Introduction & Overview
Site Reliability Engineering (SRE) is a discipline that blends software engineering with IT operations to build and maintain scalable, reliable systems. A critical concept in SRE is toil, which represents repetitive, manual, and automatable tasks that consume valuable engineering time without contributing to long-term system improvements. This tutorial provides an in-depth exploration of toil in the context of SRE, covering its definition, significance, architecture, practical applications, and best practices. By understanding and managing toil, SRE teams can optimize their workflows, enhance system reliability, and focus on high-value engineering tasks.
The tutorial is structured to guide both beginners and experienced practitioners through the concept of toil, offering theoretical insights, practical steps, and real-world examples. It includes an architecture diagram description, step-by-step setup guides, and comparisons with alternative approaches to ensure a comprehensive understanding.
What is Toil?
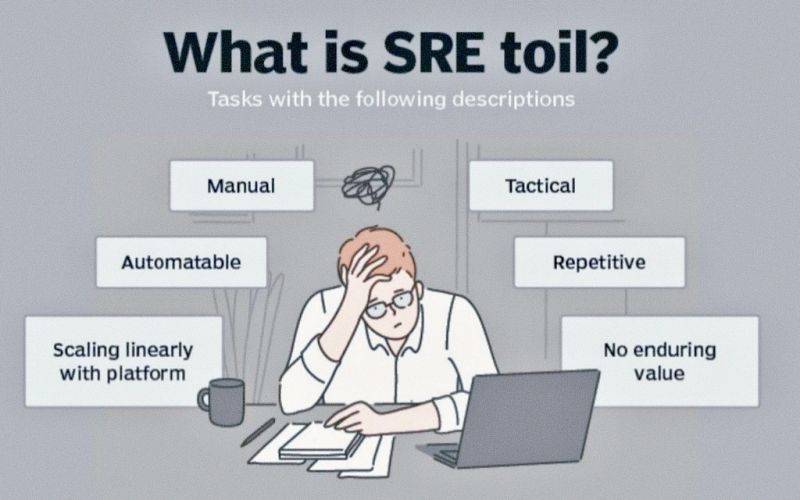
Definition
Toil, as defined in the Site Reliability Engineering book by Google, is the kind of work tied to running a production service that is:
- Manual: Requires human intervention.
- Repetitive: Involves performing the same task repeatedly.
- Automatable: Can be handled by a machine or script.
- Tactical: Focused on immediate fixes rather than strategic improvements.
- Devoid of Enduring Value: Does not contribute to long-term system improvements.
- Scales Linearly: Grows proportionally with service size or usage.
Examples include manually restarting services, responding to repetitive alerts, or performing routine maintenance tasks like clearing caches.
History or Background
The concept of toil was formalized by Google in the early 2000s when Ben Treynor Sloss, the founder of Google’s SRE team, sought to address operational inefficiencies in managing large-scale systems. As Google’s services grew, manual operations became unsustainable, leading to the identification of toil as a key bottleneck. The SRE philosophy emerged to treat operations as a software problem, emphasizing automation to reduce toil and improve scalability. Since then, toil management has become a cornerstone of SRE, adopted by organizations worldwide to optimize engineering workflows.
Why is Toil Relevant in SRE?
Toil is critical in SRE because it directly impacts team efficiency and system reliability. Excessive toil:
- Reduces Engineering Time: Prevents SREs from focusing on strategic tasks like system design or feature development.
- Increases Burnout: Repetitive tasks can demotivate engineers, leading to reduced morale.
- Hinders Scalability: Manual tasks scale linearly with system growth, making them unsustainable for large systems.
- Increases Error Rates: Human intervention is prone to mistakes, affecting system reliability.
Google’s SRE teams aim to keep toil below 50% of an engineer’s time, reserving the remaining time for engineering work that enhances system reliability and performance. This balance is essential for maintaining scalable, reliable systems.
Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| Toil | Manual, repetitive, automatable tasks that lack long-term value and scale linearly. |
| SRE | Site Reliability Engineering, a discipline combining software engineering and operations. |
| SLO | Service Level Objective, a target reliability metric for a service. |
| SLI | Service Level Indicator, a measurable metric tied to user experience (e.g., latency). |
| Error Budget | The acceptable amount of downtime or errors based on SLOs, used to balance reliability and innovation. |
| Overhead | Administrative tasks (e.g., meetings, HR paperwork) not classified as toil. |
| Automation | The process of replacing manual tasks with scripts or tools to reduce toil. |
How Toil Fits into the SRE Lifecycle
Toil is a recurring challenge across the SRE lifecycle, which includes:
- System Design: Designing systems to minimize toil through automation and self-healing mechanisms.
- Development: Building tools to automate repetitive tasks, reducing future toil.
- Deployment: Automating deployments to avoid manual rollouts, a common source of toil.
- Monitoring and Incident Response: Handling alerts manually is toil; automating responses reduces it.
- Postmortems: Analyzing incidents to identify toil-inducing processes and automate them.
- Capacity Planning: Manual scaling is toil; automated scaling based on metrics reduces it.
By addressing toil at each stage, SREs ensure systems remain reliable and scalable while freeing up time for strategic work.
Architecture & How It Works
Components and Internal Workflow
Toil management in SRE involves identifying, measuring, and reducing toil through structured processes:
- Identification: Recognizing tasks that match toil characteristics (manual, repetitive, automatable).
- Measurement: Tracking the time spent on toil using surveys or time-tracking tools.
- Reduction: Automating tasks or redesigning systems to eliminate toil.
- Monitoring: Continuously assessing toil levels to maintain the 50% threshold.
The workflow typically follows:
- Task Logging: SREs log tasks performed during on-call shifts or daily operations.
- Toil Classification: Tasks are categorized as toil, overhead, or engineering work based on defined criteria.
- Automation Development: Scripts or tools are created to automate repetitive tasks.
- Validation: Automated solutions are tested to ensure they reduce toil without introducing risks.
- Iterative Improvement: Toil is re-evaluated periodically to identify new sources.
Architecture Diagram Description
Due to text-based limitations, an architecture diagram cannot be embedded. Below is a detailed description of a toil management architecture in SRE:
Diagram Title: Toil Management Workflow in SRE
Components:
- Input Layer:
- On-call tickets, alerts, and manual task logs (e.g., server restarts, user provisioning).
- Processing Layer:
- Toil Identification Module: Analyzes logs to flag repetitive, manual tasks.
- Metrics Dashboard: Tracks toil percentage (e.g., 33% average at Google) using tools like Prometheus or Grafana.
- Automation Engine: Executes scripts or tools (e.g., Ansible, Terraform) to automate tasks.
- Output Layer:
- Automated workflows (e.g., auto-scaling, alert suppression).
- Reports for SRE teams to review toil reduction progress.
- Feedback Loop: Postmortems and surveys feed back into the system to refine automation and identify new toil.
Flow:
- Inputs (tasks/alerts) enter the system.
- The Toil Identification Module classifies tasks.
- The Metrics Dashboard quantifies toil.
- The Automation Engine deploys scripts to eliminate toil.
- Outputs are monitored, and feedback is used to iterate.
flowchart TD
A[Incident/Manual Task Detected] --> B[Classify: Toil or Non-Toil]
B -->|Toil| C[Automate with Scripts/IaC/CI-CD]
B -->|Non-Toil| D[Continue as Engineering Work]
C --> E[Monitor Effectiveness]
E --> F[Measure Reduction in Toil %]
F --> A
Integration Points with CI/CD or Cloud Tools
Toil management integrates with:
- CI/CD Pipelines: Automating deployments using tools like Jenkins or GitLab CI reduces manual release toil.
- Cloud Platforms: Auto-scaling groups in AWS or Kubernetes Horizontal Pod Autoscaling eliminate manual scaling toil.
- Monitoring Tools: Prometheus and PagerDuty can suppress repetitive alerts, reducing alert-handling toil.
- Configuration Management: Tools like Ansible or Chef automate server configuration, minimizing manual setup toil.
Installation & Getting Started
Basic Setup or Prerequisites
To start managing toil in an SRE environment, you need:
- Monitoring Tools: Prometheus, Grafana, or ELK Stack for tracking toil metrics.
- Automation Tools: Ansible, Terraform, or Python for scripting repetitive tasks.
- Ticketing System: Jira or ServiceNow to log and analyze tasks.
- Version Control: Git for storing automation scripts.
- Team Buy-In: Agreement to track and reduce toil, aiming for the 50% threshold.
Hands-On: Step-by-Step Beginner-Friendly Setup Guide
This guide demonstrates how to set up a basic toil-tracking and automation system using Python and Prometheus.
- Set Up Prometheus for Toil Metrics:
- Install Prometheus on a server or use a cloud-hosted instance.Configure a custom metric to track toil hours.
# prometheus.yml
scrape_configs:
- job_name: 'toil_metrics'
static_configs:
- targets: ['localhost:8000']Start Prometheus: prometheus --config.file=prometheus.yml.
2. Create a Python Script to Log Toil:
- Write a script to log tasks and classify them as toil.
from prometheus_client import Gauge, start_http_server
import time
toil_gauge = Gauge('sre_toil_hours', 'Hours spent on toil tasks')
def log_task(task_name, duration, is_manual, is_repetitive):
if is_manual and is_repetitive:
toil_gauge.inc(duration)
print(f"Logged toil task: {task_name}, Duration: {duration} hours")
else:
print(f"Non-toil task: {task_name}")
start_http_server(8000)
log_task("Restart server", 0.5, True, True)
time.sleep(60) # Keep server running3. Automate a Common Toil Task:
- Example: Automate server restarts using a Python script with
systemctl.
import os
import time
def check_and_restart_service(service_name):
status = os.system(f"systemctl is-active --quiet {service_name}")
if status != 0:
print(f"Restarting {service_name}...")
os.system(f"systemctl restart {service_name}")
print(f"{service_name} restarted successfully.")
else:
print(f"{service_name} is running.")
while True:
check_and_restart_service("nginx")
time.sleep(300) # Check every 5 minutes4. Visualize Toil Metrics:
- Set up Grafana and connect it to Prometheus.
- Create a dashboard to visualize
sre_toil_hoursover time. - Set alerts if toil exceeds 50% of weekly hours.
5. Review and Iterate:
- Conduct bi-weekly team surveys to identify new toil.
- Update automation scripts based on feedback.
Real-World Use Cases
Scenario 1: Manual Server Restarts in a Web Application
- Context: A web application hosted on AWS EC2 instances frequently crashes due to memory leaks, requiring manual restarts.
- Toil: SREs log in to servers, check logs, and restart services multiple times daily.
- Solution: Implement an auto-restart script using AWS Lambda triggered by CloudWatch alarms. This reduces toil by automating restarts and logging incidents for root-cause analysis.
- Industry: E-commerce, where uptime is critical for customer experience.
Scenario 2: Repetitive Alert Handling in a SaaS Platform
- Context: A SaaS platform generates frequent low-priority alerts for disk space issues.
- Toil: Engineers manually clear caches or delete logs to resolve alerts.
- Solution: Deploy a cron job or Kubernetes pod to automatically clean up disk space when thresholds are reached, integrated with PagerDuty for alert suppression.
- Industry: Software-as-a-Service, where rapid scaling is common.
Scenario 3: Manual User Provisioning in a Financial Institution
- Context: A bank’s internal system requires manual user account creation for new employees.
- Toil: SREs spend hours weekly creating accounts and assigning permissions.
- Solution: Use Terraform to automate user provisioning in Active Directory, triggered by HR system updates.
- Industry: Finance, where security and compliance are paramount.
Scenario 4: Manual Scaling in a Gaming Platform
- Context: A multiplayer gaming platform experiences traffic spikes during events, requiring manual scaling of servers.
- Toil: Engineers manually add or remove instances based on traffic.
- Solution: Configure AWS Auto Scaling groups to adjust capacity based on CPU utilization or request rates.
- Industry: Gaming, where low latency is critical.
Benefits & Limitations
Key Advantages
- Increased Efficiency: Reducing toil frees up time for strategic engineering work, improving system reliability.
- Scalability: Automation ensures tasks don’t grow linearly with service size.
- Improved Morale: Less repetitive work reduces engineer burnout.
- Lower Error Rates: Automated processes are less prone to human error.
Common Challenges or Limitations
| Challenge | Description |
|---|---|
| Identifying Toil | Subjective definitions can lead to misclassification of tasks. |
| Automation Costs | Developing automation may require significant upfront investment. |
| Incomplete Automation | Some tasks (e.g., complex decision-making) may resist automation. |
| Cultural Resistance | Teams may resist automating tasks they perceive as valuable. |
Best Practices & Recommendations
Security Tips
- Secure Automation Scripts: Store scripts in a version-controlled repository with access controls.
- Audit Automation: Regularly review automated workflows to ensure they don’t introduce vulnerabilities.
- Use Least Privilege: Ensure automation tools operate with minimal permissions.
Performance
- Prioritize High-Impact Toil: Focus on automating tasks that consume the most time or scale linearly.
- Monitor Automation: Use metrics to verify that automation reduces toil without degrading performance.
Maintenance
- Regular Surveys: Conduct bi-weekly or monthly surveys to track toil levels.
- Update Playbooks: Document automation procedures in runbooks to ensure consistency.
Compliance Alignment
- Document Changes: Log all automated actions for auditability, especially in regulated industries like finance.
- Test Automation: Use canary deployments to validate automation in production.
Automation Ideas
- Self-Healing Systems: Implement auto-recovery for common failures (e.g., Kubernetes liveness probes).
- Ticketing as API: Use ticketing systems like ServiceNow as an interface for self-service automation.
Comparison with Alternatives
| Approach | Toil Management (SRE) | Traditional Ops | DevOps |
|---|---|---|---|
| Focus | Automate toil, balance reliability and innovation | Manual operations | Continuous delivery |
| Toil Handling | Explicit goal to keep toil <50% | High toil, often 80%+ | Varies, automation-focused |
| Scalability | Sublinear scaling via automation | Linear scaling | Sublinear with CI/CD |
| When to Choose | Large-scale, reliability-critical systems | Small, simple systems | Agile, feature-driven teams |
When to Choose Toil Management in SRE
- Choose SRE Toil Management: When running complex, large-scale systems where reliability is critical, and manual tasks hinder scalability.
- Choose Traditional Ops: For small systems with minimal automation needs.
- Choose DevOps: When rapid feature delivery is prioritized over strict reliability goals.
Conclusion
Toil is a critical concept in SRE, representing the repetitive, manual tasks that can consume engineering time and hinder system scalability. By identifying, measuring, and automating toil, SRE teams can focus on high-value engineering work, improving system reliability and team morale. This tutorial covered the definition, history, and significance of toil, along with practical steps for setup, real-world applications, and best practices. As systems grow in complexity, toil management will remain a cornerstone of SRE, with trends pointing toward increased automation and integration with AI-driven observability tools.
Next Steps
- Read the Google SRE Book: Chapter 5 on Eliminating Toil provides detailed insights.
- Join SRE Communities: Participate in SREcon or online forums like r/sre on Reddit.
- Experiment with Automation: Start small by automating one repetitive task in your environment.