
resource "aws_route53_record" "primary" {
zone_id = aws_route53_zone.example.zone_id
name = "www.example.com"
type = "A"
ttl = 60
records = ["192.0.2.1"]
failover_routing_policy {
type = "PRIMARY"
}
health_check_id = aws_route53_health_check.primary.id
}
Real-World Use Cases
- E-commerce Platform (DDoS Attack Mitigation):
- Scenario: A global e-commerce platform faces a DDoS attack on its primary DNS server, causing downtime.
- Application: The platform uses a multi-provider DNS setup with Cloudflare as primary and AWS Route 53 as secondary. When the primary server is overwhelmed, failover redirects traffic to Route 53, maintaining access to the platform.
- Industry: Retail
- Healthcare IoT Network:
- Scenario: A healthcare organization uses IoT devices for patient monitoring, relying on DNS for connectivity. A ransomware attack compromises the primary DNS server.
- Application: A cloud-based DNS failover solution (e.g., Google Cloud DNS) switches to a backup server, ensuring uninterrupted patient monitoring.
- Industry: Healthcare
- Telecommunications Provider:
- Financial Institution (Compliance):
Benefits & Limitations
Key Advantages
- High Availability: Ensures services remain accessible during outages.
- Cost-Effectiveness: Uses existing DNS infrastructure, reducing hardware costs.
- Automated Recovery: Minimizes manual intervention via health checks and traffic rerouting.
- Scalability: Supports growing query volumes with Anycast or multi-provider setups.
Common Challenges or Limitations
| Challenge | Description |
|---|---|
| DNS Caching | Long TTL values can delay failover due to cached records. |
| Increased Complexity | Managing multiple DNS servers and health checks adds operational overhead. |
| Cost of Redundancy | Secondary servers and monitoring tools may incur additional costs. |
| False Positives | Misconfigured health checks may trigger unnecessary failovers. |
Best Practices & Recommendations
Security Tips
- Enable DNSSEC: Protect against spoofing and cache poisoning.
- Use Anycast DNS: Distribute queries across multiple servers for resilience.
- Monitor for Threats: Implement real-time threat detection to mitigate DDoS attacks.
Performance
- Set Low TTLs: Use short TTLs (e.g., 60 seconds) for faster failover.
- Leverage Load Balancers: Integrate with cloud-native load balancers like AWS ELB or Google Cloud Load Balancing.
- Optimize Health Checks: Configure frequent checks (e.g., every 10 seconds) without overwhelming servers.
Maintenance
- Regular Audits: Review DNS records to ensure accuracy.
- Automate Backups: Use IaC to back up DNS configurations.
- Test Failover: Conduct regular DR drills to validate RTO and RPO.
Compliance Alignment
- Align with standards like SOC 2 by maintaining redundant DNS setups.
- Document failover procedures for audit purposes.
Automation Ideas
- Use Terraform or AWS CloudFormation to automate DNS record updates.
- Integrate with CI/CD pipelines to deploy failover configurations during releases.
Comparison with Alternatives
| Feature | DNS Failover | Load Balancer Failover | Global Server Load Balancing (GSLB) |
|---|---|---|---|
| Mechanism | Redirects traffic via DNS records | Distributes traffic across servers | Balances traffic across global data centers |
| Cost | Low (uses existing DNS infrastructure) | Moderate (requires load balancer setup) | High (complex infrastructure) |
| Failover Speed | Dependent on TTL (seconds to minutes) | Near-instantaneous | Near-instantaneous |
| Use Case | Simple redundancy for web services | Application-level load distribution | Complex, multi-region deployments |
| Complexity | Low to moderate | Moderate | High |
When to Choose DNS Failover
- Choose DNS Failover: For cost-effective, simple redundancy with minimal infrastructure changes. Ideal for small to medium-sized applications or compliance-driven environments.
- Choose Alternatives: Use load balancers or GSLB for low-latency, complex, or application-specific failover needs.
Conclusion
DNS Failover is a cornerstone of high availability in SRE, enabling rapid recovery from outages and ensuring business continuity. Its integration with cloud tools, automation capabilities, and cost-effectiveness make it a go-to solution for many organizations. However, careful configuration of TTLs, health checks, and security measures is critical to its success. As systems grow more distributed, DNS Failover will evolve with advancements like AI-driven traffic routing and enhanced DDoS protection.
Next Steps:
- Explore your DNS provider’s failover features (e.g., AWS Route 53, Cloudflare).
- Test failover in a staging environment before production deployment.
- Join SRE communities like SREcon or r/sre on Reddit for insights.
Official Docs and Resources:
- AWS Route 53 Documentation
- Cloudflare DNS Failover
- Google Cloud DNS