Introduction & Overview
Site Reliability Engineering (SRE) is a discipline that combines software engineering and IT operations to build and maintain reliable, scalable systems. A key component of SRE is the Error Budget Policy, which provides a structured approach to balancing system reliability with the need for innovation and rapid feature deployment. This tutorial offers a comprehensive guide to understanding and implementing an Error Budget Policy, covering its concepts, setup, real-world applications, benefits, limitations, and best practices.
What is an Error Budget Policy?
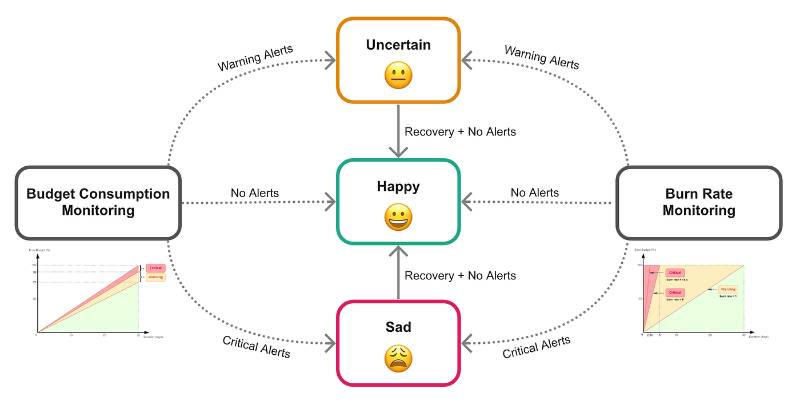
An Error Budget Policy is a formal framework that defines how an organization manages its error budget—the acceptable amount of unreliability or downtime a service can tolerate within a specific period without breaching its Service Level Objectives (SLOs). It outlines thresholds, actions, and decision-making processes to ensure a balance between innovation (new feature releases) and reliability (system stability).
- Purpose: Guides teams in prioritizing reliability improvements versus new feature development.
- Scope: Applies to SRE teams, developers, and product managers to align on reliability goals.
- Outcome: Promotes a culture of shared responsibility for system reliability while enabling controlled risk-taking.
History or Background
The concept of error budgets originated at Google in the early 2000s, pioneered by Ben Treynor, the founder of SRE. It emerged as a solution to resolve tensions between development teams (focused on velocity) and operations teams (focused on stability). By quantifying acceptable unreliability, error budgets provided a data-driven way to manage trade-offs. The approach was formalized in Google’s Site Reliability Engineering book (2016), which popularized error budgets as a cornerstone of SRE practices. Today, companies like Netflix, AWS, and Atlassian use error budgets to maintain high-availability systems.
Why is it Relevant in Site Reliability Engineering?
Error Budget Policies are critical in SRE for several reasons:
- Balancing Innovation and Stability: They allow teams to innovate rapidly without compromising user experience.
- Data-Driven Decisions: Provide objective metrics to guide release velocity and reliability investments.
- Cultural Shift: Foster collaboration between development and SRE teams by aligning goals around shared SLOs.
- Proactive Risk Management: Enable teams to address issues before they impact customers, reducing downtime and improving satisfaction.
Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| Service Level Indicator (SLI) | A quantitative measure of service performance (e.g., request latency, error rate). |
| Service Level Objective (SLO) | A target value for an SLI, representing the desired reliability level (e.g., 99.9% uptime). |
| Service Level Agreement (SLA) | A contractual agreement with customers, often tied to financial penalties, based on SLOs. |
| Error Budget | The allowable amount of unreliability (e.g., downtime or errors) derived from SLOs (e.g., 0.1% downtime for a 99.9% SLO). |
| Error Budget Policy | A documented set of rules and actions for managing error budget consumption, including thresholds and responses. |
| Burn Rate | The rate at which the error budget is consumed, often monitored in real-time. |
How It Fits into the Site Reliability Engineering Lifecycle
The Error Budget Policy integrates into the SRE lifecycle across several phases:
- Design Phase: SLOs and SLIs are defined based on user expectations and business needs.
- Development Phase: Developers use the error budget to guide release velocity and risk-taking.
- Monitoring Phase: SREs track SLIs to monitor error budget consumption and trigger policy actions.
- Incident Response Phase: Policies dictate actions like rollbacks or feature freezes when budgets are depleted.
- Postmortem Phase: Incidents are analyzed to refine SLOs and policies, fostering continuous improvement.
Architecture & How It Works
Components
An Error Budget Policy consists of the following components:
- SLI/SLO Definitions: Metrics and targets for system reliability (e.g., 99.95% uptime).
- Error Budget Calculation: Derived as
1 - SLO(e.g., 0.05% downtime for a 99.95% SLO). - Monitoring Tools: Systems like Prometheus, Grafana, or Datadog to track SLIs and burn rate.
- Policy Thresholds: Predefined levels (e.g., 50%, 75%, 90% budget consumption) that trigger actions.
- Decision Framework: Rules for who decides on actions (e.g., SREs, product managers) and what actions to take (e.g., feature freeze).
- Alerting Mechanisms: Notifications for budget consumption thresholds via tools like PagerDuty or Alertmanager.
- Runbooks: Documented procedures for responding to budget-related incidents.
Internal Workflow
- Define SLOs and SLIs: Establish measurable reliability targets based on user needs.
- Calculate Error Budget: Determine allowable downtime (e.g., 43.2 minutes/month for 99.9% SLO).
- Monitor SLIs: Use monitoring tools to track performance metrics in real-time.
- Track Consumption: Calculate burn rate and compare against policy thresholds.
- Trigger Actions: Execute predefined actions (e.g., pause deployments) when thresholds are reached.
- Review and Adjust: Conduct postmortems to refine SLOs and policies.
Architecture Diagram Description
Note: Since image generation is not possible, the diagram is described below.
The architecture diagram for an Error Budget Policy system includes:
- User Layer: End-users interacting with the service (e.g., e-commerce platform).
- Application Layer: Microservices or APIs delivering the service, monitored by SLIs.
- Monitoring Layer: Tools like Prometheus and Grafana collecting SLI data (e.g., latency, error rate).
- Alerting Layer: Alertmanager or PagerDuty sending notifications when budget thresholds are crossed.
- Policy Engine: A central logic component that evaluates SLI data against the Error Budget Policy, triggering actions like deployment freezes or rollbacks.
- CI/CD Pipeline: Integration with tools like Jenkins or GitLab to gate deployments based on policy rules.
- SRE Dashboard: Visualizes error budget consumption, burn rate, and SLO status for team visibility.
[Users] ---> [Application/Service] ---> [Monitoring System (Prometheus, Datadog)]
| |
v v
[SLI Collection] ----> [Error Budget Calculator] ---> [Policy Engine]
/ \
[CI/CD Pipeline] [Alerting]
(GitHub/Jenkins) (PagerDuty/Slack)
Flow: User requests hit the application, SLIs are collected by the monitoring layer, and the policy engine evaluates data against thresholds. Alerts are sent, and actions are triggered via the CI/CD pipeline or runbooks.
Integration Points with CI/CD or Cloud Tools
- CI/CD Pipelines: Error budget checks can be integrated as gates in GitHub Actions or GitLab CI/CD to pause deployments if the budget is nearly exhausted.
- Cloud Monitoring: AWS CloudWatch, Google Cloud Monitoring, or Azure Monitor can track SLIs and feed data to the policy engine.
- Incident Management: Tools like PagerDuty or ServiceNow integrate for alerting and incident response.
- SLO Platforms: Nobl9 or Sedai automate error budget tracking and policy enforcement.
Installation & Getting Started
Basic Setup or Prerequisites
To implement an Error Budget Policy, you need:
- Monitoring Tools: Prometheus, Grafana, or Datadog for SLI tracking.
- CI/CD Pipeline: Jenkins, GitLab, or GitHub Actions for deployment gating.
- Alerting System: PagerDuty or Alertmanager for notifications.
- SLO Definitions: Clearly defined SLIs and SLOs based on service requirements.
- Team Agreement: Stakeholder buy-in from SRE, development, and product teams.
- Infrastructure: A Kubernetes cluster or cloud environment (e.g., AWS, GCP) for deployment.
Hands-On: Step-by-Step Beginner-Friendly Setup Guide
Prerequisites
- Monitoring system (Prometheus/Grafana or Datadog).
- CI/CD pipeline (Jenkins, GitHub Actions, GitLab CI, ArgoCD).
- Policy enforcement logic (custom scripts or tools like Keptn, OpenSLO).
Step-by-Step Beginner Setup
- Define SLOs:
apiVersion: openslo/v1
kind: SLO
metadata:
name: api-availability
spec:
indicator:
metricSource: prometheus
query: http_requests_successful / http_requests_total
target:
timeWindow: 30d
target: 99.9
2. Configure Monitoring: Set up Prometheus alerts for error rate.
3. Connect CI/CD: Add error budget check step before deployment.
4. Create Policy Rules:
- If error budget < 30% → Alert only.
- If error budget < 10% → Block deployments.
Real-World Use Cases
Scenario 1: E-Commerce Platform
- Context: An online retailer sets an SLO of 99.9% uptime for its product catalog service.
- Application: The Error Budget Policy triggers a deployment freeze when a buggy release consumes 80% of the monthly error budget (34 minutes of downtime). The SRE team rolls back the release and conducts a postmortem to identify root causes.
- Outcome: Reduced customer impact and improved release processes.
Scenario 2: Financial Services
- Context: A banking platform requires 99.99% availability for transaction processing.
- Application: The policy enforces a “code yellow” state at 75% budget consumption, redirecting engineering resources to fix latency issues in the database layer.
- Outcome: Prevents SLA breaches and maintains customer trust.
Scenario 3: Streaming Service
- Context: A video streaming platform like Netflix uses a 99.95% SLO for content delivery.
- Application: The Error Budget Policy allows controlled risk-taking during low-traffic hours, enabling new feature rollouts while monitoring SLIs in real-time.
- Outcome: Balances innovation with minimal user disruption.
Industry-Specific Example: Healthcare
- Context: A telemedicine platform requires high reliability for video consultations.
- Application: The policy integrates with AWS CloudWatch to monitor latency SLIs. At 50% budget consumption, alerts notify SREs to optimize server performance, preventing consultation disruptions.
- Outcome: Ensures critical services remain available, complying with healthcare regulations.
Benefits & Limitations
Key Advantages
- Improved Reliability: Focuses teams on critical issues, reducing downtime.
- Data-Driven Decisions: Objective metrics guide release and reliability priorities.
- Cultural Alignment: Encourages collaboration between SRE and development teams.
- Proactive Management: Real-time monitoring prevents SLA breaches.
Common Challenges or Limitations
| Challenge | Description | Mitigation |
|---|---|---|
| Overly Strict SLOs | Unrealistic targets lead to frequent budget exhaustion. | Set achievable SLOs based on historical data. |
| Monitoring Gaps | Inadequate SLI tracking can misrepresent budget status. | Use comprehensive monitoring tools like Prometheus. |
| Team Resistance | Developers may resist deployment freezes. | Foster a culture of shared reliability responsibility. |
| Complexity | Managing policies in distributed systems can be resource-intensive. | Automate with tools like Nobl9 or Sedai. |
Best Practices & Recommendations
- Security Tips:
- Restrict access to monitoring dashboards and policy configurations to authorized personnel.
- Encrypt SLI data in transit and at rest to comply with data protection regulations.
- Performance:
- Use lightweight SLIs (e.g., error rate over total requests) to minimize monitoring overhead.
- Optimize alerting thresholds to avoid alert fatigue (e.g., set critical alerts at 90% consumption).
- Maintenance:
- Compliance Alignment:
- Align SLOs with industry standards (e.g., HIPAA for healthcare, PCI-DSS for finance).
- Document policy actions for auditability.
- Automation Ideas:
Comparison with Alternatives
| Approach | Error Budget Policy | Chaos Engineering | Traditional Monitoring |
|---|---|---|---|
| Focus | Balances innovation and reliability with SLOs. | Tests system resilience by inducing failures. | Tracks system health without policy enforcement. |
| Strengths | Data-driven, fosters collaboration, proactive. | Identifies weaknesses proactively. | Simple, widely adopted. |
| Weaknesses | Requires mature SLO culture, complex setup. | Risky if not controlled, resource-intensive. | Reactive, lacks decision framework. |
| Best Use Case | High-availability systems needing controlled innovation. | Systems requiring resilience testing. | Basic uptime monitoring. |
When to Choose Error Budget Policy:
- Use when balancing rapid feature releases with high reliability is critical.
- Ideal for organizations with mature DevOps/SRE practices and robust monitoring.
Conclusion
Error Budget Policies are a cornerstone of modern SRE, enabling organizations to manage the delicate balance between innovation and reliability. By quantifying acceptable unreliability, they empower teams to make data-driven decisions, reduce downtime, and enhance user satisfaction. As systems grow more complex, tools like Nobl9, Sedai, and Prometheus will continue to streamline error budget management, with AI-driven automation shaping future trends.
Next Steps:
- Start by defining realistic SLOs for your service.
- Experiment with open-source tools like Prometheus and Grafana for monitoring.
- Engage stakeholders to draft and adopt an Error Budget Policy.
Resources: