Introduction & Overview
Progressive Delivery is a modern software deployment strategy that enhances the reliability, scalability, and safety of releasing software updates in production environments. Rooted in the principles of Site Reliability Engineering (SRE), it allows teams to deploy changes incrementally, reducing the risk of widespread failures while maintaining a seamless user experience. This tutorial provides a comprehensive guide to understanding and implementing Progressive Delivery within the SRE framework, covering its concepts, architecture, practical setup, real-world applications, and best practices.
What is Progressive Delivery?
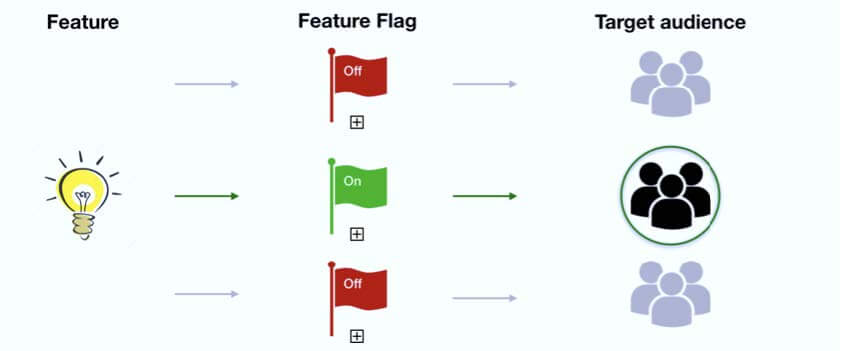
Progressive Delivery is an advanced deployment approach that enables teams to release software updates to a subset of users or systems before a full rollout. It builds on Continuous Deployment (CD) by introducing controlled, incremental release mechanisms such as canary releases, feature flags, and traffic shifting. This strategy minimizes the impact of potential issues by allowing teams to monitor and validate changes in production with real user traffic.
- Core Idea: Deliver changes gradually, monitor their impact, and adjust or rollback if needed.
- Key Features: Canary deployments, feature toggles, A/B testing, and blue-green deployments.
- Objective: Balance rapid innovation with system reliability and user satisfaction.
History or Background
Progressive Delivery evolved from the need to address the limitations of traditional deployment models like waterfall or big-bang releases, which often led to significant downtime or user-facing issues. The concept gained traction with the rise of DevOps and SRE practices, particularly at companies like Google, Netflix, and Amazon, which needed to deploy updates to massive, distributed systems without compromising reliability.
- Origin: Popularized by organizations adopting microservices and cloud-native architectures in the early 2010s.
- Influencers: Tools like Spinnaker, Flagger, and Argo Rollouts formalized Progressive Delivery workflows.
- Evolution: Integrated with CI/CD pipelines and observability tools to enhance monitoring and automation.
Why is it Relevant in Site Reliability Engineering?
In SRE, Progressive Delivery aligns with the goal of maintaining high reliability while enabling rapid feature delivery. It addresses the tension between development velocity and operational stability by providing mechanisms to test changes in production safely.
- Risk Mitigation: Limits the blast radius of faulty deployments.
- Observability: Leverages SRE’s focus on monitoring (SLIs/SLOs) to validate releases.
- Automation: Reduces manual intervention, aligning with SRE’s emphasis on eliminating toil.
- User-Centric: Ensures minimal disruption to user experience, a key SRE priority.
Core Concepts & Terminology
Progressive Delivery introduces several key concepts that integrate seamlessly into the SRE lifecycle. Below are the essential terms and their relevance.
Key Terms and Definitions
| Term | Definition |
|---|---|
| Canary Release | Deploying a new version to a small subset of users or servers for testing. |
| Feature Flags | Toggles that enable or disable specific features without redeploying code. |
| Traffic Shifting | Gradually redirecting user traffic to a new version of the application. |
| Blue-Green Deployment | Running two identical environments, switching traffic to the new one after validation. |
| A/B Testing | Comparing two versions of a feature to determine which performs better. |
| Error Budget | SRE concept allowing a predefined level of acceptable errors for releases. |
How It Fits into the Site Reliability Engineering Lifecycle
Progressive Delivery enhances the SRE lifecycle by embedding reliability-focused deployment practices into development, testing, and production phases:
- Planning: Define Service Level Objectives (SLOs) and Service Level Indicators (SLIs) to measure release success.
- Development: Use feature flags to isolate new code, enabling safe integration.
- Testing: Canary releases validate changes in production-like environments.
- Deployment: Traffic shifting ensures gradual exposure to new versions.
- Monitoring: Observability tools track SLIs (e.g., latency, error rates) during rollouts.
- Incident Response: Rollback mechanisms minimize downtime if issues arise.
Architecture & How It Works
Components
Progressive Delivery relies on a combination of tools, processes, and infrastructure components:
- CI/CD Pipeline: Automates code integration, testing, and deployment (e.g., Jenkins, GitLab CI).
- Feature Flag Management: Tools like LaunchDarkly or Unleash manage toggles.
- Service Mesh: Controls traffic routing (e.g., Istio, Linkerd).
- Observability Tools: Monitor SLIs/SLOs (e.g., Prometheus, Grafana, Datadog).
- Orchestration Platform: Manages containerized workloads (e.g., Kubernetes).
Internal Workflow
- Code Commit: Developers push code with feature flags to a version control system.
- CI/CD Trigger: The pipeline builds, tests, and deploys to a staging environment.
- Canary Deployment: A small percentage of traffic is routed to the new version.
- Monitoring: Observability tools track metrics like latency, errors, and saturation.
- Traffic Scaling: If metrics meet SLOs, traffic is incrementally shifted to the new version.
- Rollback or Full Rollout: Issues trigger a rollback; success leads to a full deployment.
Architecture Diagram Description
The architecture diagram illustrates a Progressive Delivery pipeline integrated with Kubernetes and a service mesh:
- Components:
- Version Control (Git): Stores application code and configuration.
- CI/CD System (Jenkins/GitLab): Builds and deploys artifacts.
- Kubernetes Cluster: Hosts application pods (old and new versions).
- Service Mesh (Istio): Manages traffic routing between versions.
- Observability Stack (Prometheus/Grafana): Monitors SLIs like error rates and latency.
- Flow:
- Code is pushed to Git, triggering the CI/CD pipeline.
- The pipeline deploys a canary pod in Kubernetes.
- Istio routes 5% of traffic to the canary pod.
- Prometheus collects metrics; Grafana visualizes them.
- If SLIs are within SLOs, Istio increases traffic to the new version.
- Diagram Layout:
- Left: Git repository → CI/CD pipeline.
- Center: Kubernetes cluster with two pods (v1, v2) and Istio routing traffic.
- Right: Prometheus/Grafana dashboards displaying metrics.
- Arrows: Show data flow from code commit to monitoring.
+------------------+ +------------------+ +-----------------+
| CI Pipeline |-----> | Deployment Tool |-----> | Kubernetes |
| (Build & Test) | | (Argo/Spinnaker) | | Cluster |
+------------------+ +------------------+ +-----------------+
|
v
+----------------------+
| Traffic Splitter |
| (Istio/Envoy) |
+----------------------+
/ \
/ \
+--------------------+ +--------------------+
| Canary Users (10%) | | Regular Users (90%)|
+--------------------+ +--------------------+
\ /
v v
+--------------------------+
| Monitoring & Observability|
| (Prometheus, Grafana) |
+--------------------------+
Integration Points with CI/CD or Cloud Tools
- CI/CD: Tools like ArgoCD or Spinnaker integrate Progressive Delivery with automated rollouts.
- Cloud: AWS ALB, GCP Traffic Director, or Azure Traffic Manager support traffic splitting.
- Observability: Prometheus, Grafana, and ELK stack provide real-time insights.
- Feature Flags: LaunchDarkly or Unleash integrate with CI/CD for dynamic toggles.
Installation & Getting Started
Basic Setup or Prerequisites
To implement Progressive Delivery, you need:
- Kubernetes Cluster: A running cluster (e.g., Minikube for local, EKS/GKE for production).
- CI/CD Tool: Jenkins, GitLab CI, or ArgoCD.
- Service Mesh: Istio or Linkerd for traffic management.
- Monitoring Tools: Prometheus and Grafana for observability.
- Feature Flag Tool: LaunchDarkly or Unleash (optional).
- Basic Knowledge: Familiarity with Kubernetes, Docker, and YAML.
Hands-On: Step-by-Step Beginner-Friendly Setup Guide
This guide sets up a Progressive Delivery pipeline using Kubernetes, Istio, and Argo Rollouts.
- Install Minikube:
minikube startEnsure Minikube is running with at least 4GB RAM and 2 CPUs.
2. Install Istio:
curl -L https://istio.io/downloadIstio | sh -
cd istio-<version>
./bin/istioctl install --set profile=demo -y
kubectl label namespace default istio-injection=enabled3. Install Argo Rollouts:
kubectl create namespace argo-rollouts
kubectl apply -n argo-rollouts -f https://github.com/argoproj/argo-rollouts/releases/latest/download/install.yaml4. Deploy a Sample Application:
Create a file app.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-app
spec:
replicas: 3
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
containers:
- name: sample-app
image: nginx:1.14
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: sample-app
spec:
ports:
- port: 80
targetPort: 80
selector:
app: sample-appApply it:
kubectl apply -f app.yaml5. Create a Canary Rollout:
Create a file rollout.yaml:
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: sample-app-rollout
spec:
replicas: 3
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
containers:
- name: sample-app
image: nginx:1.15
ports:
- containerPort: 80
strategy:
canary:
steps:
- setWeight: 20
- pause: {duration: 60s}
- setWeight: 50
- pause: {}Apply it:
kubectl apply -f rollout.yaml6. Set Up Monitoring:
Install Prometheus and Grafana using Helm:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm install prometheus prometheus-community/kube-prometheus-stack7. Verify the Rollout:
Check the rollout status:
kubectl argo rollouts get rollout sample-app-rolloutMonitor metrics in Grafana at http://<minikube-ip>:3000.
Real-World Use Cases
Scenario 1: E-Commerce Platform
- Context: An e-commerce platform wants to deploy a new checkout feature without risking downtime during peak sales.
- Implementation: Use feature flags to enable the feature for 5% of users. Monitor error rates and transaction success SLIs. Gradually increase traffic to 100% if metrics are stable.
- Outcome: Reduced risk of cart abandonment; validated feature performance with real users.
Scenario 2: Financial Services
- Context: A banking app introduces a new payment processing module.
- Implementation: Deploy a canary release to a single region, using Istio to route 10% of traffic. Monitor latency and error rates against SLOs. Roll back if SLIs degrade.
- Outcome: Ensured compliance with financial regulations by minimizing disruptions.
Scenario 3: Streaming Service
- Context: A video streaming platform rolls out a new codec to improve quality.
- Implementation: Use A/B testing to compare old and new codecs for a subset of users. Measure buffering rates and user engagement. Shift traffic to the new codec if successful.
- Outcome: Improved user experience without widespread quality issues.
Scenario 4: Healthcare Application
- Context: A telemedicine app updates its appointment scheduling system.
- Implementation: Blue-green deployment to switch traffic to the new version after validation. Use observability tools to ensure HIPAA compliance and low latency.
- Outcome: Maintained patient data security and service availability.
Benefits & Limitations
Key Advantages
| Benefit | Description |
|---|---|
| Reduced Risk | Limits impact of failures to a small user base, protecting overall uptime. |
| Improved Observability | Real-time monitoring of SLIs enables data-driven rollout decisions. |
| Faster Innovation | Allows frequent releases without compromising reliability. |
| User-Centric | Gradual rollouts minimize disruptions, enhancing user satisfaction. |
Common Challenges or Limitations
| Challenge | Description |
|---|---|
| Complexity | Requires sophisticated tooling and expertise in service meshes and CI/CD. |
| Monitoring Overhead | Needs robust observability to track SLIs across multiple versions. |
| Cost | Additional infrastructure (e.g., duplicate environments) increases costs. |
| Learning Curve | Teams need training to adopt tools like Argo Rollouts or Istio effectively. |
Best Practices & Recommendations
- Security Tips:
- Use feature flags with access controls to prevent unauthorized feature activation.
- Encrypt traffic in the service mesh to protect sensitive data.
- Performance:
- Optimize canary deployments by starting with minimal traffic (e.g., 1–5%).
- Use automated rollback triggers based on SLI thresholds.
- Maintenance:
- Regularly update feature flag configurations to avoid technical debt.
- Maintain a rollback playbook for quick recovery during incidents.
- Compliance Alignment:
- Align SLOs with regulatory requirements (e.g., GDPR, HIPAA).
- Document all rollout decisions for auditability.
- Automation Ideas:
- Automate traffic shifting with Argo Rollouts or Flagger.
- Integrate observability alerts with incident management tools like PagerDuty.
Comparison with Alternatives
| Feature/Approach | Progressive Delivery | Traditional CD | Blue-Green Deployment |
|---|---|---|---|
| Risk Management | Gradual rollout with canaries | Full rollout, higher risk | Low risk with full switch |
| Complexity | High (requires service mesh) | Moderate | Moderate |
| Observability | Real-time SLIs/SLOs | Limited | Moderate |
| Cost | High (infrastructure) | Low | Medium |
| Use Case | Complex, user-facing apps | Simple apps | Stable apps |
When to Choose Progressive Delivery
- Choose Progressive Delivery: For large-scale, distributed systems requiring high reliability and frequent updates (e.g., e-commerce, streaming).
- Choose Alternatives: Traditional CD for small apps with low risk; blue-green for stable systems with infrequent updates.
Conclusion
Progressive Delivery is a transformative approach in SRE, enabling teams to balance innovation and reliability through controlled, data-driven deployments. By leveraging canary releases, feature flags, and observability, organizations can deploy updates with confidence, minimizing risks and enhancing user experience. As cloud-native architectures and microservices continue to dominate, Progressive Delivery will become increasingly vital.
Future Trends:
- AI-Driven Rollouts: Machine learning to predict rollout success based on historical metrics.
- Zero-Downtime Deployments: Enhanced automation for seamless transitions.
- Wider Tool Adoption: Growth of tools like Argo Rollouts and Flagger.
Next Steps:
- Explore tools like Argo Rollouts, Istio, and LaunchDarkly.
- Join SRE communities (e.g., SREcon, CNCF Slack).
- Experiment with small-scale canary deployments in non-critical systems.
Resources:
- Official Argo Rollouts Docs: argo-rollouts.readthedocs.io
- Istio Documentation: istio.io
- SRE Book by Google: sre.google