1. Introduction & Overview
What is Failover?
Failover refers to the capability of a system to automatically switch to a redundant or standby system or component when the primary system fails. This ensures high availability, business continuity, and resilience in distributed systems—an essential trait in DevSecOps environments where uptime, security, and automation are paramount.
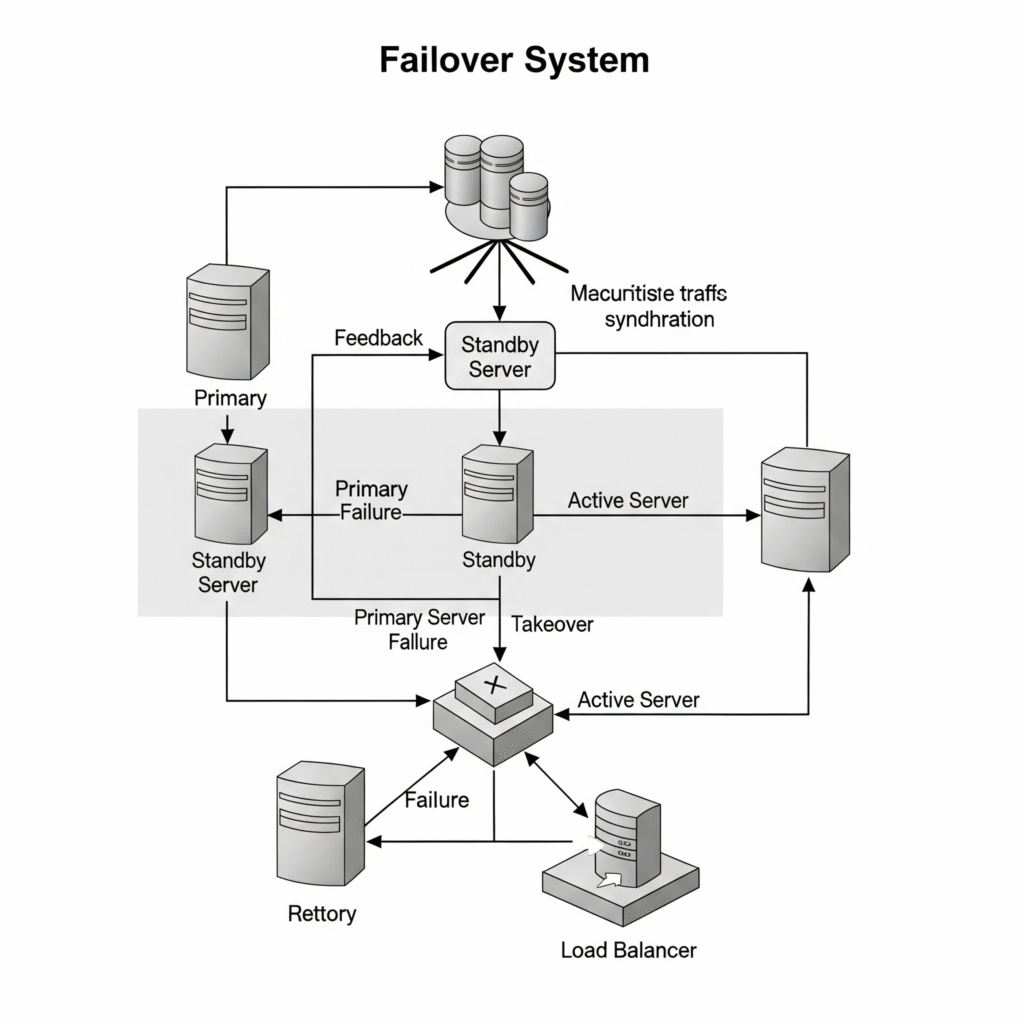
History or Background
The concept of failover emerged alongside high-availability computing in the 1970s. Initially confined to mainframes and critical telecommunications systems, it later evolved into:
- Active-passive clusters
- Database replication
- Load-balanced systems
- Cloud-native architectures (e.g., AWS Availability Zones, Kubernetes replicas)
Why is it Relevant in DevSecOps?
DevSecOps emphasizes continuous delivery, automated security, and resilience. Failover directly supports these goals:
- Ensures secure application availability during failure
- Mitigates risks due to hardware/software faults or cyberattacks
- Enables automated recovery mechanisms in CI/CD workflows
- Integrates with monitoring and alerting systems
2. Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| Failover | Switching to a backup system when the primary fails |
| High Availability (HA) | Architecture design to ensure operational continuity |
| RPO (Recovery Point Objective) | Maximum data loss allowed during failure |
| RTO (Recovery Time Objective) | Maximum acceptable downtime after failure |
| Active-Active | All nodes are live and can serve traffic |
| Active-Passive | Only the primary node is active; secondary activates on failure |
How It Fits into the DevSecOps Lifecycle
Failover mechanisms align with the “Operate” and “Respond” phases of the DevSecOps lifecycle:
- Monitor: Detect failure using logging/telemetry (e.g., Prometheus, Grafana)
- Automate: Trigger failover using scripts or orchestration tools (e.g., Kubernetes, Terraform)
- Secure: Ensure backups and replicas are secure, encrypted, and compliant
- Respond: Mitigate threats using automated response mechanisms
3. Architecture & How It Works
Components of a Failover System
- Health Check/Monitoring System (e.g., Prometheus, CloudWatch)
- Load Balancer (e.g., HAProxy, AWS ELB)
- Replication Mechanism (e.g., DB replication, S3 cross-region replication)
- Orchestrator (e.g., Kubernetes, Nomad)
- Failover Trigger Mechanism (e.g., Lambda functions, Ansible scripts)
Internal Workflow
- Health check detects failure (e.g., pod crash)
- Monitoring system alerts orchestrator
- Orchestrator triggers a failover event
- Load balancer redirects traffic
- Backup/replica takes over
Architecture Diagram (Described)
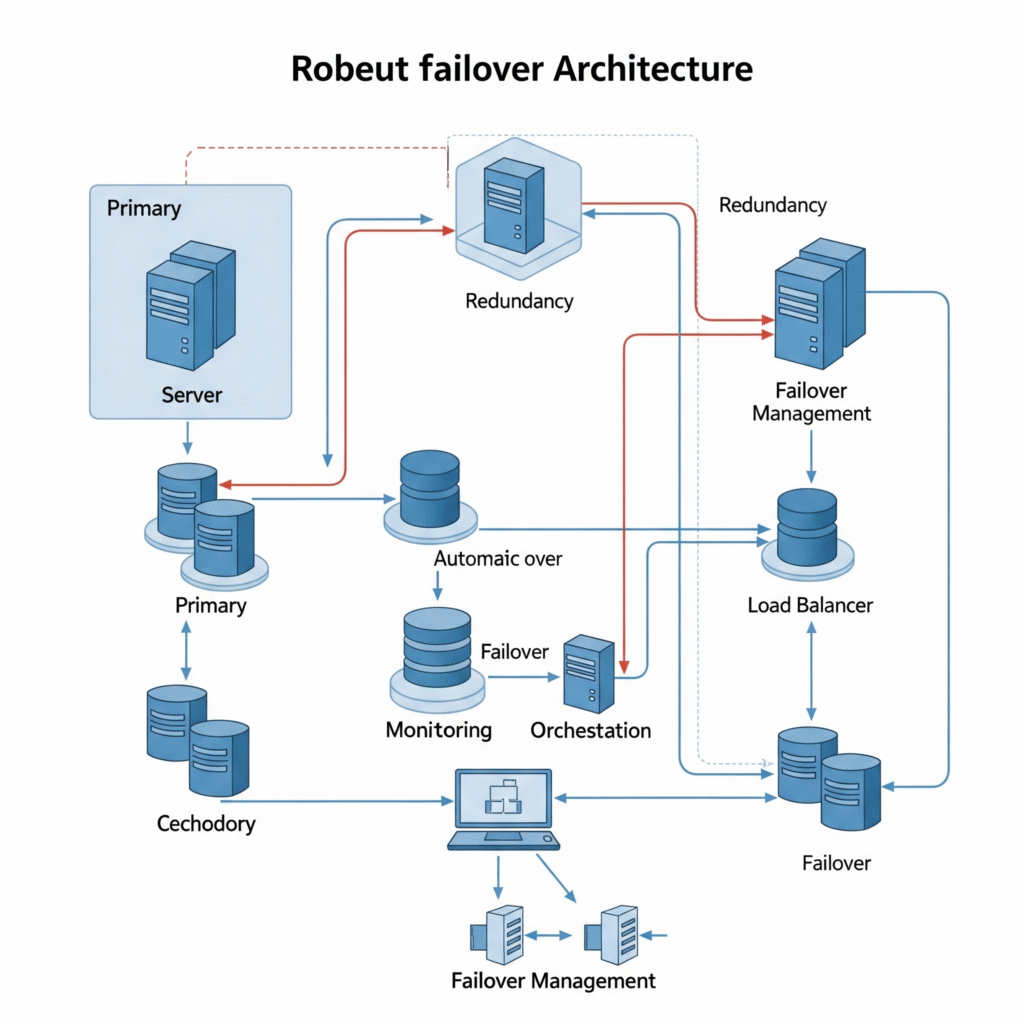
Failover Architecture (Cloud-native Example)
┌──────────────┐
│ Load │
│ Balancer │
└────┬─────────┘
│
┌────────────┴────────────┐
│ │
┌───────▼──────┐ ┌────────▼──────┐
│ Primary Pod │ │ Secondary Pod │
│ Region A │ │ Region B │
│ (Active) │ │ (Passive) │
└──────────────┘ └───────────────┘
│ │
┌─────▼────┐ ┌─────▼────┐
│ Database │ │ Database │
│ (Primary)│ │ (Replica)│
└──────────┘ └──────────┘
Integration Points with CI/CD or Cloud Tools
| Tool | Integration Example |
|---|---|
| GitHub Actions | Trigger failover scripts via webhook |
| Terraform | Provision HA resources across AZs |
| Kubernetes | Use readiness probes, replicas, and self-healing |
| AWS/GCP/Azure | Native support for regional failover and multi-AZ deployment |
| Ansible | Automate failover orchestration |
4. Installation & Getting Started
Basic Setup or Prerequisites
- Container orchestrator (e.g., Kubernetes)
- Cloud provider with multi-zone capability (e.g., AWS)
- Load balancer and monitoring stack
- Access to infrastructure-as-code tool (e.g., Terraform)
Step-by-Step Setup (Kubernetes + AWS Example)
# 1. Define Kubernetes deployment with replicas
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 2
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app
image: my-image:latest
readinessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
# 2. Setup AWS Route 53 failover routing policy
# Primary endpoint: app-primary.example.com
# Secondary endpoint: app-secondary.example.com
# 3. Deploy Prometheus and Alertmanager
kubectl apply -f prometheus-stack.yaml
# 4. Create Lambda to trigger failover on alert
# Use AWS SDK to switch Route 53 DNS on alert
5. Real-World Use Cases
Use Case 1: SaaS Multi-Tenant Platform
- Scenario: An e-commerce platform uses failover to route traffic between AWS regions during outages.
- Benefit: Zero downtime, consistent customer experience.
Use Case 2: Financial Institution
- Scenario: Failover between active and standby PostgreSQL databases.
- Benefit: Ensures compliance with SLAs for transactional integrity.
Use Case 3: CI/CD Pipeline Resilience
- Scenario: Failover of a Jenkins master node to a standby instance.
- Benefit: Avoid disruption in build/deploy workflows.
Use Case 4: API Gateway Failover
- Scenario: Cloud-based API gateway redirects traffic to a standby microservice cluster.
- Benefit: Maintains uptime during microservice crashes.
6. Benefits & Limitations
Key Advantages
- ✅ High availability and system resilience
- ✅ Faster disaster recovery (low RTO/RPO)
- ✅ Automatic response to failures
- ✅ Essential for regulatory compliance (e.g., ISO 27001, HIPAA)
Common Challenges or Limitations
- ❌ Complexity in configuration and orchestration
- ❌ Higher infrastructure cost due to redundancy
- ❌ Split-brain issues in database failover
- ❌ Requires continuous testing and monitoring
7. Best Practices & Recommendations
Security Tips
- Encrypt standby data and inter-node traffic
- Secure API triggers (e.g., IAM roles for Lambda)
- Monitor failover attempts for anomaly detection
Performance & Maintenance
- Regularly test failover scenarios (chaos engineering)
- Tune health checks and readiness probes
- Ensure backup replicas are updated and latency-tested
Compliance & Automation
- Log all failover events for audits
- Integrate with SIEM (e.g., Splunk, ELK stack)
- Automate rollback or recovery using Terraform/Ansible
8. Comparison with Alternatives
| Feature | Failover | Load Balancing | Auto-scaling |
|---|---|---|---|
| Handles failure recovery | ✅ | ❌ | ❌ |
| Ensures availability | ✅ | ✅ | ✅ |
| Automates resource scaling | ❌ | ❌ | ✅ |
| Ideal for critical systems | ✅ | ⚠️ | ⚠️ |
When to Choose Failover
- Mission-critical applications
- SLA-driven environments
- Regulatory and security compliance demands
9. Conclusion
Failover is a cornerstone of resilient, secure, and compliant DevSecOps systems. By enabling systems to automatically recover from failures, failover ensures uninterrupted delivery, security posture, and operational excellence.
As systems scale and threats evolve, automated, tested, and secure failover strategies will become even more crucial.