Introduction & Overview
Service Ownership in Site Reliability Engineering (SRE) is a critical practice that ensures teams take full responsibility for the lifecycle of a service, from development to production. It fosters accountability, enhances system reliability, and aligns technical efforts with business goals. This tutorial provides a detailed exploration of Service Ownership, tailored for technical readers, including developers, SREs, and IT professionals.
What is Service Ownership?
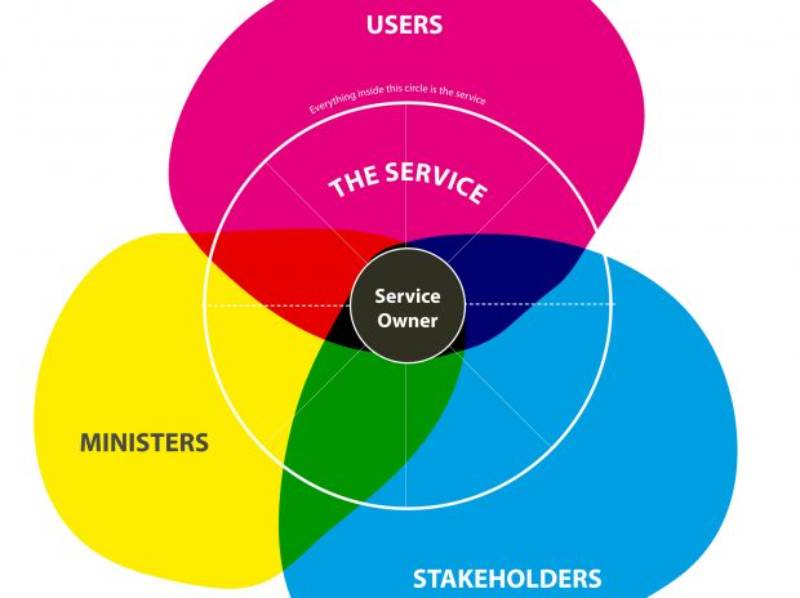
Service Ownership refers to the practice where a team, often comprising developers and SREs, takes end-to-end responsibility for a service’s design, development, deployment, monitoring, and maintenance. Unlike traditional IT models where operations and development are siloed, Service Ownership promotes shared accountability, ensuring that those who build a service also maintain its reliability in production.
History or Background
- Origin: The concept of Service Ownership emerged at Google in the early 2000s, formalized by Ben Treynor Sloss, who introduced SRE to address the challenges of managing large-scale, distributed systems. It was a response to the limitations of traditional IT operations, which struggled with scalability and rapid innovation.
- Evolution: Initially a Google-specific practice, Service Ownership has been adopted widely across industries, driven by the rise of cloud computing, microservices, and DevOps. It aligns with the DevOps philosophy but emphasizes reliability through engineering rigor.
- Modern Context: Today, Service Ownership is a cornerstone of SRE, enabling organizations to manage complex systems while maintaining high availability and performance.
- 1990s – Early Dev vs Ops divide: Developers shipped features, Operations ensured uptime. Misalignment caused bottlenecks.
- 2003 – Amazon’s “You Build It, You Run It” philosophy: Jeff Bezos mandated service teams to own APIs end-to-end.
- 2008 – Rise of DevOps: The culture of shared responsibility gained momentum.
- 2016 onwards – SRE adoption at Google & beyond: Site Reliability Engineering formalized service ownership with error budgets, SLIs, and SLOs.
Why is it Relevant in Site Reliability Engineering?
- Bridging Development and Operations: Service Ownership breaks down silos, encouraging collaboration between developers and SREs to ensure services meet reliability and performance goals.
- Accountability: Teams owning a service are incentivized to write robust code and implement proactive monitoring, reducing downtime and improving user experience.
- Scalability: By treating operations as a software problem, Service Ownership enables automation and scalability, crucial for modern cloud-native environments.
- Error Budgets: It integrates with SRE’s error budget concept, balancing feature development with reliability.
Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| Service Ownership | End-to-end responsibility for a service’s lifecycle, from coding to monitoring. |
| Service Level Indicator (SLI) | A measurable metric reflecting service health (e.g., latency, error rate). |
| Service Level Objective (SLO) | A target value for an SLI, defining acceptable reliability levels. |
| Error Budget | A quantifiable allowance for service downtime, balancing reliability and innovation. |
| Toil | Repetitive, manual tasks that SREs aim to automate to focus on engineering. |
| Blameless Postmortem | A review process after incidents to identify root causes without assigning blame. |
How it Fits into the Site Reliability Engineering Lifecycle
Service Ownership is integral to the SRE lifecycle, which includes:
- Design and Development: Owners ensure services are designed with reliability in mind, incorporating SLIs/SLOs.
- Deployment: Owners manage CI/CD pipelines, ensuring safe rollouts (e.g., canary releases).
- Monitoring and Observability: Owners implement monitoring tools to track SLIs and respond to alerts.
- Incident Response: Owners handle incidents, conduct blameless postmortems, and improve systems.
- Continuous Improvement: Owners automate toil and refine processes to enhance reliability.
Architecture & How It Works
Components
- Service Codebase: The application code, developed and maintained by the owning team.
- Monitoring Systems: Tools like Prometheus or Grafana to track SLIs (latency, errors, traffic, saturation).
- CI/CD Pipelines: Automated pipelines for building, testing, and deploying code.
- Incident Management Tools: Systems like PagerDuty for alerting and escalation.
- Automation Scripts: Scripts to reduce toil, such as auto-scaling or log aggregation.
Internal Workflow
- Define SLIs/SLOs: The team sets measurable reliability goals based on user expectations.
- Develop and Deploy: Code is written, tested, and deployed using CI/CD pipelines.
- Monitor and Alert: Real-time data is collected, and alerts are triggered based on SLO thresholds.
- Incident Response: Owners resolve issues, document findings in postmortems, and implement fixes.
- Automate and Optimize: Toil is identified and automated, improving efficiency.
Architecture Diagram Description
The architecture of Service Ownership can be visualized as follows:
- Top Layer (Service): The application or microservice (e.g., a web app).
- Middle Layer (CI/CD & Automation): Jenkins or GitLab pipelines for deployment, Kubernetes for orchestration, and scripts for automation.
- Bottom Layer (Monitoring & Observability): Prometheus for metrics, Grafana for dashboards, and PagerDuty for alerts.
- Feedback Loop: Postmortems feed back into development to improve the service.
[ Developers / Owners ]
|
v
+------------------+ +--------------------+
| CI/CD Pipeline | -----> | Cloud Infra (AWS, |
| (GitHub Actions, | | GCP, Azure, K8s) |
| Jenkins, ArgoCD) | +--------------------+
+------------------+
|
v
+------------------+
| Observability | (Prometheus, ELK, Grafana, Datadog)
+------------------+
|
v
+------------------+
| Incident Mgmt | (PagerDuty, Opsgenie, Slack)
+------------------+
|
v
+------------------+
| Postmortem/RCA | --> Feedback Loop --> Back to Dev
+------------------+
Note: Since images cannot be generated, imagine a layered diagram with arrows showing bidirectional flow between development, deployment, and monitoring, with the owning team overseeing all layers.
Integration Points with CI/CD or Cloud Tools
- CI/CD: Integrates with tools like Jenkins, GitLab, or CircleCI for automated testing and deployment. Canary releases and blue-green deployments are common.
- Cloud Tools: Leverages cloud platforms (AWS, Azure, GCP) for auto-scaling, load balancing, and monitoring (e.g., AWS CloudWatch).
- Containerization: Uses Docker and Kubernetes for consistent deployments and orchestration.
Installation & Getting Started
Basic Setup or Prerequisites
- Skills: Basic knowledge of programming (Python, Go), Linux, and cloud platforms.
- Tools: Install Git, Docker, Kubernetes, Prometheus, and Grafana.
- Environment: Access to a cloud provider (e.g., AWS, GCP) or a local cluster (e.g., Minikube).
- Permissions: Admin access to set up monitoring and CI/CD pipelines.
Hands-on: Step-by-Step Beginner-Friendly Setup Guide
- Set Up a Sample Service:
# Clone a sample Node.js app
git clone https://github.com/example/sample-service.git
cd sample-service
npm install2. Containerize the Service:
# Dockerfile
FROM node:16
WORKDIR /app
COPY . .
RUN npm install
CMD ["npm", "start"]docker build -t sample-service .
docker run -p 3000:3000 sample-service3. Set Up Monitoring with Prometheus:
# Install Prometheus
wget https://github.com/prometheus/prometheus/releases/download/v2.45.0/prometheus-2.45.0.linux-amd64.tar.gz
tar xvfz prometheus-2.45.0.linux-amd64.tar.gz
cd prometheus-2.45.0.linux-amd64
./prometheus --config.file=prometheus.ymlConfigure prometheus.yml:
scrape_configs:
- job_name: 'sample-service'
static_configs:
- targets: ['localhost:3000']4. Visualize Metrics with Grafana:
# Run Grafana
docker run -d -p 3001:3000 grafana/grafanaAccess Grafana at http://localhost:3001, add Prometheus as a data source, and create dashboards for SLIs (e.g., latency, error rate).
5. Define SLOs:
Create an SLO document:
# SLO for Sample Service
- SLI: Latency (95th percentile < 200ms)
- SLO: 99.9% of requests meet latency SLI
- Error Budget: 0.1% downtime per month6. Set Up CI/CD with GitHub Actions:
# .github/workflows/deploy.yml
name: Deploy
on: [push]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Build Docker Image
run: docker build -t sample-service .
- name: Deploy to Kubernetes
run: kubectl apply -f k8s/deployment.yamlReal-World Use Cases
Scenario 1: E-Commerce Platform
- Context: An e-commerce company uses Service Ownership to manage its checkout service.
- Application: The team defines SLIs (e.g., transaction success rate) and SLOs (99.95% uptime). They use Kubernetes for auto-scaling during peak traffic and Prometheus for monitoring. Postmortems after a payment gateway failure lead to a fallback mechanism, reducing downtime by 60%.
Scenario 2: Financial Services
- Context: A bank implements Service Ownership for its online banking platform.
- Application: The team automates deployment with Jenkins and monitors latency with Grafana. A blameless postmortem after a latency spike reveals a database bottleneck, prompting query optimization, improving response times by 40%.
Scenario 3: Streaming Service
- Context: A video streaming platform uses Service Ownership for its content delivery service.
- Application: Owners implement circuit breakers to handle CDN failures and use AWS CloudWatch for SLIs. Regular failure drills reduce recovery time by 50%.
Scenario 4: Healthcare Application
- Context: A telemedicine app adopts Service Ownership to ensure HIPAA compliance.
- Application: The team integrates security monitoring with Splunk and automates compliance checks. Shared ownership ensures developers address vulnerabilities proactively, reducing security incidents by 30%.
Benefits & Limitations
Key Advantages
| Benefit | Description |
|---|---|
| Improved Reliability | Shared ownership ensures proactive monitoring and quick incident response. |
| Reduced Toil | Automation of repetitive tasks frees up time for engineering work. |
| Better Collaboration | Breaks down silos between development and operations teams. |
| Scalability | Enables efficient scaling through automation and cloud integration. |
Common Challenges or Limitations
| Challenge | Description |
|---|---|
| Cultural Resistance | Teams may resist taking on operational responsibilities. |
| Skill Gaps | Developers may lack operations expertise, requiring training. |
| Complexity | Managing distributed systems increases complexity in monitoring and debugging. |
| Initial Overhead | Setting up monitoring and automation requires upfront investment. |
Best Practices & Recommendations
Security Tips
- Implement least privilege access for CI/CD pipelines and monitoring tools.
- Use tools like Splunk or ELK Stack for security event monitoring.
- Conduct regular security audits and automate compliance checks (e.g., HIPAA, GDPR).
Performance
- Optimize SLIs for user-centric metrics (e.g., page load time over system CPU usage).
- Use load balancing and caching (e.g., Redis) to reduce latency.
- Implement canary releases to minimize deployment risks.
Maintenance
- Conduct blameless postmortems to learn from incidents.
- Regularly update SLOs based on user feedback and business needs.
- Automate toil (e.g., user provisioning, log rotation) using scripts or tools like Ansible.
Compliance Alignment
- Align SLOs with regulatory requirements (e.g., 99.99% uptime for financial services).
- Use tools like Configu for configuration management to ensure compliance.
Automation Ideas
- Automate alerting with PagerDuty to prioritize critical incidents.
- Use Kubernetes Horizontal Pod Autoscaler for dynamic scaling.
- Implement chaos engineering (e.g., Netflix Chaos Monkey) to test resilience.
Comparison with Alternatives
| Aspect | Service Ownership (SRE) | DevOps | Traditional IT Operations |
|---|---|---|---|
| Focus | Reliability, automation | Collaboration, CI/CD | Manual maintenance |
| Ownership | End-to-end by team | Shared across teams | Siloed operations |
| Automation | High (toil reduction) | Moderate to high | Low |
| Metrics | SLIs/SLOs, error budgets | CI/CD pipeline metrics | Uptime, ticket resolution |
| When to Choose | Complex, distributed systems | Rapid development cycles | Legacy systems |
When to Choose Service Ownership
- Choose Service Ownership: When managing large-scale, cloud-native applications requiring high reliability and automation.
- Choose Alternatives: DevOps for smaller teams focusing on CI/CD; traditional IT for legacy systems with minimal automation needs.
Conclusion
Service Ownership in SRE empowers teams to build and maintain reliable, scalable systems by fostering accountability and automation. It bridges the gap between development and operations, ensuring services meet user expectations while allowing for innovation. As cloud-native architectures and microservices grow, Service Ownership will become even more critical, with trends like AI-driven monitoring and zero-trust security shaping its future.