🧭 Introduction & Overview
🔍 What is Disaster Recovery (DR)?
Disaster Recovery (DR) refers to a planned process to restore IT systems, infrastructure, and data after a disruptive event such as:
- Cyberattack (e.g., ransomware)
- Natural disaster (e.g., fire, flood)
- Human error
- System failure

The objective of DR is to ensure business continuity by minimizing downtime, data loss, and service disruption.
🕰️ History / Background
- 1990s–2000s: DR focused on physical backups and cold storage recovery.
- 2010s: Shift towards virtualization, cloud-based DR, and RTO/RPO planning.
- 2020s: Integration of DR into DevOps pipelines with automation, IaC, and Security (DevSecOps).
🚨 Why is DR relevant in DevSecOps?
- Security is a shared responsibility: DR is critical to security and compliance.
- DevSecOps emphasizes resilience, shift-left, and continuous risk mitigation.
- DR is part of security incident response, compliance (e.g., ISO 27001, HIPAA), and zero-trust architecture.
📚 Core Concepts & Terminology
🧩 Key Terms
| Term | Definition |
|---|---|
| RTO | Recovery Time Objective – How quickly services must be restored |
| RPO | Recovery Point Objective – Maximum tolerable data loss |
| Failover | Automatic switching to standby infrastructure |
| Backup | Copy of data used for recovery |
| DRaaS | Disaster Recovery as a Service – Cloud-based DR solution |
| Hot/Warm/Cold Site | Types of standby infrastructure readiness levels |
🔄 DR in the DevSecOps Lifecycle
DevSecOps lifecycle stages and DR touchpoints:
- Plan: Define RTO/RPO; assess threats
- Develop: Embed recovery scripts as code (IaC)
- Build: Automate backup validation via CI
- Test: DR drills integrated into pipelines
- Release: DR automation during blue/green or canary deployments
- Operate: Active failover, monitoring
- Monitor: Security events trigger DR playbooks
🏗️ Architecture & How It Works
🧱 Components
- Backup System: Stores and encrypts data
- Failover Engine: Monitors uptime and triggers recovery
- DR Playbook: Defines response steps
- Orchestrator: Automates provisioning (Terraform, Ansible)
- Monitoring/Alerting: Prometheus, Grafana, ELK stack
- Cloud Infrastructure: AWS/Azure/GCP multi-region support
🔄 Internal Workflow
- Pre-Disaster: Data backups, infra templates, recovery plans in place
- Disaster Detection: Alerting tools identify failure
- Failover Activation: Systems switch to DR site (manual/auto)
- Data Restoration: Backup mounted or restored
- Post-Incident Review: RCA + plan improvement
🖼️ Architecture Diagram (Description)
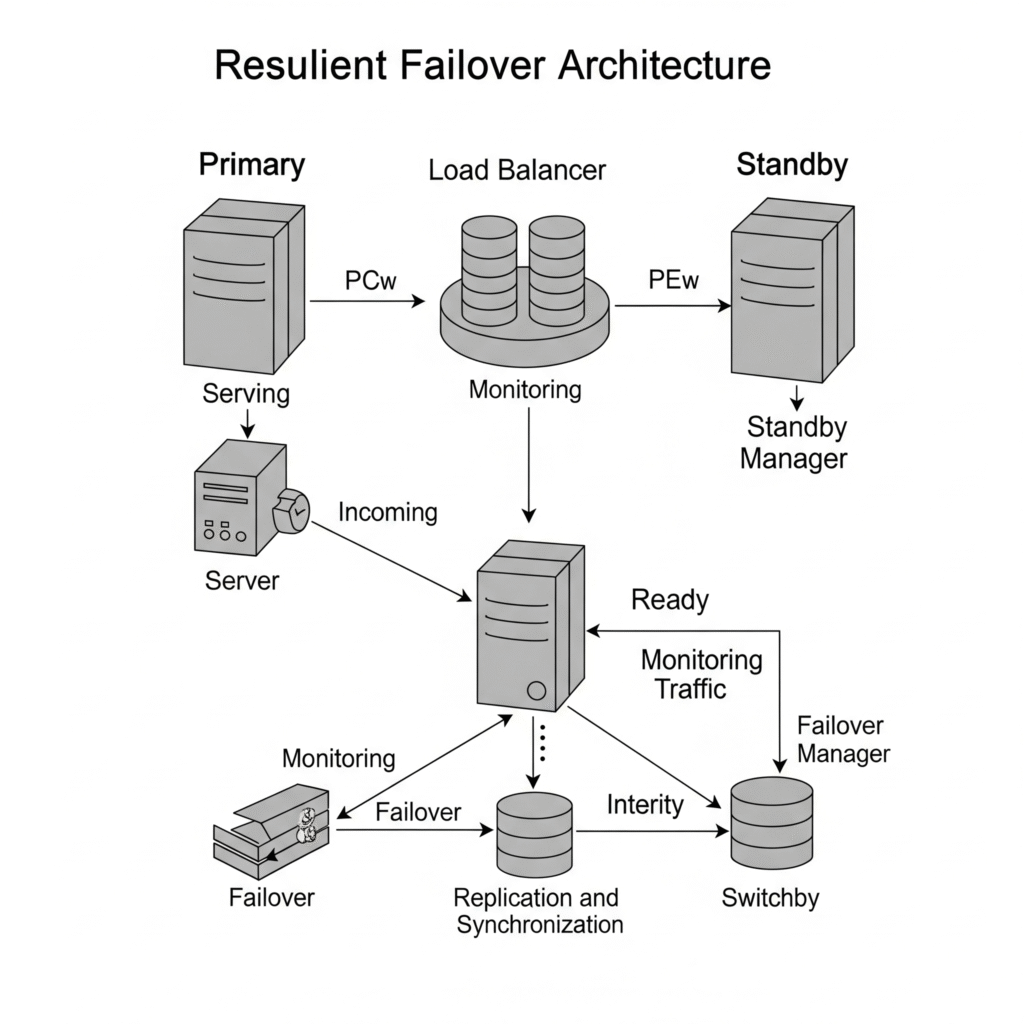
+------------+ +------------+ +--------------+
| Prod App |-----> | Monitoring | -----> | Alert Manager|
+------------+ +------------+ +--------------+
| |
v v
+-------------+ triggers +-------------------------------+
| Backup Vault|<-------------| DR Orchestrator (IaC + DR) |
+-------------+ +-------------------------------+
| |
v v
+------------+ +-------------+
| Cloud DR | <--- Failover ------ | Recovery App|
+------------+ +-------------+
🔗 Integration with DevSecOps Tools
| Tool | Integration Use |
|---|---|
| Jenkins/GitLab CI | DR test pipelines (simulate failure and verify recovery) |
| Terraform/Ansible | Provision DR environment as code |
| AWS/GCP/Azure | DR across regions/zones |
| Vault / SOPS | Secrets recovery |
| Kubernetes | Backup & restore etcd, pods, volumes |
🚀 Installation & Getting Started
🔧 Prerequisites
- Git, Terraform, AWS CLI
- Cloud account (AWS/GCP/Azure)
- Kubernetes cluster (for containerized apps)
- IAM role with EC2/S3/Route53 access
👨💻 Hands-On: Simple DR Setup (AWS Example)
✅ Step 1: Backup Strategy
# Install AWS CLI and configure credentials
aws configure
# Create S3 bucket for backups
aws s3 mb s3://myapp-backup-dr
# Copy backup data
aws s3 cp /data/backup s3://myapp-backup-dr/ --recursive
✅ Step 2: Infrastructure as Code (IaC) – Terraform DR Environment
provider "aws" {
region = "us-west-2"
}
resource "aws_instance" "dr_node" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t2.micro"
tags = {
Name = "DisasterRecoveryNode"
}
}
# Deploy DR environment
terraform init
terraform apply
✅ Step 3: Simulated Failover
- Stop production service
- Restore data from S3
- Point DNS (Route 53) to DR node
aws s3 sync s3://myapp-backup-dr /var/www/html/
🧪 Real-World Use Cases
1. Ransomware Attack Response
- DevSecOps pipeline includes off-site encrypted backups
- CI/CD pipelines trigger restoration on clean nodes
2. Kubernetes Cluster Recovery
- Use
Veleroto back up and restore cluster state - Integrated with GitOps for automatic infra rebuild
3. Multi-region Web App Failover
- Primary in
us-east-1, DR ineu-west-1 - CloudFront and Route 53 used for DNS-based failover
4. Compliance Audit (HIPAA)
- Continuous DR testing included in Jenkins CI jobs
- Logs and evidence exported to auditors
✅ Benefits & Limitations
✅ Key Benefits
- ⏱️ Reduced Downtime (Lower RTO)
- 🔐 Improved Data Security & Compliance
- 🔄 Automated Recovery = Faster Response
- 🧪 Continuous Testing in CI/CD pipelines
⚠️ Limitations
- 💰 Cost of maintaining standby infra
- 🔍 Complex testing and simulations
- 📚 Skill gap in writing reliable DR automation
- 🌐 Cloud vendor lock-in
🛡️ Best Practices & Recommendations
🔒 Security
- Encrypt backups at rest and in transit
- Store DR secrets securely (e.g., HashiCorp Vault)
⚙️ Performance
- Monitor DR site health
- Test failover every sprint or release
✅ Compliance
- Align DR plan with ISO 27001, NIST SP 800-34, HIPAA
- Keep DR audit logs & test results
🤖 Automation Tips
- GitOps + Terraform = Auto-healing infra
- Use
chaos engineeringto simulate failures - Integrate
Slack/MS Teamsfor alert playbooks
⚔️ Comparison with Alternatives
| Strategy | Description | Pros | Cons |
|---|---|---|---|
| Traditional DR | Tape/disk backup, manual restore | Low cost | Slow recovery |
| Cloud-native DR | DRaaS, multi-region, IaC | Fast, scalable | Costly |
| Active-Active DR | Always-on secondary | Zero downtime | High complexity & cost |
| Backup Only | No infra replication | Simple | No failover automation |
When to Choose DR in DevSecOps
Choose DR integration when:
- App availability is critical
- You follow CI/CD & GitOps
- Compliance frameworks mandate DR (SOC2, PCI-DSS)
- You’re cloud-native or hybrid
🔚 Conclusion
Disaster Recovery (DR) in DevSecOps is not optional—it’s a core part of building resilient, secure, and compliant systems. Modern DR leverages IaC, cloud-native tools, and CI/CD pipelines to automate the restoration process, making it faster and more reliable than ever before.