Introduction & Overview
A reverse proxy is a critical component in modern web architectures, acting as an intermediary between clients and backend servers. In Site Reliability Engineering (SRE), reverse proxies enhance system reliability, scalability, and security by managing traffic, load balancing, and enforcing policies. This tutorial provides an in-depth exploration of reverse proxies, their architecture, setup, use cases, and best practices tailored for SRE professionals.
What is a Reverse Proxy?
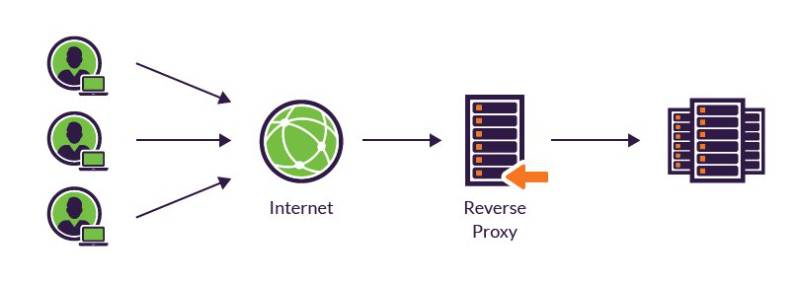
A reverse proxy is a server that sits between client devices (e.g., browsers, mobile apps) and backend servers, forwarding client requests to the appropriate server and returning the server’s response to the client. Unlike a forward proxy, which acts on behalf of clients, a reverse proxy represents the server infrastructure.
- Key Functions:
- Distributes incoming traffic across multiple backend servers (load balancing).
- Provides caching to reduce server load.
- Enhances security through SSL termination, rate limiting, and request filtering.
- Abstracts backend infrastructure for seamless scaling and maintenance.
History or Background
The concept of reverse proxies emerged in the late 1990s with the growth of the internet and the need for scalable web architectures. Early web servers like Apache introduced modules (e.g., mod_proxy) to handle reverse proxying. Tools like Nginx (2004) and HAProxy (2001) later popularized dedicated reverse proxy solutions, offering high performance and configurability. In SRE, reverse proxies became integral for managing microservices, cloud-native applications, and global traffic routing.
- 1990s – Apache introduced proxy modules to manage backend routing.
- 2000s – With the growth of high-traffic web apps, tools like Squid, Nginx, HAProxy became popular for load balancing and caching.
- 2010s onwards – Cloud-native SRE practices integrated reverse proxies into Kubernetes ingress controllers, service meshes (like Envoy, Istio), and modern CI/CD pipelines.
Why is it Relevant in Site Reliability Engineering?
Reverse proxies align with SRE principles of reliability, scalability, and automation:
- Reliability: Ensures high availability by distributing traffic and handling failover.
- Scalability: Enables horizontal scaling by load balancing across servers.
- Automation: Integrates with CI/CD pipelines and cloud orchestration tools.
- Observability: Facilitates monitoring and logging of traffic patterns.
- Security: Protects backend services from direct exposure to the internet.
Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| Reverse Proxy | A server that forwards client requests to backend servers and returns responses. |
| Load Balancing | Distributing incoming requests across multiple servers to optimize resource use. |
| SSL Termination | Decrypting HTTPS traffic at the proxy to simplify backend server configuration. |
| Caching | Storing responses to reduce backend server load and improve response times. |
| Upstream Server | Backend server that processes requests forwarded by the reverse proxy. |
| Health Check | Periodic checks to ensure upstream servers are operational. |
How It Fits into the SRE Lifecycle
In the SRE lifecycle, reverse proxies contribute to:
- Design: Architecting scalable and secure systems.
- Deployment: Integrating with CI/CD for automated updates.
- Monitoring: Collecting metrics (e.g., latency, error rates) for observability.
- Incident Response: Mitigating attacks (e.g., DDoS) via rate limiting and filtering.
- Postmortems: Analyzing traffic logs to identify failure points.
Architecture & How It Works
Components and Internal Workflow
A reverse proxy system typically includes:
- Listener: Accepts incoming client connections (e.g., HTTP/HTTPS on port 80/443).
- Request Handler: Processes requests, applying rules for routing, caching, or filtering.
- Load Balancer: Distributes requests to upstream servers based on algorithms (e.g., round-robin, least connections).
- Cache Store: Stores frequently accessed responses.
- Health Monitor: Checks upstream server availability.
- Logging/Metrics: Records request details for monitoring and debugging.
Workflow:
- Client sends a request to the reverse proxy.
- The proxy authenticates the request (e.g., validates tokens, checks rate limits).
- The proxy selects an upstream server based on load balancing rules.
- The request is forwarded, and the proxy may cache the response.
- The proxy returns the server’s response to the client.
Architecture Diagram
Below is a textual description of a typical reverse proxy architecture (as images cannot be embedded):
[Internet]
|
v
[Reverse Proxy]
|--> Listener (Port 80/443)
|--> Request Handler (Routing, Filtering, Caching)
|--> Load Balancer (Round-Robin, Least Connections)
|--> Health Monitor
|--> Logging/Metrics
|
v
[Upstream Servers]
|--> Server 1 (e.g., Web App)
|--> Server 2 (e.g., API)
|--> Server 3 (e.g., Database)
- Clients connect to the reverse proxy via the internet.
- The Reverse Proxy routes requests to Upstream Servers based on configuration.
- Monitoring Tools (e.g., Prometheus) collect metrics from the proxy.
- CI/CD Tools update proxy configurations or upstream server deployments.
Integration Points with CI/CD or Cloud Tools
- CI/CD: Tools like Jenkins or GitLab CI/CD automate reverse proxy configuration updates (e.g., Nginx config files) during deployments.
- Cloud Tools:
- AWS: Elastic Load Balancer (ELB) or Application Load Balancer (ALB) acts as a reverse proxy.
- GCP: Cloud Load Balancing integrates with Kubernetes Ingress.
- Kubernetes: Nginx Ingress Controller serves as a reverse proxy for microservices.
- Monitoring: Integrates with Prometheus, Grafana, or ELK Stack for traffic analytics.
Installation & Getting Started
Basic Setup or Prerequisites
To set up an Nginx reverse proxy:
- OS: Linux (e.g., Ubuntu 20.04) or any system supporting Nginx.
- Software: Nginx (open-source, version 1.18+ recommended).
- Permissions: Root or sudo access for installation and configuration.
- Network: Ensure ports 80/443 are open and firewall rules allow traffic.
Hands-on: Step-by-Step Beginner-Friendly Setup Guide
This guide sets up Nginx as a reverse proxy on Ubuntu to route traffic to two backend servers.
- Install Nginx:
sudo apt update
sudo apt install nginx -y2. Start and Enable Nginx:
sudo systemctl start nginx
sudo systemctl enable nginx3. Configure Reverse Proxy:
Create a new configuration file at /etc/nginx/sites-available/reverse-proxy.conf:
server {
listen 80;
server_name example.com;
location / {
proxy_pass http://backend_pool;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
upstream backend_pool {
server 192.168.1.10:8080; # Backend Server 1
server 192.168.1.11:8080; # Backend Server 2
}- Replace
example.comwith your domain or server IP. - Replace backend server IPs with your actual server IPs.
4. Enable the Configuration:
sudo ln -s /etc/nginx/sites-available/reverse-proxy.conf /etc/nginx/sites-enabled/5. Test and Reload Nginx:
sudo nginx -t
sudo systemctl reload nginx6. Verify Setup:
Access http://example.com to confirm requests are routed to backend servers.
Real-World Use Cases
Scenario 1: Load Balancing for High Availability
A global e-commerce platform uses Nginx as a reverse proxy to distribute traffic across multiple application servers in different regions. This ensures low latency and failover if one server goes down.
Scenario 2: SSL Termination for Microservices
A fintech company uses HAProxy to terminate SSL connections at the proxy layer, simplifying certificate management for microservices running in Kubernetes.
Scenario 3: Caching for Performance
A media streaming service employs Varnish Cache as a reverse proxy to cache video metadata, reducing backend database load and improving response times.
Scenario 4: Security and Rate Limiting
A SaaS provider uses AWS ALB as a reverse proxy to enforce rate limiting and block malicious IPs, protecting backend APIs from DDoS attacks.
Industry-Specific Example
- Healthcare: A hospital’s patient portal uses a reverse proxy to route traffic to HIPAA-compliant servers, ensuring secure data access and load balancing during peak usage.
Benefits & Limitations
Key Advantages
- Scalability: Distributes load across servers, enabling horizontal scaling.
- Security: Hides backend servers, mitigates DDoS, and supports SSL termination.
- Performance: Caching and compression reduce latency and server load.
- Flexibility: Supports custom routing rules and integration with cloud platforms.
Common Challenges or Limitations
| Challenge | Description |
|---|---|
| Single Point of Failure | If the proxy fails, all traffic is disrupted unless high availability is configured. |
| Configuration Complexity | Managing complex routing rules can be error-prone. |
| Latency Overhead | Adds a slight delay due to request processing. |
| Resource Usage | High traffic volumes may require powerful proxy servers. |
Best Practices & Recommendations
Security Tips
- Enable HTTPS with strong ciphers and redirect HTTP to HTTPS.
- Implement rate limiting to prevent abuse:
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=10r/s;
server {
location / {
limit_req zone=mylimit burst=20;
}
}- Use Web Application Firewall (WAF) rules to filter malicious requests.
Performance
- Enable caching for static assets:
location /static/ {
proxy_cache my_cache;
proxy_cache_valid 200 1h;
proxy_pass http://backend_pool;
}- Use keepalive connections to reduce overhead:
upstream backend_pool {
server 192.168.1.10:8080;
keepalive 32;
}Maintenance
- Regularly update proxy software to patch vulnerabilities.
- Monitor metrics (e.g., request rate, latency) using tools like Prometheus.
- Automate configuration updates via CI/CD pipelines.
Compliance Alignment
- Ensure logging complies with regulations (e.g., GDPR, HIPAA) by anonymizing sensitive data.
- Use audit logs to track configuration changes.
Automation Ideas
- Use Ansible or Terraform to manage proxy configurations.
- Integrate with Kubernetes Ingress for dynamic scaling.
Comparison with Alternatives
| Feature/Tool | Reverse Proxy (Nginx/HAProxy) | API Gateway (e.g., Kong) | Cloud Load Balancer (e.g., AWS ALB) |
|---|---|---|---|
| Purpose | General-purpose traffic routing | API-specific management | Cloud-native load balancing |
| Customization | Highly configurable | Moderate, API-focused | Limited by cloud provider |
| Cost | Open-source, low cost | Free or paid tiers | Pay-per-use |
| SRE Use Case | Load balancing, caching | API versioning, auth | Autoscaling, cloud integration |
When to Choose a Reverse Proxy
- Use for general-purpose traffic management, caching, or simple load balancing.
- Prefer API gateways for complex API orchestration.
- Choose cloud load balancers for fully managed, cloud-native solutions.
Conclusion
Reverse proxies are indispensable in SRE for building reliable, scalable, and secure systems. They simplify traffic management, enhance performance, and integrate seamlessly with modern DevOps tools. As cloud-native architectures and microservices grow, reverse proxies will evolve with features like AI-driven traffic routing and enhanced observability.
Next Steps:
- Experiment with Nginx or HAProxy in a test environment.
- Explore cloud-native proxies like AWS ALB or Kubernetes Ingress.
- Join communities like the Nginx forum or SRE Slack groups.
Resources:
- Nginx Official Documentation
- HAProxy Documentation
- SRE Book by Google