Introduction & Overview
Chaos Engineering is a disciplined approach to testing the resilience of distributed systems by deliberately introducing controlled failures. In Site Reliability Engineering (SRE), it plays a critical role in ensuring systems are robust, scalable, and capable of withstanding unexpected disruptions, aligning with SRE’s focus on reliability and uptime.
What is Chaos Engineering?
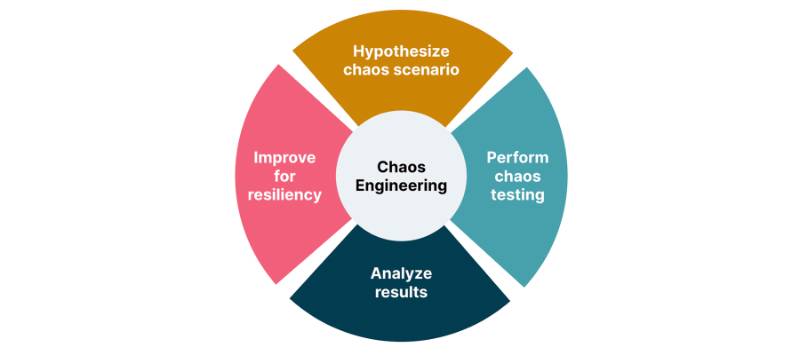
Chaos Engineering involves running experiments to simulate real-world failure scenarios, such as server crashes, network delays, or resource exhaustion, to observe how systems respond. The goal is to identify weaknesses and improve system reliability before failures occur in production.
History or Background
Chaos Engineering emerged at Netflix around 2010 with the creation of Chaos Monkey, a tool that randomly terminated virtual machine instances in production to test system resilience. This approach evolved into a formalized discipline, with tools like Gremlin, LitmusChaos, and Chaos Toolkit gaining traction across industries like finance, e-commerce, and cloud services. The Principles of Chaos Engineering (2014) further standardized the practice, emphasizing controlled experiments and measurable outcomes.
- 2008–2010: Netflix pioneered Chaos Engineering as part of its Simian Army project.
- Chaos Monkey was introduced in 2011 to randomly shut down production instances in Netflix’s AWS cloud environment.
- Gradually evolved into a core SRE/DevOps practice across industries.
- Today, major tools like Gremlin, LitmusChaos, Chaos Toolkit, AWS Fault Injection Simulator, Azure Chaos Studio support chaos testing.
Why is it Relevant in Site Reliability Engineering?
Chaos Engineering aligns with SRE’s core objectives of maintaining high availability and minimizing downtime. Its relevance includes:
- Proactive Issue Detection: Identifies hidden weaknesses before they cause outages.
- Improved MTTR: Exposes failure modes, enabling faster recovery strategies.
- Balancing Speed and Stability: Supports rapid deployments while ensuring reliability.
- Customer Trust: Enhances user experience by preventing unexpected failures.
Core Concepts & Terminology
Chaos Engineering introduces specific concepts and terms essential for its application in SRE.
Key Terms and Definitions
- Blast Radius: The scope of impact caused by a chaos experiment (e.g., a single service or an entire region).
- Steady State: The normal, expected behavior of a system, used as a baseline for experiments.
- Hypothesis: A prediction about how the system will behave under a specific failure condition.
- Chaos Experiment: A controlled test that introduces failures to validate system resilience.
- Failure Injection: The act of deliberately introducing faults, such as latency or resource exhaustion.
| Term | Definition |
|---|---|
| Blast Radius | The scope or impact of a chaos experiment (e.g., single pod, cluster, or full region). |
| Steady State Hypothesis | Normal operating condition of the system, which chaos experiments must validate. |
| Failure Injection | Deliberate introduction of failures (CPU stress, network latency, pod kill, etc.). |
| Resilience | System’s ability to recover and maintain service levels after a failure. |
| Abort Conditions | Pre-defined conditions to stop chaos if it risks critical downtime. |
| GameDay | Pre-planned chaos events run by SRE teams in staging/production to test resilience. |
How it Fits into the Site Reliability Engineering Lifecycle
Chaos Engineering integrates into the SRE lifecycle as follows:
- Design Phase: Identify critical components and potential failure points during system architecture planning.
- Development: Test microservices or APIs under failure conditions in staging environments.
- Deployment: Validate system behavior post-deployment using chaos experiments.
- Monitoring and Incident Response: Use insights from experiments to improve alerting and recovery processes.
- Postmortems: Incorporate findings into blameless postmortems to prevent recurrence of issues.
Architecture & How It Works
Components and Internal Workflow
Chaos Engineering systems typically consist of:
- Chaos Controller: Orchestrates experiments, defining failure types and blast radius.
- Target System: The application, service, or infrastructure under test.
- Monitoring Tools: Collect metrics (e.g., latency, error rates) to evaluate system behavior.
- Experiment Engine: Executes failure scenarios (e.g., terminating pods, injecting latency).
- Rollback Mechanisms: Ensure experiments can be stopped if the blast radius grows unexpectedly.
Workflow:
- Define the steady-state metrics (e.g., 99th percentile latency < 200ms).
- Formulate a hypothesis (e.g., “If a database node fails, the system will failover within 5 seconds”).
- Design an experiment with a controlled blast radius.
- Execute the experiment using a chaos tool.
- Monitor and analyze results, comparing against the steady state.
- Roll back or mitigate if the system deviates unacceptably.
Architecture Diagram (Description)
Note: Since image generation is not supported, here’s a textual description of a typical Chaos Engineering architecture:
- Components: A central Chaos Controller (e.g., Gremlin or Chaos Monkey) connects to a cloud provider (e.g., AWS, GCP) via APIs. The controller interacts with Target Systems (e.g., Kubernetes clusters, EC2 instances). Monitoring tools (e.g., Prometheus, Datadog) feed real-time metrics to the controller. A dashboard visualizes experiment results.
- Flow: Arrows show the controller injecting failures (e.g., CPU stress) into the target system, with monitoring tools collecting data and sending it back for analysis.
- Integration Points: The controller integrates with CI/CD pipelines (e.g., Jenkins) and cloud APIs for dynamic scaling or resource management.
+-------------------------+
| Chaos Orchestrator |
| (LitmusChaos, Gremlin) |
+-----------+-------------+
|
+------------------+------------------+
| |
+----v-----+ +-----v----+
| Failure | | Monitoring|
| Injection| | & Logging |
| Agents | | (Prom, ELK|
+----+-----+ +-----+----+
| |
+----------- System Under Test -------+
(Pods, VMs, APIs, DBs)
Integration Points with CI/CD or Cloud Tools
- CI/CD: Chaos experiments can be embedded in pipelines using tools like Jenkins or GitLab CI to test deployments in staging or production-like environments.
- Cloud Tools: Integrates with AWS Fault Injection Simulator, Azure Chaos Studio, or Kubernetes-native tools like LitmusChaos for cloud-native environments.
- Monitoring: Connects to observability platforms (e.g., Prometheus, Grafana) to track metrics during experiments.
Installation & Getting Started
Basic Setup or Prerequisites
To set up a Chaos Engineering environment:
- Infrastructure: A cloud environment (AWS, GCP, Azure) or Kubernetes cluster.
- Tools: Choose a chaos tool (e.g., Chaos Monkey, Gremlin, LitmusChaos).
- Monitoring: Install observability tools (e.g., Prometheus, Grafana, Datadog).
- Permissions: Ensure API access to the cloud provider or Kubernetes cluster.
- Backup: Set up rollback mechanisms to halt experiments if needed.
Hands-on: Step-by-Step Beginner-Friendly Setup Guide
This guide uses LitmusChaos, a Kubernetes-native chaos engineering tool, for a beginner-friendly setup.
- Install LitmusChaos on Kubernetes:
- Ensure you have a Kubernetes cluster (e.g., Minikube or EKS).
- Install the LitmusChaos Operator:
kubectl apply -f https://litmuschaos.github.io/litmus/2.0.0/litmus-2.0.0.yaml- Verify installation:
kubectl get pods -n litmus2. Set Up Monitoring:
- Install Prometheus and Grafana for observability:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm install prometheus prometheus-community/prometheus
helm install grafana grafana/grafana3. Create a Chaos Experiment:
- Define a chaos experiment (e.g., pod deletion) using a ChaosEngine manifest:
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: pod-delete-example
namespace: default
spec:
appinfo:
appns: default
applabel: app=nginx
chaosServiceAccount: litmus-admin
experiments:
- name: pod-delete
spec:
probe: []- Apply the experiment:
kubectl apply -f chaosengine.yaml4. Monitor and Analyze:
- Access the Grafana dashboard to view metrics like pod uptime or latency.
- Check experiment results:
kubectl describe chaosresult pod-delete-example-pod-delete -n default5. Rollback (if needed):
- Stop the experiment:
kubectl delete chaosengine pod-delete-example -n defaultReal-World Use Cases
Chaos Engineering is applied in various SRE scenarios to enhance system reliability. Below are four real-world examples:
- E-commerce Platform (High Traffic Resilience):
- Scenario: An e-commerce platform prepares for Black Friday traffic spikes.
- Chaos Experiment: Simulate a 50% increase in latency for the payment service.
- Outcome: Identifies that the payment service fails to scale, leading to auto-scaling rule adjustments.
2. Financial Services (Database Failover):
- Scenario: A banking application requires zero downtime during database maintenance.
- Chaos Experiment: Terminate a primary database node to test failover.
- Outcome: Exposes a misconfigured failover mechanism, prompting configuration fixes.
3. Streaming Service (Network Partition):
- Scenario: A video streaming service must handle network partitions between regions.
- Chaos Experiment: Introduce network partitioning between two AWS regions.
- Outcome: Reveals latency issues in cross-region replication, leading to caching improvements.
4. Healthcare (API Reliability):
- Scenario: A telemedicine platform needs reliable API endpoints for patient data.
- Chaos Experiment: Inject HTTP 500 errors into the API gateway.
- Outcome: Identifies insufficient retry logic, improving client-side resilience.
Industry-Specific Insight: In finance and healthcare, Chaos Engineering ensures compliance with strict uptime requirements (e.g., 99.999% availability) by validating failover and redundancy mechanisms.
Benefits & Limitations
Key Advantages
- Proactive Resilience: Identifies weaknesses before they impact users.
- Improved Recovery: Reduces MTTR by exposing failure modes.
- Scalability Testing: Validates system behavior under stress (e.g., traffic spikes).
- Team Confidence: Builds trust in system reliability through repeatable experiments.
Common Challenges or Limitations
- Blast Radius Control: Uncontrolled experiments can cause production outages.
- Complexity: Requires deep system knowledge to design effective experiments.
- Resource Intensive: Experiments may consume significant compute or network resources.
- Cultural Resistance: Teams may resist introducing failures in production.
Best Practices & Recommendations
Security Tips
- Restrict chaos experiments to specific namespaces or environments using RBAC.
- Use authentication for chaos tools to prevent unauthorized access.
- Log all experiments for auditability, especially in regulated industries.
Performance
- Start with small blast radii (e.g., single pod or service) to minimize risk.
- Schedule experiments during low-traffic periods initially.
- Use monitoring to detect performance degradation in real time.
Maintenance
- Regularly update chaos tools to leverage new features and security patches.
- Document experiment results to track improvements over time.
- Integrate chaos experiments into CI/CD pipelines for continuous validation.
Compliance Alignment
- Align experiments with compliance requirements (e.g., SOC 2, HIPAA) by focusing on availability and data integrity.
- Use chaos experiments to validate disaster recovery plans required by regulations.
Automation Ideas
- Automate experiment scheduling using cron jobs or CI/CD triggers.
- Use chaos-as-code (e.g., LitmusChaos YAML manifests) for reproducible experiments.
- Integrate with observability tools to automate result analysis.
Comparison with Alternatives
Chaos Engineering is one of several approaches to improve system reliability. Below is a table comparing it with alternatives:
| Approach | Description | Pros | Cons | When to Use |
|---|---|---|---|---|
| Chaos Engineering | Injects controlled failures to test resilience | Proactive, realistic failure simulation | Risk of outages, complex setup | For distributed systems with high reliability needs |
| Load Testing | Simulates high user traffic | Tests scalability, easy to implement | Limited to traffic scenarios, not failure modes | For performance benchmarking |
| Fault Tolerance Testing | Tests specific components in isolation | Simple, low risk | Limited scope, misses system-wide issues | For component-level validation |
| Disaster Recovery Testing | Simulates full system outages | Validates recovery plans | Resource-intensive, infrequent | For compliance or annual audits |
When to Choose Chaos Engineering:
- Use Chaos Engineering for complex, distributed systems where interdependencies are critical (e.g., microservices, cloud-native apps).
- Prefer load testing for performance optimization or disaster recovery testing for compliance-driven scenarios.
Conclusion
Chaos Engineering is a powerful practice for SRE teams to build resilient systems by proactively identifying and mitigating failure points. By integrating with modern cloud and CI/CD tools, it enables teams to balance rapid innovation with high reliability. As systems grow more distributed, Chaos Engineering will become increasingly vital, with trends like AI-driven chaos experiments and chaos-as-code gaining traction.
Next Steps:
- Start with small, controlled experiments in non-production environments.
- Explore tools like LitmusChaos, Gremlin, or AWS Fault Injection Simulator.
- Join communities like the Chaos Engineering Slack or CNCF Chaos Engineering SIG.
Resources:
- Official Chaos Engineering Principles: https://principlesofchaos.org
- LitmusChaos Documentation: https://docs.litmuschaos.io
- Gremlin Documentation: https://www.gremlin.com/docs
- AWS Fault Injection Simulator: https://aws.amazon.com/fis/