Introduction & Overview
What is Failover?
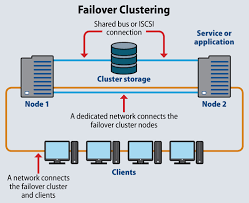
Failover is a critical mechanism in Site Reliability Engineering (SRE) that ensures system availability and continuity by automatically switching to a backup system, component, or resource when the primary one fails. It’s a cornerstone of high-availability (HA) systems, minimizing downtime and maintaining service reliability during hardware failures, software crashes, or network issues.
- Definition: Failover is the process of redirecting workloads from a failed or degraded primary system to a secondary (standby) system to ensure uninterrupted service.
- Purpose: To maintain service-level objectives (SLOs) like uptime and performance by mitigating single points of failure.
History or Background
The concept of failover originated in the early days of computing, particularly in mission-critical systems like mainframes and telecommunications. With the rise of distributed systems and cloud computing, failover mechanisms have evolved to handle complex, scalable architectures.
- Early Days: Failover was manual, requiring human intervention to switch to backup systems (e.g., database replicas).
- Modern Era: Automation, orchestration tools, and cloud-native technologies like Kubernetes and AWS have made failover seamless and programmatic.
- SRE Influence: Google’s SRE practices, formalized in the early 2000s, emphasized automation and failover to achieve “five nines” (99.999%) uptime, popularizing its adoption across industries.
Why is it Relevant in Site Reliability Engineering?
In SRE, failover is pivotal for achieving reliability, scalability, and resilience. SRE teams aim to balance operational efficiency with minimal downtime, and failover mechanisms align with these goals by:
- Ensuring Availability: Failover supports SLOs by reducing downtime during failures.
- Reducing Toil: Automated failover eliminates manual intervention, freeing SREs for strategic tasks.
- Supporting Scalability: Failover integrates with distributed systems to handle increased load or failures in cloud environments.
- Proactive Resilience: It aligns with chaos engineering principles, preparing systems for unexpected failures.
Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| Failover | Automatic or manual switch to a standby system when the primary fails. |
| High Availability (HA) | System design ensuring minimal downtime, often using failover mechanisms. |
| Active-Passive | Primary system handles traffic; passive backup activates during failure. |
| Active-Active | Multiple systems handle traffic simultaneously, redistributing on failure. |
| Service Level Objective (SLO) | Measurable target for system reliability (e.g., 99.9% uptime). |
| Redundancy | Duplication of critical components to ensure availability during failures. |
| Load Balancer | Distributes traffic across systems, often facilitating failover. |
| Chaos Engineering | Testing system resilience by intentionally introducing failures. |
How Failover Fits into the SRE Lifecycle
Failover is integral to the SRE lifecycle, which includes design, deployment, monitoring, and incident response:
- Design Phase: SREs architect systems with redundancy and failover to meet SLOs.
- Deployment: Failover mechanisms are integrated into CI/CD pipelines for seamless updates.
- Monitoring: Observability tools (e.g., Prometheus, Grafana) detect failures, triggering failover.
- Incident Response: Failover minimizes user impact during incidents, followed by postmortems to refine processes.
- Continuous Improvement: Failover strategies are updated based on failure patterns and chaos engineering tests.
Architecture & How It Works
Components and Internal Workflow
Failover systems typically include:
- Primary System: The main server or service handling user requests.
- Standby System: A replica or backup ready to take over.
- Health Check Mechanism: Monitors system health (e.g., HTTP checks, pings) to detect failures.
- Failover Controller: Logic or service (e.g., DNS, load balancer) that redirects traffic to the standby system.
- Monitoring Tools: Collect metrics, logs, and traces to trigger failover and diagnose issues.
- Data Replication: Ensures data consistency between primary and standby systems (e.g., database replication).
Workflow:
- Health Monitoring: Continuous checks verify the primary system’s status.
- Failure Detection: A failure (e.g., high latency, error rate) triggers an alert.
- Failover Trigger: The controller redirects traffic to the standby system.
- State Synchronization: The standby system assumes the primary role, using replicated data.
- Recovery: The failed system is repaired, tested, and reinstated as a standby.
Architecture Diagram
Below is a textual description of a typical failover architecture (as images cannot be generated directly):
[Users] --> [Load Balancer (e.g., AWS ELB)]
|
| (Health Checks)
v
[Primary Server (Region 1)] <--> [Data Replication (e.g., MySQL)] <--> [Standby Server (Region 2)]
|
v
[Monitoring System (Prometheus/Grafana)] --> [Alerting (PagerDuty)] --> [Failover Controller]
- Load Balancer: Distributes traffic and performs health checks.
- Primary/Standby Servers: Host the application, synchronized via replication.
- Monitoring System: Tracks metrics (latency, errors) and triggers alerts.
- Failover Controller: Updates DNS or routing to switch to the standby server.
Integration Points with CI/CD or Cloud Tools
Failover integrates with modern DevOps and cloud tools to enhance automation and resilience:
- CI/CD: Tools like Jenkins or GitHub Actions deploy updates with zero-downtime failover strategies (e.g., blue-green deployments).
- Cloud Tools:
- AWS: Elastic Load Balancer (ELB) for traffic routing, Route 53 for DNS failover.
- Azure: Traffic Manager for global failover.
- Kubernetes: Pod replication and liveness probes for container failover.
- Monitoring: Prometheus, Grafana, or Datadog provide real-time metrics to trigger failover.
Installation & Getting Started
Basic Setup or Prerequisites
To implement a basic failover setup, you’ll need:
- Infrastructure: At least two servers (primary and standby) or cloud instances (e.g., AWS EC2).
- Load Balancer: Software (e.g., HAProxy, Nginx) or cloud-based (e.g., AWS ELB).
- Monitoring Tool: Prometheus, Grafana, or a cloud-native solution like AWS CloudWatch.
- Replication Mechanism: Database replication (e.g., MySQL master-slave) or file sync.
- DNS Service: For DNS-based failover (e.g., AWS Route 53).
- Automation Tools: Ansible, Terraform, or Kubernetes for configuration.
Hands-On: Step-by-Step Beginner-Friendly Setup Guide
This guide sets up a simple failover system using Nginx as a load balancer and two web servers.
- Set Up Two Web Servers:
- Launch two EC2 instances (or local VMs) with a web server (e.g., Apache).
- Install Apache on both:
sudo apt update
sudo apt install apache2Create a simple index.html on each server:
<!-- Server 1: /var/www/html/index.html -->
<h1>Primary Server</h1>
<!-- Server 2: /var/www/html/index.html -->
<h1>Standby Server</h1>2. Install and Configure Nginx as Load Balancer:
- Install Nginx on a separate instance:
sudo apt install nginx- Configure Nginx to route traffic to the primary server and check health:
upstream backend {
server primary-server-ip:80; # Primary
server standby-server-ip:80 backup; # Standby
}
server {
listen 80;
location / {
proxy_pass http://backend;
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503 http_504;
}
}- Save to
/etc/nginx/sites-available/defaultand restart Nginx:
sudo systemctl restart nginx3. Set Up Monitoring with Prometheus:
- Install Prometheus on a monitoring server:
wget https://github.com/prometheus/prometheus/releases/download/v2.45.0/prometheus-2.45.0.linux-amd64.tar.gz
tar xvfz prometheus-2.45.0.linux-amd64.tar.gz
cd prometheus-2.45.0.linux-amd64
./prometheus --config.file=prometheus.yml- Configure
prometheus.ymlto scrape server metrics:
scrape_configs:
- job_name: 'web_servers'
static_configs:
- targets: ['primary-server-ip:80', 'standby-server-ip:80']4. Test Failover:
- Stop the primary server:
sudo systemctl stop apache2- Access the load balancer’s IP; traffic should route to the standby server, displaying “Standby Server.”
5. Validate with Monitoring:
- Check Prometheus UI (port 9090) to confirm the primary server is down and failover occurred.
Real-World Use Cases
Scenario 1: E-Commerce Platform
- Context: A retail website with high traffic during sales (e.g., Black Friday).
- Failover Application: Uses AWS ELB with Route 53 DNS failover across two regions. If the primary region fails, traffic redirects to the secondary region.
- Outcome: Maintains 99.9% uptime, ensuring customers can shop without interruption.
Scenario 2: Financial Services
- Context: An online banking platform requiring low-latency transactions.
- Failover Application: Implements active-passive database failover with MySQL replication. If the master database fails, the slave takes over within seconds.
- Outcome: Ensures 99% of transactions complete within 500ms, meeting SLOs.
Scenario 3: Streaming Service
- Context: A video streaming platform like Netflix handling millions of concurrent users.
- Failover Application: Uses active-active architecture with Kubernetes clusters across multiple zones. Pod failures trigger automatic rescheduling.
- Outcome: Minimizes buffering and maintains service availability during peak loads.
Scenario 4: Healthcare System
- Context: A hospital’s patient management system requiring 24/7 availability.
- Failover Application: Employs active-passive failover with Azure Traffic Manager to switch to a backup data center during outages.
- Outcome: Ensures critical patient data is accessible, supporting life-saving operations.
Benefits & Limitations
Key Advantages
- High Availability: Ensures systems remain operational during failures.
- Automation: Reduces manual intervention, aligning with SRE’s focus on reducing toil.
- Scalability: Supports distributed systems by redistributing workloads.
- User Experience: Maintains SLOs, minimizing disruptions for end-users.
Common Challenges or Limitations
| Challenge | Description |
|---|---|
| Complexity | Configuring failover (e.g., replication, health checks) is complex. |
| Cost | Redundant systems increase infrastructure costs. |
| Data Consistency | Asynchronous replication may cause data loss during failover. |
| False Positives | Over-sensitive health checks may trigger unnecessary failovers. |
Best Practices & Recommendations
Security Tips
- Secure Communication: Use TLS for data replication and load balancer traffic.
- Access Control: Restrict failover controller access to authorized SREs.
- Audit Logs: Monitor failover events for security incidents.
Performance
- Optimize Health Checks: Tune check intervals to balance sensitivity and resource usage.
- Load Testing: Simulate failures using chaos engineering tools (e.g., Chaos Monkey).
- Caching: Use CDNs or in-memory caches to reduce load during failover.
Maintenance
- Regular Testing: Conduct failover drills to validate configurations.
- Documentation: Maintain detailed failover runbooks for incident response.
- Postmortems: Analyze failover events to identify root causes and improve.
Compliance Alignment
- Data Regulations: Ensure failover systems comply with GDPR, HIPAA, or other standards.
- Audit Trails: Log failover events for compliance audits.
Automation Ideas
- Use Terraform for infrastructure-as-code to automate failover setup.
- Implement auto-scaling with Kubernetes or AWS Auto Scaling to handle load spikes.
- Automate alerts with PagerDuty or Opsgenie for rapid incident response.
Comparison with Alternatives
| Feature | Failover (Active-Passive/Active-Active) | Load Balancing | Auto-Scaling |
|---|---|---|---|
| Purpose | Switch to backup on failure | Distribute traffic | Adjust capacity |
| Downtime | Minimal (seconds) | None (if healthy) | None (if planned) |
| Complexity | High (replication, sync) | Moderate | Moderate |
| Cost | High (redundant systems) | Moderate | Variable |
| Use Case | Critical systems (e.g., banking) | Web apps | Variable loads |
When to Choose Failover
- Choose Failover: For mission-critical systems requiring near-zero downtime (e.g., healthcare, finance).
- Choose Alternatives: Use load balancing for performance optimization or auto-scaling for dynamic workloads.
Conclusion
Failover is a cornerstone of SRE, enabling reliable, scalable systems that meet stringent SLOs. By automating the switch to backup systems, failover minimizes downtime and enhances user experience. As systems grow more distributed and complex, failover will evolve with AI-driven monitoring and advanced chaos engineering.
Next Steps
- Explore tools like AWS Route 53, Kubernetes, or HAProxy for hands-on practice.
- Conduct chaos engineering experiments to test failover resilience.
- Join SRE communities (e.g., SREcon, Reddit’s r/sre) for knowledge sharing.