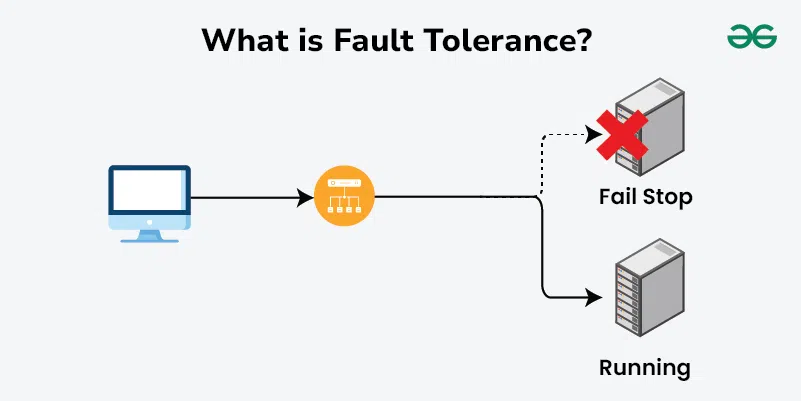
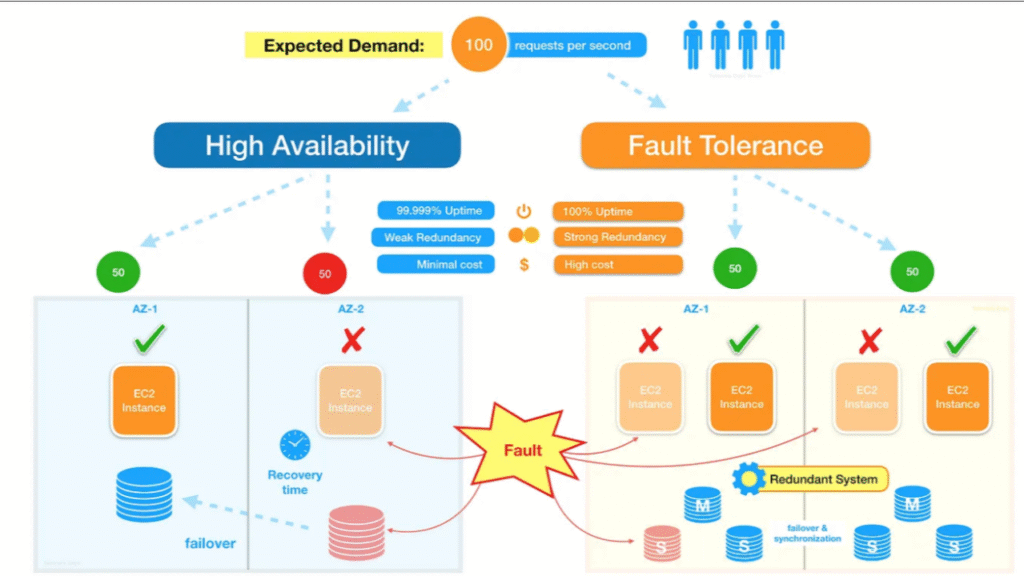
Fault tolerance is a system’s ability to keep meeting its SLOs despite expected failures—machines dying, networks flaking, processes crashing, disks filling—without human intervention. It’s the practical outcome of designing for failure: the system either continues normally or degrades gracefully when parts break.
How it differs from related terms
- Redundancy: the means (extra components/paths).
- High availability: the result (little downtime).
- Resilience: broader ability to absorb, adapt, and recover (includes human/ops).
What “good” fault tolerance looks like
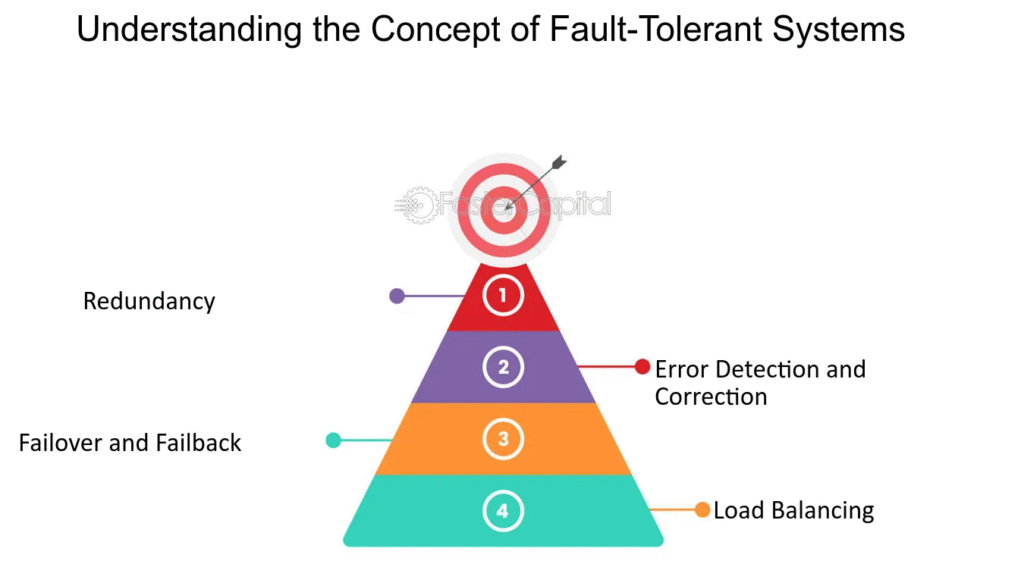
- No single points of failure across failure domains (process → node → AZ → region).
- Automatic detection and recovery (health checks, failover, restarts).
- Predictable degradation (shed load, read-only mode) instead of hard outages.
- Sufficient spare capacity (N+1/N+M) to absorb losses.
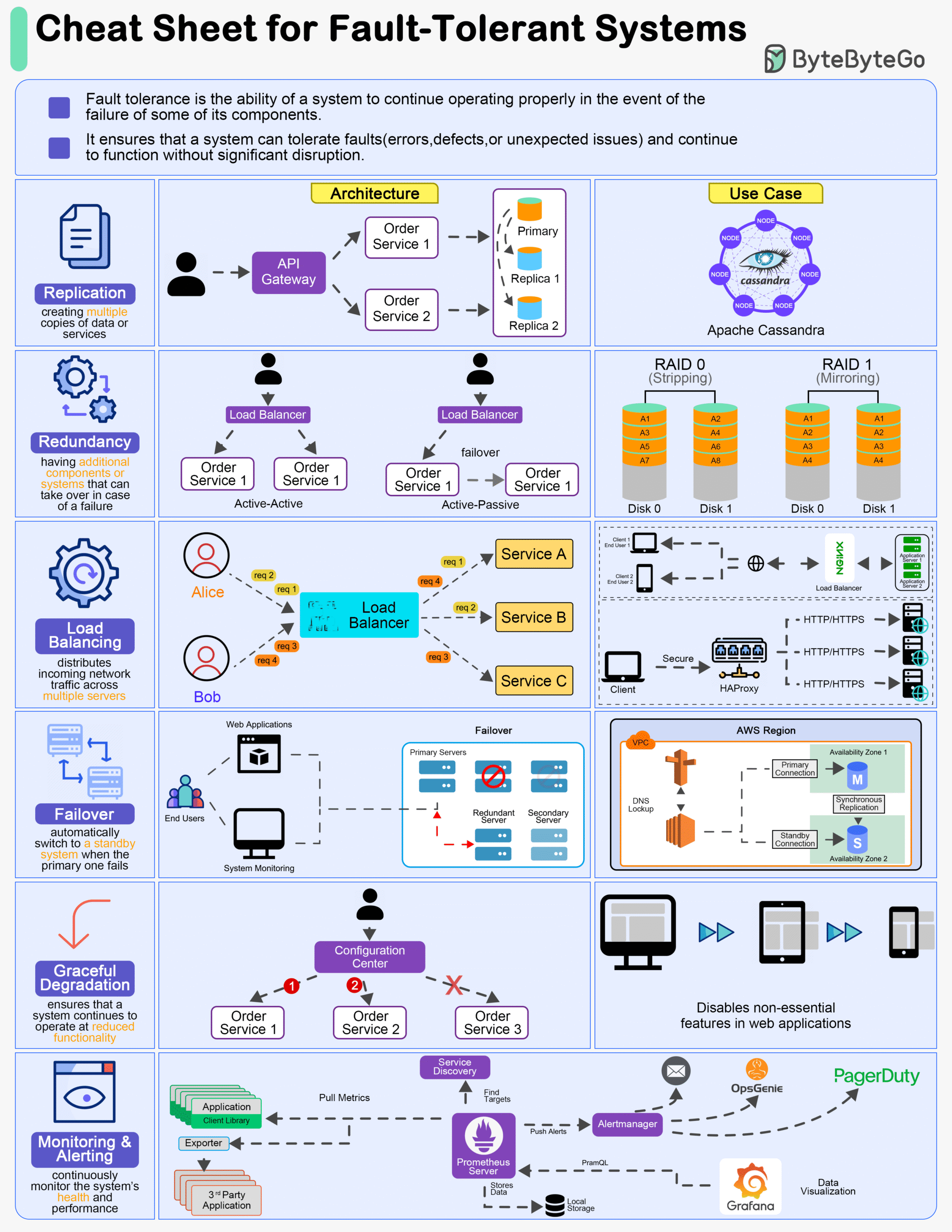
Core techniques
- Redundancy & isolation: multi-replica services, spread across AZs; bulkheads to stop blast radius.
- Automated failover: leader election, health-checked load balancing, fast DNS/LB re-routing.
- Idempotency + retries with backoff/jitter; timeouts & circuit breakers to avoid cascading failure.
- Quorum/replication: e.g., Raft/Paxos, Kafka RF≥3 with
min.insync.replicas=2. - Data durability: snapshots, multi-AZ/region replicas, erasure coding.
- Graceful degradation: feature flags to disable non-critical work, serve cached results, partial results.
- Self-healing: auto-restart/replace (Kubernetes controllers, ASGs).
What to measure
- SLIs: availability, latency, error rate (per AZ/region—not just global).
- MTTR & failover time (how fast a healthy replica takes over).
- Redundancy health: quorum size, ISR status, replication lag.
- Headroom after failure: can you meet SLO with one node/AZ down?
How to verify (continuously)
- Game days / chaos tests: kill nodes, cut an AZ, block a dependency; confirm service stays within SLO and alerts are actionable.
- Runbooks & drills: rehearse promotions, restores, and traffic shifts.
- Alert on loss of tolerance: e.g., quorum at risk, only 1 AZ serving.
Common pitfalls
- Hidden SPOFs: shared DB, cache, NAT, or CI/CD path behind “redundant” apps.
- Correlated failures: all replicas in one AZ/version; dependency coupling.
- Insufficient capacity: N replicas but no spare to handle failover load.
- Unbounded retries: amplify an incident; always pair with timeouts/circuit breakers.

Concrete patterns (AWS/EKS flavored)
- Stateless services: 3+ replicas, PDBs, Pod Topology Spread across 3 AZs; ALB/NLB across subnets in all AZs; HPA with spare headroom.
- Stateful stores: RDS/Aurora Multi-AZ + tested failover; Kafka/MSK RF≥3 with rack-aware placement; Redis/ElastiCache with multi-AZ and auto-failover.
- Global stance: active-active or active-passive across regions for tier-1 APIs; Route 53 health-check failover; S3 versioning + cross-region replication where needed.
Rule of thumb: design for one unit down (node/AZ) without breaching SLOs, test it regularly, and alert when you lose that safety margin. If you share your current topology/SLOs, I can map each tier to specific configs (k8s YAML + AWS settings) to reach concrete fault-tolerance targets.
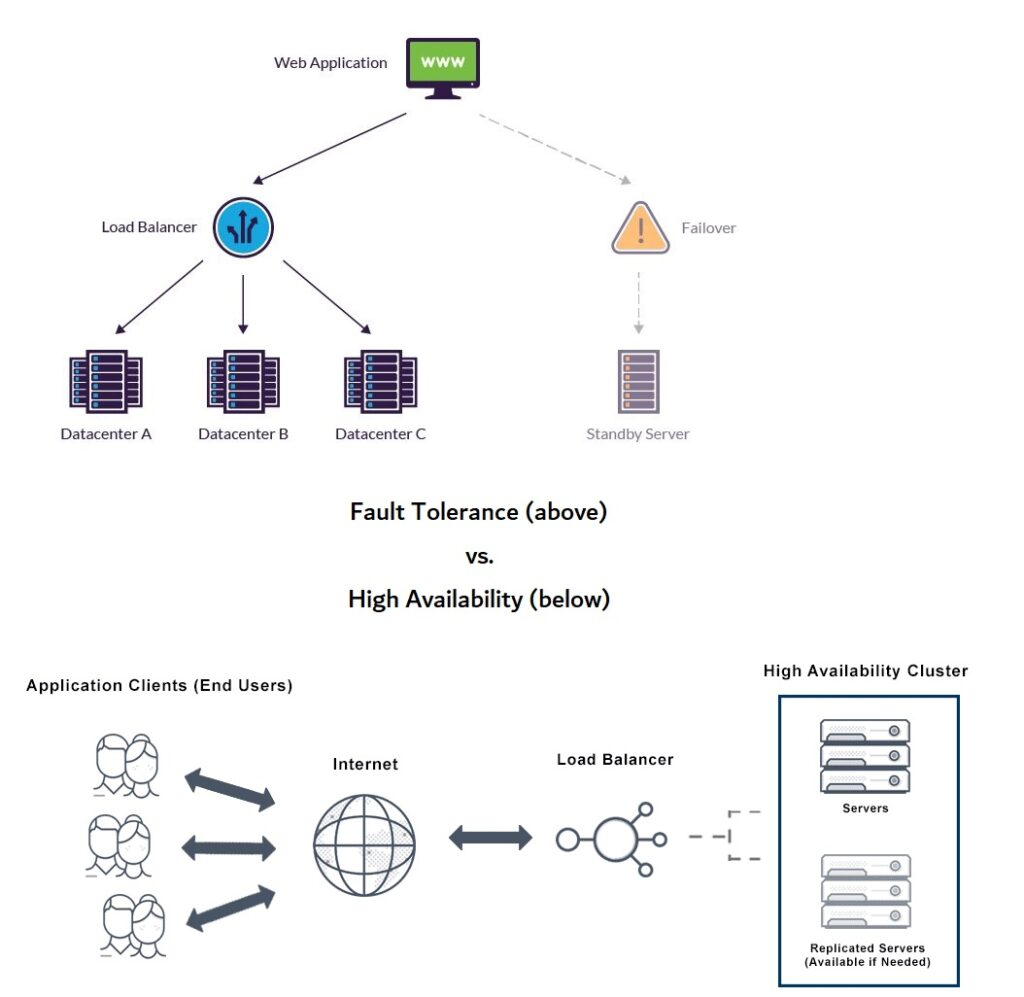
Fault tolerance Vs High Availability