Introduction & Overview
What is Engineering Productivity in Site Reliability Engineering?
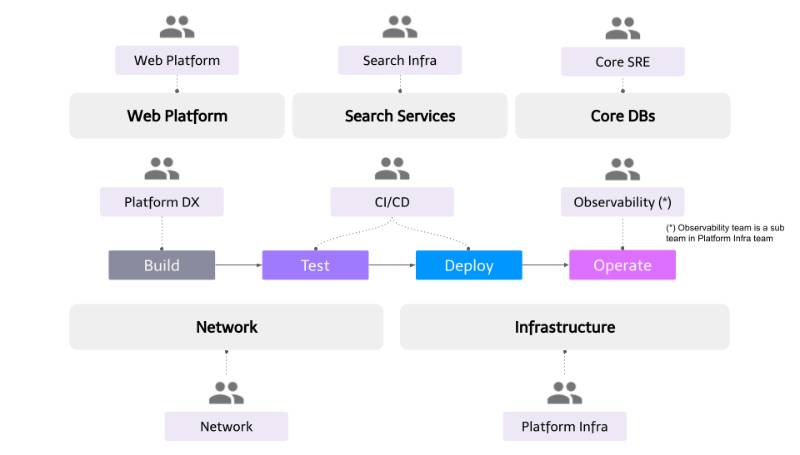
Engineering Productivity in the context of Site Reliability Engineering (SRE) refers to the strategies, tools, and practices that enable SRE teams to maximize efficiency, reduce toil (repetitive manual tasks), and enhance system reliability through automation, streamlined workflows, and data-driven decision-making. It encompasses optimizing the development lifecycle, automating operational tasks, and fostering collaboration between development and operations to ensure scalable, reliable systems.
History or Background
The concept of Engineering Productivity within SRE originated at Google in 2003, pioneered by Benjamin Treynor Sloss, who envisioned a software-driven approach to operations. The goal was to replace manual operations with automated systems, leveraging software engineering principles to manage large-scale infrastructure. This approach evolved into SRE, blending software engineering with IT operations to create reliable, scalable systems. Over time, companies like Netflix, Uber, and AWS adopted and adapted SRE principles, emphasizing automation and observability to boost productivity.
Why is it Relevant in Site Reliability Engineering?
Engineering Productivity is critical in SRE because it addresses the challenge of managing complex, large-scale systems while maintaining reliability and minimizing operational overhead. By automating repetitive tasks, optimizing workflows, and using metrics-driven insights, SRE teams can:
- Reduce downtime and improve system availability.
- Accelerate feature delivery without compromising stability.
- Enable engineers to focus on high-value tasks like system design and innovation.
- Align with business goals through measurable service-level objectives (SLOs).
Core Concepts & Terminology
Key Terms and Definitions
- Toil: Manual, repetitive, automatable tasks that do not provide long-term value. Reducing toil is a core focus of Engineering Productivity in SRE.
- Service-Level Indicators (SLIs): Measurable metrics like latency, error rate, or throughput that reflect system performance.
- Service-Level Objectives (SLOs): Target values for SLIs that define acceptable system reliability.
- Error Budget: A quantifiable allowance for system errors, balancing reliability with feature development velocity.
- Observability: The ability to understand a system’s internal state through logs, metrics, and traces.
- Automation: The use of software to perform operational tasks, reducing human intervention.
| Term | Definition | Example |
|---|---|---|
| Toil | Manual, repetitive work that scales with system size but adds no long-term value. | Restarting servers manually. |
| Automation | Use of scripts, tools, or platforms to eliminate toil. | Auto-healing Kubernetes pods. |
| Developer Velocity | Speed at which dev teams can deliver features safely. | Shorter CI/CD cycle times. |
| Feedback Loop | Time taken for developers to see results of their changes. | Fast test feedback in CI. |
| Reliability Metrics (SLI/SLO/SLA) | Indicators to measure service health & agreements with users. | 99.9% uptime commitment. |
How It Fits into the Site Reliability Engineering Lifecycle
Engineering Productivity integrates across the SRE lifecycle, which includes architecture, development, deployment, monitoring, and incident response:
- Architecture & Design: Productivity tools help design scalable systems with reliability in mind.
- Development & Deployment: Automation in CI/CD pipelines speeds up releases while maintaining quality gates.
- Monitoring & Observability: Metrics and dashboards provide insights to optimize performance.
- Incident Response: Automated runbooks and postmortems improve response times and learning.
Architecture & How It Works
Components and Internal Workflow
Engineering Productivity in SRE relies on a combination of tools, processes, and cultural practices. Key components include:
- Automation Tools: Tools like Ansible, Terraform, or AWS OpsWorks automate infrastructure provisioning and configuration.
- Monitoring & Observability Platforms: Prometheus, Grafana, or AWS CloudWatch provide real-time insights into system health.
- CI/CD Pipelines: Jenkins, GitLab CI, or GitHub Actions enable automated testing and deployment.
- Incident Management Systems: PagerDuty or Opsgenie streamline alerting and escalation.
- Configuration Management: Tools like Chef or Puppet ensure consistent system states.
Workflow:
- System Monitoring: SLIs (e.g., latency, error rates) are collected and visualized.
- Automation Triggers: Alerts or scripts trigger automated responses (e.g., scaling instances) based on predefined thresholds.
- Feedback Loop: Postmortems and metrics analysis inform system improvements.
- Continuous Deployment: CI/CD pipelines integrate reliability checks to deploy changes safely.
Architecture Diagram Description
The architecture diagram for an Engineering Productivity setup in SRE typically includes:
- Client Layer: End-users or services interacting with the system.
- Application Layer: Microservices or monolithic applications hosted on cloud infrastructure (e.g., AWS EC2, Kubernetes).
- Observability Layer: Tools like Prometheus and Grafana for metrics, logs, and traces.
- Automation Layer: Terraform for infrastructure-as-code, Ansible for configuration, and CI/CD pipelines for deployments.
- Incident Management Layer: PagerDuty for alerts and runbook automation.
- Data Storage: Databases or caches (e.g., Redis, MySQL) for state management.
┌───────────────────────────────┐
│ Developers (Code + Tests) │
└───────────────┬───────────────┘
│
┌─────────────────▼──────────────────┐
│ CI/CD Automation Layer │
│ (Build, Test, Deploy Pipelines) │
└─────────────────┬──────────────────┘
│
┌──────────────────────▼───────────────────────┐
│ Engineering Productivity Services │
│ - Caching & Build Optimization │
│ - Auto-Testing Frameworks │
│ - Static/Dynamic Code Analysis │
│ - Security & Compliance Automation │
└──────────────────────┬───────────────────────┘
│
┌───────────────────────▼─────────────────────────┐
│ SRE Systems (Reliability Layer) │
│ - Monitoring & Observability (Prometheus) │
│ - Incident Response & Runbooks (PagerDuty) │
│ - Self-Healing Infra (K8s, Terraform) │
└───────────────────────┬─────────────────────────┘
│
┌───────────────▼───────────────┐
│ Cloud/Infra Providers │
│ (AWS, GCP, Azure, On-Prem) │
└───────────────────────────────┘
Diagram Description: A layered diagram with clients at the top, feeding requests to a load-balanced application layer (e.g., Kubernetes pods). The observability layer collects metrics and logs, feeding into dashboards. The automation layer manages infrastructure and CI/CD pipelines, while the incident management layer handles alerts and escalations. Arrows indicate data flow between layers, with feedback loops for continuous improvement.
Integration Points with CI/CD or Cloud Tools
- CI/CD Integration: Tools like Jenkins or GitLab CI integrate with SRE workflows to enforce SLO-based quality gates, ensuring deployments meet reliability standards.
- Cloud Tools: AWS Systems Manager or Google Cloud Operations Suite provide centralized management for monitoring and automation.
- APIs: RESTful APIs connect observability tools with incident management systems for automated responses.
Installation & Getting Started
Basic Setup or Prerequisites
To implement an Engineering Productivity setup for SRE, you’ll need:
- Infrastructure: Cloud provider (AWS, GCP, Azure) or on-premises servers.
- Tools: Prometheus, Grafana, Terraform, Ansible, Jenkins, PagerDuty.
- Skills: Knowledge of Python, Bash, or Go for scripting; familiarity with Linux and cloud platforms.
- Access: Administrative access to cloud accounts and CI/CD systems.
Hands-On: Step-by-Step Beginner-Friendly Setup Guide
This guide sets up a basic SRE monitoring and automation stack using Prometheus, Grafana, and Terraform on AWS.
- Set Up AWS EC2 Instance:
- Launch an EC2 instance (e.g., t2.micro, Ubuntu 20.04).
- Open ports 9090 (Prometheus) and 3000 (Grafana) in the security group.
- Install Prometheus:
sudo apt update
sudo apt install prometheus
sudo systemctl start prometheus
sudo systemctl enable prometheusAccess Prometheus at http://<ec2-public-ip>:9090.
3. Install Grafana:
sudo apt-get install -y adduser libfontconfig1
wget https://dl.grafana.com/oss/release/grafana_8.5.0_amd64.deb
sudo dpkg -i grafana_8.5.0_amd64.deb
sudo systemctl start grafana-server
sudo systemctl enable grafana-serverAccess Grafana at http://<ec2-public-ip>:3000 (default login: admin/admin).
4. Configure Terraform for Automation:
provider "aws" {
region = "us-west-2"
}
resource "aws_instance" "sre_instance" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t2.micro"
tags = {
Name = "SRE-Monitoring"
}
}Run terraform init and terraform apply to provision infrastructure.
5. Set Up Alerts:
- In Prometheus, configure
prometheus.yml:
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']- In Grafana, add Prometheus as a data source and create a dashboard for SLIs (e.g., CPU usage, latency).
6. Test the Setup:
- Simulate a high CPU load using
stress:
sudo apt install stress
stress --cpu 8 --timeout 60s- Verify metrics in Grafana and set up alerts in PagerDuty.
Real-World Use Cases
- E-commerce Platform (e.g., Amazon):
- Scenario: During Black Friday, traffic spikes cause latency issues.
- Application: SREs use Prometheus to monitor SLIs (e.g., request latency) and Terraform to auto-scale EC2 instances. Automated runbooks restart failing services, reducing downtime.
- Outcome: 99.9% uptime maintained, ensuring customer satisfaction.
- Streaming Service (e.g., Netflix):
- Scenario: Encoding microservices fail during peak streaming hours.
- Application: Netflix uses a microservices architecture with observability tools like Atlas to monitor SLIs. Chaos engineering tests (e.g., Chaos Monkey) proactively identify weak points.
- Outcome: Automated failover ensures uninterrupted streaming.
- Ride-Sharing Platform (e.g., Uber):
- Financial Services (e.g., PayPal):
- Scenario: Transaction processing delays due to database bottlenecks.
- Application: SREs use Grafana to visualize database metrics and Ansible to automate configuration updates. Error budgets guide release decisions.
- Outcome: Faster transaction processing with minimal errors.
Benefits & Limitations
Key Advantages
- Reduced Toil: Automation eliminates repetitive tasks, freeing engineers for strategic work.
- Improved Reliability: SLOs and error budgets ensure consistent performance.
- Scalability: Automation and observability support large-scale systems.
- Faster Delivery: CI/CD integration accelerates feature releases.
Common Challenges or Limitations
- Complexity: Setting up observability and automation tools requires significant expertise.
- Initial Overhead: Time and cost to implement tools like Prometheus or Terraform.
- Cultural Resistance: Teams may resist adopting SRE practices due to unfamiliarity.
- Tool Fragmentation: Managing multiple tools (e.g., Grafana, PagerDuty) can be challenging.
Comparison Table
| Aspect | Engineering Productivity in SRE | Traditional Operations | DevOps |
|---|---|---|---|
| Focus | Reliability via automation | Manual system management | Collaboration & CI/CD |
| Toil Reduction | High (automation-driven) | Low (manual tasks) | Moderate |
| Scalability | High (cloud-native tools) | Low | High |
| Skill Requirement | Software engineering + operations | System administration | Dev + Ops |
| Example Tools | Prometheus, Terraform, PagerDuty | Nagios, manual scripts | Jenkins, Docker |
Best Practices & Recommendations
Security Tips
- Use least-privilege access for tools like Terraform and AWS IAM roles.
- Encrypt sensitive data in logs and metrics (e.g., using AWS KMS).
- Regularly audit monitoring and automation systems for vulnerabilities.
Performance
- Optimize SLIs for low latency (e.g., <200ms for API responses).
- Use caching (e.g., Redis) to reduce database load.
- Implement rate-limiting to prevent system saturation.
Maintenance
- Regularly update automation scripts and tools to avoid technical debt.
- Conduct blameless postmortems to learn from incidents.
- Rotate on-call duties to prevent burnout.
Compliance Alignment
- Align SLOs with regulatory requirements (e.g., GDPR for data privacy).
- Document automation workflows for auditability.
- Use tools like AWS Config to ensure compliance with cloud standards.
Automation Ideas
- Automate incident response with runbooks in PagerDuty.
- Use Terraform for infrastructure drift detection.
- Implement auto-scaling policies based on Prometheus metrics.
Comparison with Alternatives
Alternatives to Engineering Productivity in SRE
- Traditional Operations: Relies on manual processes, leading to high toil and slower response times.
- DevOps: Focuses on collaboration and CI/CD but may lack SRE’s emphasis on reliability metrics like SLOs.
- Platform Engineering: Focuses on building internal developer platforms, which may overlap with SRE but prioritizes developer experience over reliability.
When to Choose Engineering Productivity in SRE
- Choose SRE when reliability and scalability are critical (e.g., e-commerce, streaming).
- Choose DevOps for rapid feature delivery with less focus on strict reliability metrics.
- Choose Traditional Operations for small-scale systems with limited automation needs.
Conclusion
Engineering Productivity in SRE empowers teams to build reliable, scalable systems by leveraging automation, observability, and data-driven practices. By reducing toil and aligning with business goals, SRE enhances system performance and user satisfaction. Future trends include increased adoption of AI-driven observability and chaos engineering for proactive reliability. To get started, explore Google’s SRE books and tools like Prometheus and Terraform.
Resources: