Introduction & Overview
In the fast-evolving landscape of software development and IT operations, DevOps and Site Reliability Engineering (SRE) have emerged as pivotal methodologies to ensure rapid, reliable, and scalable software delivery. Both approaches aim to bridge the gap between development and operations, but they differ in focus, execution, and philosophy. This tutorial provides an in-depth exploration of DevOps and SRE, focusing on their roles within the context of Site Reliability Engineering. It is designed for technical readers, including developers, operations engineers, and SRE practitioners, to understand their core concepts, practical applications, and how they complement each other.
What is DevOps vs. SRE?
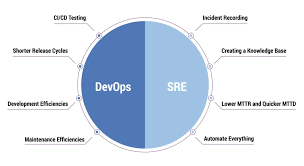
- DevOps: A cultural and technical movement that fosters collaboration between development and operations teams to automate and streamline the software development lifecycle (SDLC) for faster, more reliable releases. It emphasizes continuous integration, continuous delivery (CI/CD), and automation to reduce silos and enhance agility.
- SRE: A discipline pioneered by Google that applies software engineering principles to IT operations, focusing on system reliability, scalability, and performance. SREs use automation, monitoring, and service level objectives (SLOs) to ensure systems remain stable while supporting rapid development.
- Key Difference: DevOps is a broad philosophy focusing on the “what” (collaboration and automation across the SDLC), while SRE is a prescriptive implementation focusing on the “how” (engineering reliable systems with measurable metrics).
History or Background
- DevOps: Originated around 2008–2009, sparked by Patrick Debois and Andrew Shafer, who sought to address the inefficiencies of traditional siloed development and operations teams. The term “DevOps” (Development + Operations) was coined to promote a culture of shared responsibility. The rise of cloud computing and agile methodologies further fueled its adoption.
- SRE: Introduced by Google in 2003 by Ben Treynor Sloss to manage the reliability of its massive-scale infrastructure (e.g., Gmail, Search). SRE evolved as a way to apply software engineering to operations, ensuring high availability amidst frequent updates. The publication of Google’s Site Reliability Engineering book in 2016 popularized the practice.
- Evolution: Both methodologies emerged to address the complexity of modern software systems, with DevOps focusing on cultural shifts and SRE on technical rigor. They are not mutually exclusive but complementary, with SRE often described as “a specific implementation of DevOps.”
Why is it Relevant in Site Reliability Engineering?
- SRE Context: SRE relies on DevOps principles like automation and collaboration but adds a focus on reliability through metrics like Service Level Indicators (SLIs) and SLOs. DevOps provides the cultural foundation, while SRE operationalizes it with engineering practices.
- Business Impact: In SRE, reliability is paramount, especially for high-traffic systems (e.g., Google, Netflix). DevOps enables rapid feature delivery, but SRE ensures these changes don’t compromise system stability, making both critical for modern enterprises.
- Scalability: As organizations scale, DevOps and SRE ensure systems can handle increased demand while maintaining performance and uptime, aligning with business goals like customer satisfaction and revenue protection.
Core Concepts & Terminology
Key Terms and Definitions
How It Fits into the Site Reliability Engineering Lifecycle
- SRE Lifecycle: Involves planning, building, deploying, monitoring, and incident response. SRE integrates DevOps practices like CI/CD and automation but adds reliability-focused steps:
- Planning: Define SLOs and SLIs to set reliability goals.
- Building: Develop systems with redundancy and fault tolerance.
- Deploying: Use automated CI/CD pipelines, with SRE ensuring deployments don’t violate error budgets.
- Monitoring: Implement observability tools (e.g., Prometheus, Grafana) to track SLIs.
- Incident Response: Use playbooks and blameless postmortems to resolve and learn from incidents.
- DevOps Contribution: Provides the cultural and tooling foundation (e.g., CI/CD, IaC) that SRE builds upon to enforce reliability.
Architecture & How It Works
Components and Internal Workflow
- DevOps Components:
- CI/CD Pipelines: Automate code integration, testing, and deployment (e.g., Jenkins, GitLab CI).
- Infrastructure as Code (IaC): Manage infrastructure via code (e.g., Terraform, Ansible).
- Monitoring Tools: Track application performance (e.g., New Relic, Splunk).
- Collaboration Tools: Facilitate team communication (e.g., Jira, Slack).
- SRE Components:
- Monitoring and Observability: Tools like Prometheus and OpenTelemetry for real-time system insights.
- Automation Scripts: Reduce toil via Python scripts or runbooks.
- Incident Management: Playbooks and tools like PagerDuty for rapid response.
- Chaos Engineering: Tools like Chaos Monkey to test resilience.
- Workflow:
- DevOps: Developers commit code to a repository, triggering CI/CD pipelines for testing and deployment. Operations teams monitor and maintain the environment, with automation reducing manual tasks.
- SRE: Engineers monitor SLIs, enforce SLOs, and automate repetitive tasks. They respond to incidents, analyze root causes, and implement fixes to prevent recurrence, balancing reliability with feature velocity.
Architecture Diagram
Below is a textual description of the architecture diagram for DevOps and SRE integration in a cloud environment:
[Developer] --> [Code Repository (Git)] --> [CI/CD Pipeline (Jenkins/GitLab)]
| |
| v
| [Testing (Unit/Integration)]
| |
| v
| [Staging Environment]
| |
| v
| [Production Environment]
| |
v v
[SRE Monitoring (Prometheus/Grafana)] <--> [Incident Response (PagerDuty)]
| |
v v
[SLI/SLO Tracking] [Chaos Engineering (Chaos Monkey)]
| |
v v
[Error Budget Analysis] [Automated Recovery/Failover]
Explanation:
- Code Flow: Developers push code to a repository, triggering CI/CD pipelines for testing and deployment to staging and production.
- SRE Oversight: SREs monitor production using tools like Prometheus, track SLIs/SLOs, and respond to incidents via PagerDuty. Chaos engineering ensures system resilience.
- Feedback Loop: SREs provide feedback to developers to improve system design, while DevOps automates the deployment pipeline.
Integration Points with CI/CD or Cloud Tools
- CI/CD: DevOps drives CI/CD pipelines (e.g., Jenkins, GitLab CI) to automate builds, tests, and deployments. SREs ensure these pipelines maintain reliability by integrating SLO checks and automated rollbacks.
- Cloud Tools: Both leverage cloud platforms (AWS, Azure, GCP) for scalability. DevOps uses IaC (Terraform) for infrastructure provisioning, while SREs use cloud-native monitoring (e.g., AWS CloudWatch) and auto-scaling.
- Example Integration: SREs might configure a CI/CD pipeline to pause deployments if the error budget is exceeded, ensuring reliability.
Installation & Getting Started
Basic Setup or Prerequisites
- DevOps:
- Tools: Git, Jenkins, Docker, Kubernetes, Terraform, Ansible.
- Skills: Knowledge of CI/CD, scripting (Python/Bash), and cloud platforms.
- Environment: A cloud account (e.g., AWS, Azure) and a code repository (e.g., GitHub).
- SRE:
- Tools: Prometheus, Grafana, PagerDuty, Chaos Monkey, Kubernetes.
- Skills: Software engineering, system administration, monitoring, and incident response.
- Environment: A production system with defined SLIs/SLOs and monitoring infrastructure.
Hands-On: Step-by-Step Beginner-Friendly Setup Guide
Goal: Set up a basic CI/CD pipeline with monitoring for a Node.js application using Jenkins and Prometheus.
- Set Up a Code Repository:
- Create a GitHub repository for a Node.js app.
- Example
app.js:
const express = require('express');
const app = express();
app.get('/', (req, res) => res.send('Hello, SRE!'));
app.listen(3000, () => console.log('Server running on port 3000'));Push to GitHub: git push origin main.
2. Install Jenkins:
- On a cloud VM (e.g., AWS EC2), install Jenkins:
sudo apt update
sudo apt install openjdk-11-jdk
wget -q -O - https://pkg.jenkins.io/debian/jenkins.io.key | sudo apt-key add -
sudo sh -c 'echo deb http://pkg.jenkins.io/debian-stable binary/ > /etc/apt/sources.list.d/jenkins.list'
sudo apt update
sudo apt install jenkins- Access Jenkins at
http://<your-vm-ip>:8080.
3. Configure CI/CD Pipeline:
- In Jenkins, create a new pipeline job.
- Add a
Jenkinsfileto your repository:
pipeline {
agent any
stages {
stage('Build') {
steps {
sh 'npm install'
}
}
stage('Test') {
steps {
sh 'npm test'
}
}
stage('Deploy') {
steps {
sh 'docker build -t my-app .'
sh 'docker run -d -p 3000:3000 my-app'
}
}
}
}- Configure Jenkins to pull from GitHub and trigger builds on commits.
4. Set Up Prometheus for Monitoring:
- Install Prometheus on the same VM:
wget https://github.com/prometheus/prometheus/releases/download/v2.45.0/prometheus-2.45.0.linux-amd64.tar.gz
tar xvfz prometheus-2.45.0.linux-amd64.tar.gz
cd prometheus-2.45.0.linux-amd64
./prometheus --config.file=prometheus.yml- Configure
prometheus.ymlto scrape the Node.js app:
scrape_configs:
- job_name: 'node_app'
static_configs:
- targets: ['localhost:3000']- Access Prometheus at
http://<your-vm-ip>:9090.
5. Define SLOs:
- Example SLO: 99.9% uptime, measured by HTTP request success rate.
- Use Prometheus to track SLIs (e.g.,
http_requests_total).
6. Test the Setup:
- Push a code change to GitHub.
- Verify Jenkins builds and deploys the app.
- Check Prometheus for metrics and ensure SLO compliance.
Real-World Use Cases
- Google (SRE): Google uses SRE to manage its search engine, ensuring 99.99% availability despite billions of daily requests. SREs define SLOs (e.g., <300ms latency) and use tools like Borg (Google’s internal orchestration) and monitoring systems to maintain reliability.
- Netflix (SRE + DevOps): Netflix employs DevOps for CI/CD to deploy new streaming features rapidly and SRE for chaos engineering (Chaos Monkey) to test resilience, ensuring uninterrupted streaming for millions of users.
- Uber (SRE): Uber’s SRE team uses real-time monitoring (Prometheus) and automated failover to handle peak ride requests, maintaining service availability during surges. DevOps teams manage CI/CD pipelines for rapid app updates.
- E-commerce (DevOps): An e-commerce platform uses DevOps to automate deployments of new product features, with SREs ensuring 24/7 uptime during high-traffic events like Black Friday by implementing redundant architectures and monitoring SLIs.
Benefits & Limitations
Key Advantages
Common Challenges or Limitations
- DevOps:
- SRE:
Best Practices & Recommendations
Security Tips
- DevOps: Integrate DevSecOps practices, such as automated security scans in CI/CD pipelines (e.g., Snyk).
- SRE: Implement Zero Trust Architecture and automate vulnerability assessments.
- Both: Use role-based access control (RBAC) in cloud platforms and encrypt sensitive data.
Performance
- DevOps: Optimize CI/CD pipelines with parallel testing and caching to reduce build times.
- SRE: Use predictive analytics (e.g., ML-based anomaly detection) to preempt performance issues.
- Both: Implement auto-scaling in cloud environments to handle traffic spikes.
Maintenance
- DevOps: Regularly update IaC scripts to avoid configuration drift.
- SRE: Maintain up-to-date incident response playbooks and conduct blameless postmortems.
- Both: Use version-controlled monitoring policies (e.g., GitOps with ArgoCD).
Compliance Alignment
- DevOps: Ensure CI/CD pipelines include compliance checks (e.g., GDPR, HIPAA).
- SRE: Align SLOs with regulatory requirements to meet SLAs.
- Both: Document processes for audit trails and use tools like HashiCorp Vault for secrets management.
Automation Ideas
- DevOps: Automate infrastructure provisioning with Terraform and deployment with Kubernetes.
- SRE: Automate toil-heavy tasks (e.g., log rotation) with Python scripts and schedule chaos engineering tests.
- Both: Use GitOps for declarative infrastructure management.
Comparison with Alternatives
- When to Choose DevOps: Opt for DevOps when your organization needs to accelerate development cycles, break silos, or adopt CI/CD and IaC for cloud-native apps.
- When to Choose SRE: Choose SRE for high-traffic systems requiring strict reliability (e.g., e-commerce, streaming) or when error budgets and SLOs are critical.
- Platform Engineering: Best for organizations needing standardized, self-service infrastructure to empower developers without reinventing tools.
Conclusion
DevOps and SRE are complementary methodologies that enhance software delivery and system reliability. DevOps drives cultural collaboration and automation across the SDLC, while SRE applies engineering rigor to ensure production stability. Together, they enable organizations to balance speed and reliability, critical for modern cloud-native systems. Future trends include increased adoption of AI/ML for predictive incident detection, deeper GitOps integration, and broader use of chaos engineering.
Next Steps:
- Experiment with setting up a CI/CD pipeline and monitoring system as outlined in the setup guide.
- Explore SRE practices like defining SLOs or conducting chaos engineering tests.
- Engage with communities for further learning.
Resources: