Introduction & Overview
Auto Scaling is a critical practice in Site Reliability Engineering (SRE) that ensures systems dynamically adjust resources to meet demand, maintaining performance, reliability, and cost efficiency. This tutorial provides a detailed exploration of Auto Scaling, its architecture, setup, use cases, and best practices, tailored for SRE professionals and technical readers.
What is Auto Scaling?
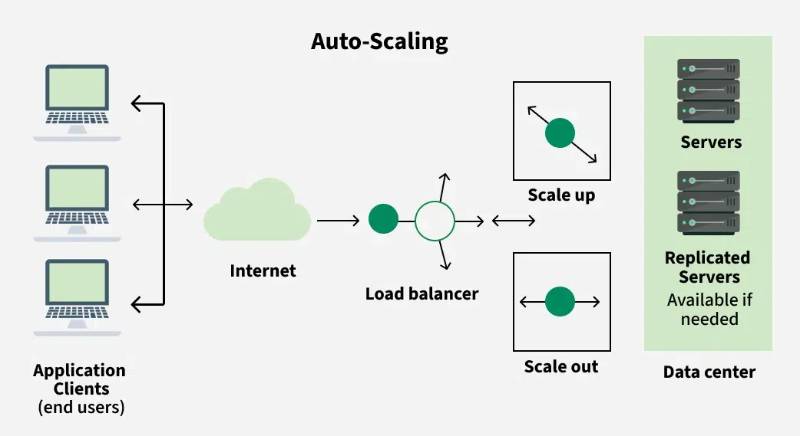
Auto Scaling is a cloud computing feature that automatically adjusts the number of computational resources (e.g., virtual machines, containers, or server instances) based on real-time workload demands. It ensures optimal performance during traffic spikes and cost savings during low-demand periods.
- Core Functionality: Automatically increases or decreases resources based on predefined metrics (e.g., CPU usage, request rates).
- Supported Platforms: Major cloud providers like AWS (Auto Scaling Groups), Azure (Virtual Machine Scale Sets), and GCP (Managed Instance Groups) offer robust Auto Scaling capabilities.
- SRE Relevance: Aligns with SRE principles of reliability, scalability, and automation by reducing manual intervention and ensuring system resilience.
History or Background
Auto Scaling emerged with the rise of cloud computing in the early 2000s. Amazon Web Services (AWS) introduced Auto Scaling in 2008 as part of its Elastic Compute Cloud (EC2), allowing users to scale resources dynamically. Since then, other cloud providers and container orchestration platforms like Kubernetes have adopted and expanded Auto Scaling mechanisms.
- Evolution: From manual server provisioning to policy-based scaling and predictive scaling using machine learning.
- Key Milestones:
- 2008: AWS Auto Scaling introduced.
- 2015: Kubernetes introduced Horizontal Pod Autoscaling (HPA).
- 2020s: Predictive scaling with AI/ML for proactive resource allocation.
Why is It Relevant in Site Reliability Engineering?
Auto Scaling is a cornerstone of SRE because it:
- Ensures Reliability: Maintains service availability during unexpected traffic surges.
- Optimizes Costs: Reduces resource waste by scaling down during low demand.
- Automates Operations: Minimizes toil by automating resource management, aligning with SRE’s focus on reducing manual work.
- Supports SLAs/SLOs: Helps meet Service Level Objectives (SLOs) by ensuring consistent performance under varying loads.
Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| Auto Scaling | Automatic adjustment of compute resources based on workload metrics. |
| Scaling Policy | Rules defining when and how to scale (e.g., CPU > 70% triggers scale-up). |
| Scaling Group | A collection of instances managed together (e.g., AWS Auto Scaling Group). |
| Horizontal Scaling | Adding/removing instances to handle load (e.g., more VMs or pods). |
| Vertical Scaling | Increasing/decreasing resources of a single instance (e.g., more CPU/RAM). |
| Metrics-Based Scaling | Scaling based on metrics like CPU, memory, or custom metrics. |
| Predictive Scaling | Using ML to forecast demand and scale proactively. |
| Cooldown Period | A delay after scaling to stabilize the system before further actions. |
How It Fits into the Site Reliability Engineering Lifecycle
Auto Scaling integrates into the SRE lifecycle at multiple stages:
- Design & Planning: Define scaling policies to meet SLOs.
- Implementation: Configure Auto Scaling in cloud or orchestration platforms.
- Monitoring & Observability: Use metrics (e.g., Prometheus, CloudWatch) to trigger scaling.
- Incident Response: Auto Scaling mitigates performance degradation during traffic spikes.
- Postmortems: Analyze scaling events to refine policies and improve reliability.
Architecture & How It Works
Components
Auto Scaling systems typically include:
- Resource Pool: Instances (VMs, containers) that can be scaled.
- Monitoring System: Collects metrics (e.g., CPU, latency) to trigger scaling.
- Scaling Policies: Rules defining thresholds and actions (e.g., add 2 instances if CPU > 80%).
- Controller: Orchestrates scaling actions (e.g., AWS Auto Scaling service, Kubernetes HPA).
- Load Balancer: Distributes traffic across scaled instances.
Internal Workflow
- Monitoring: The system collects metrics (e.g., via CloudWatch, Prometheus).
- Evaluation: The controller compares metrics against scaling policies.
- Scaling Action: If thresholds are met, the controller adds/removes resources.
- Load Balancing: Traffic is redistributed to new instances.
- Cooldown: The system stabilizes before evaluating further scaling needs.
Architecture Diagram Description
Since images cannot be directly included, here’s a textual description of a typical Auto Scaling architecture:
[User Requests] --> [Load Balancer]
|
v
[Auto Scaling Group] <--> [Monitoring System (e.g., CloudWatch)]
|
v
[Scaling Controller] --> [Cloud Provider API]
|
v
[Resource Pool: VMs/Containers]
- Components:
- Load Balancer: Distributes incoming traffic (e.g., AWS ELB, Nginx).
- Auto Scaling Group: Manages instances (e.g., EC2 instances, Kubernetes pods).
- Monitoring System: Tracks metrics (e.g., CPU, request rate).
- Scaling Controller: Executes scaling actions via cloud APIs.
- Resource Pool: Dynamically adjusts based on controller decisions.
Integration Points with CI/CD or Cloud Tools
- CI/CD: Auto Scaling integrates with CI/CD pipelines to deploy updated application versions across scaled instances (e.g., rolling updates in AWS CodeDeploy).
- Cloud Tools:
- AWS: CloudWatch for metrics, ELB for load balancing, CodePipeline for deployments.
- Kubernetes: Prometheus for monitoring, HPA for pod scaling.
- Azure/GCP: Similar integrations with Azure Monitor or Google Cloud Operations.
Installation & Getting Started
Basic Setup or Prerequisites
To set up Auto Scaling (using AWS as an example):
- Cloud Account: AWS account with permissions for EC2, Auto Scaling, and CloudWatch.
- Instance Template: An AMI (Amazon Machine Image) or launch configuration.
- Monitoring Tools: CloudWatch or equivalent for metrics.
- Load Balancer: Configured to distribute traffic (e.g., AWS ELB).
- IAM Roles: Permissions for Auto Scaling to manage instances.
Hands-On: Step-by-Step Beginner-Friendly Setup Guide (AWS Auto Scaling)
- Create a Launch Template:
- Go to AWS EC2 Console > Launch Templates > Create Launch Template.
- Specify an AMI, instance type (e.g., t2.micro), and security groups.
- Example configuration:
Name: my-launch-template
AMI: ami-1234567890abcdef0
InstanceType: t2.micro
SecurityGroups: sg-1234567890abcdef02. Set Up an Auto Scaling Group:
- Navigate to EC2 > Auto Scaling Groups > Create Auto Scaling Group.
- Select the launch template, specify VPC and subnets.
- Set desired capacity (e.g., 2), minimum (1), and maximum (4) instances.
3. Configure Scaling Policies:
- Choose “Target Tracking Scaling Policy” for simplicity.
- Example: Maintain average CPU utilization at 70%.
PolicyType: TargetTrackingScaling
TargetValue: 70.0
PredefinedMetricType: ASGAverageCPUUtilization4. Integrate with Load Balancer:
- Attach the Auto Scaling Group to an ELB.
- Configure health checks to ensure only healthy instances receive traffic.
5. Test Scaling:
- Simulate load (e.g., using
stresstool on a test instance). - Monitor CloudWatch to verify scaling actions.
6. Verify and Monitor:
- Check Auto Scaling Group status in AWS Console.
- Use CloudWatch dashboards to visualize metrics and scaling events.
Real-World Use Cases
Scenario 1: E-Commerce Platform During Sales
- Context: An e-commerce site experiences traffic spikes during Black Friday sales.
- Application: Auto Scaling adds EC2 instances when request rates exceed a threshold (e.g., 1000 requests/minute).
- Outcome: Maintains low latency, prevents downtime, and scales down post-sale to save costs.
Scenario 2: Streaming Service
- Context: A video streaming platform sees variable demand based on content releases.
- Application: Kubernetes HPA scales pods based on bandwidth usage or user connections.
- Outcome: Ensures smooth streaming without buffering, optimizes resource usage.
Scenario 3: Financial Transaction Processing
- Context: A fintech company processes high transaction volumes during market hours.
- Application: AWS Auto Scaling with predictive scaling forecasts demand using historical data.
- Outcome: Handles peak loads reliably, meets strict SLAs for transaction processing.
Scenario 4: Gaming Industry
- Context: A multiplayer game experiences unpredictable player surges.
- Application: GCP Managed Instance Groups scale based on player count metrics.
- Outcome: Provides seamless gameplay, reduces lag, and minimizes over-provisioning.
Benefits & Limitations
Key Advantages
- Reliability: Ensures system availability during traffic spikes.
- Cost Efficiency: Scales down resources during low demand.
- Automation: Reduces manual intervention, aligning with SRE principles.
- Flexibility: Supports various workloads (web apps, batch processing, etc.).
Common Challenges or Limitations
| Challenge | Description |
|---|---|
| Cold Start Delays | New instances may take time to initialize, causing brief latency spikes. |
| Cost Overruns | Misconfigured policies can lead to excessive resource usage. |
| Complex Configuration | Requires careful tuning of metrics and thresholds. |
| Application Constraints | Not all applications (e.g., stateful apps) scale seamlessly. |
Best Practices & Recommendations
Security Tips
- IAM Roles: Use least-privilege roles for Auto Scaling actions.
- Security Groups: Restrict instance access to necessary ports only.
- Encryption: Enable encryption for data in transit (e.g., HTTPS via ELB).
Performance
- Metric Selection: Choose metrics aligned with application needs (e.g., latency for web apps, queue depth for batch jobs).
- Warm-Up Periods: Configure warm-up times to allow instances to stabilize before receiving traffic.
- Predictive Scaling: Use ML-based forecasting for predictable workloads.
Maintenance
- Regular Policy Reviews: Update scaling thresholds based on usage patterns.
- Monitoring: Use observability tools (e.g., Prometheus, Grafana) to track scaling events.
- Testing: Simulate load to validate scaling behavior.
Compliance Alignment
- Ensure scaling policies comply with regulations (e.g., GDPR for data locality).
- Log scaling events for audit trails.
Automation Ideas
- Integrate with Infrastructure-as-Code (e.g., Terraform) for reproducible setups.
- Use CI/CD pipelines to automate instance updates during scaling.
Comparison with Alternatives
| Feature | Auto Scaling (Cloud) | Manual Scaling | Kubernetes HPA |
|---|---|---|---|
| Automation | Fully automated | Manual | Fully automated |
| Speed | Fast (minutes) | Slow (hours) | Fast (seconds) |
| Complexity | Moderate | Low | High |
| Cost Efficiency | High | Low | High |
| Stateful App Support | Limited | Good | Limited |
When to Choose Auto Scaling
- Choose Auto Scaling: For stateless applications, unpredictable workloads, or when automation is critical.
- Choose Alternatives: Manual scaling for small, predictable systems; Kubernetes HPA for containerized workloads.
Conclusion
Auto Scaling is a powerful tool for SREs, enabling reliable, cost-efficient, and automated resource management. By understanding its architecture, setup, and best practices, teams can build resilient systems that adapt to dynamic workloads. Future trends include increased adoption of predictive scaling and integration with serverless architectures.
Next Steps
- Experiment with Auto Scaling in a sandbox environment.
- Explore advanced features like predictive scaling or custom metrics.
- Join SRE communities (e.g., Reddit, Slack) to share knowledge.
Resources
- AWS Auto Scaling: https://docs.aws.amazon.com/autoscaling/
- Kubernetes HPA: https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
- Google Cloud Autoscaling: https://cloud.google.com/compute/docs/autoscaler