Introduction & Overview
In Site Reliability Engineering (SRE), ensuring system reliability and availability is paramount. A robust backup strategy is a cornerstone of this discipline, safeguarding data and services against failures, outages, and disasters. This tutorial provides an in-depth exploration of backup strategies within the SRE context, covering their definition, architecture, implementation, and real-world applications. Designed for technical readers, it includes practical steps, diagrams, and best practices to help SREs implement effective backup strategies.
What is a Backup Strategy?
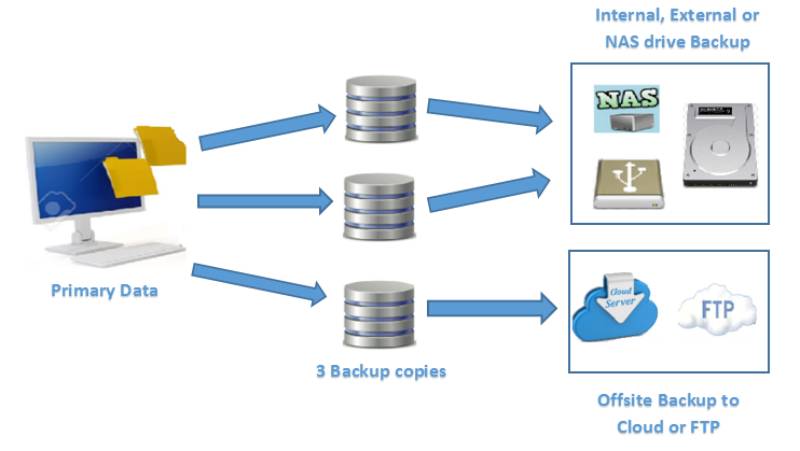
A backup strategy defines the policies, processes, and tools used to create, store, and recover data and system states to ensure continuity and resilience. In SRE, it’s not just about copying data but designing a system that supports high availability, rapid recovery, and minimal data loss, aligning with Service Level Objectives (SLOs).
History or Background
The concept of backups dates back to early computing, where magnetic tapes were used to store data snapshots. As systems grew in complexity, so did backup strategies, evolving from manual processes to automated, cloud-native solutions. Google’s SRE practices, formalized in the early 2000s, emphasized automation and reliability, influencing modern backup strategies to prioritize scalability and fault tolerance. Today, backup strategies integrate with cloud platforms, CI/CD pipelines, and observability tools to meet the demands of distributed systems.
- 1960s–1980s → Backups were tape-based, manual, and often weekly.
- 1990s → Disk-based backups and incremental backups gained popularity.
- 2000s → Virtualization & cloud shifted backups to off-site and on-demand.
- Today (Cloud-native SRE) → Continuous backups, snapshots, and disaster recovery (DR) with automation and Infrastructure as Code (IaC).
Why is it Relevant in Site Reliability Engineering?
Backup strategies are critical in SRE for:
- Minimizing Downtime: Ensuring rapid recovery to meet SLOs for availability (e.g., 99.9% uptime).
- Data Integrity: Protecting against data corruption, human error, or cyberattacks.
- Scalability: Supporting large-scale, distributed systems with minimal manual intervention.
- Customer Trust: Maintaining service reliability to enhance user experience and trust.
Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| Backup | A copy of data or system state stored for recovery purposes. |
| Recovery Point Objective (RPO) | The maximum acceptable data loss, measured as time between backups. |
| Recovery Time Objective (RTO) | The maximum acceptable downtime before recovery. |
| Full Backup | A complete copy of all data at a point in time. |
| Incremental Backup | A copy of only the data changed since the last backup. |
| Differential Backup | A copy of data changed since the last full backup. |
| Replication | Real-time or near-real-time copying of data to another system or location. |
| Error Budget | A metric defining acceptable downtime, guiding backup and recovery efforts. |
How It Fits into the SRE Lifecycle
Backup strategies align with SRE’s focus on reliability and automation:
- Design Phase: Incorporate redundancy and fault tolerance into system architecture.
- Deployment Phase: Integrate backups with CI/CD pipelines for automated snapshotting.
- Monitoring Phase: Use observability tools to monitor backup health and detect failures.
- Incident Response: Enable rapid recovery to minimize RTO and RPO during outages.
- Postmortems: Analyze backup failures to improve processes and automation.
Architecture & How It Works
Components
A backup strategy in SRE typically includes:
- Backup Agent: Software that captures data or system snapshots (e.g., AWS Backup, Veeam).
- Storage Layer: Locations for storing backups (e.g., S3, GCP Cloud Storage, on-premises NAS).
- Scheduler: Automates backup frequency and type (e.g., cron jobs, cloud-native schedulers).
- Recovery Manager: Tools or scripts to restore data/systems from backups.
- Monitoring Tools: Systems like Prometheus or Nagios to track backup success/failure.
Internal Workflow
- Data Identification: Identify critical data and systems requiring backups (e.g., databases, application configs).
- Backup Execution: The backup agent captures data based on predefined schedules (full, incremental, or differential).
- Storage: Backups are encrypted and stored in secure, redundant locations (e.g., multi-region cloud storage).
- Validation: Automated tests verify backup integrity and restorability.
- Recovery: During failures, the recovery manager restores data to meet RPO/RTO targets.
- Monitoring: Observability tools alert SREs to backup failures or anomalies.
Architecture Diagram Description
Below is a textual description of a typical backup strategy architecture (image generation not supported):
[Application Servers] --> [Backup Agent] --> [Scheduler]
| | |
| v v
[Database] [Backup Storage] [Monitoring]
| | |
v v v
[Replication Layer] --> [Multi-Region Storage] --> [Recovery Manager]
- Application Servers/Database: Primary systems generating data.
- Backup Agent: Captures snapshots (e.g., AWS Backup).
- Scheduler: Triggers backups (e.g., cron or AWS EventBridge).
- Backup Storage: Primary storage (e.g., S3 bucket).
- Replication Layer: Mirrors backups to another region for redundancy.
- Multi-Region Storage: Ensures fault tolerance (e.g., S3 Cross-Region Replication).
- Recovery Manager: Restores data during incidents.
- Monitoring: Tracks backup health (e.g., Prometheus).
Integration Points with CI/CD or Cloud Tools
- CI/CD: Backup snapshots can be triggered post-deployment via tools like Jenkins or GitLab CI to capture system states.
- Cloud Tools: AWS Backup integrates with AWS services (EC2, RDS), while GCP’s Persistent Disk Snapshots work with Compute Engine. Kubernetes clusters use Velero for cluster backups.
- Observability: Prometheus/Grafana monitors backup metrics, ensuring SLIs (e.g., backup success rate) align with SLOs.
Installation & Getting Started
Basic Setup or Prerequisites
- Hardware/Software: A server or cloud environment (e.g., AWS, GCP), backup software (e.g., AWS Backup, Velero), and monitoring tools (e.g., Prometheus).
- Permissions: Admin access to configure storage and backup policies.
- Network: Secure connectivity for data transfer (e.g., VPC endpoints, VPN).
- Encryption: Keys for encrypting backups (e.g., AWS KMS).
Hands-On: Step-by-Step Beginner-Friendly Setup Guide
This guide sets up a backup strategy for an AWS-hosted application using AWS Backup.
- Set Up AWS Backup:
- Log in to the AWS Management Console.Navigate to AWS Backup > Create Backup Plan.Define a backup rule (e.g., daily full backups, weekly incremental).
{
"BackupPlanName": "DailyAppBackup",
"Rules": [
{
"RuleName": "DailyFull",
"TargetBackupVault": "AppVault",
"ScheduleExpression": "cron(0 0 * * ? *)",
"Lifecycle": { "DeleteAfterDays": 90 }
}
]
}2. Create a Backup Vault:
- In AWS Backup, create a vault named AppVault.
- Enable encryption using an AWS KMS key.
aws backup create-backup-vault --backup-vault-name AppVault --encryption-key-arn arn:aws:kms:region:account-id:key/key-id3. Assign Resources:
- Tag resources (e.g., EC2 instances, RDS databases) with
Backup=Daily. - In AWS Backup, select resources by tag for the backup plan.
4. Set Up Monitoring:
Use Amazon CloudWatch to monitor backup job status.
aws cloudwatch put-metric-alarm --alarm-name BackupFailure --metric-name BackupJobsFailed --namespace AWS/Backup --threshold 15. Test Recovery:
Simulate a failure and restore from the backup vault.
aws backup start-restore-job --recovery-point-arn arn:aws:backup:region:account-id:recovery-point-id --iam-role-arn arn:aws:iam::account-id:role/BackupRole6. Automate with CI/CD:
Add a backup trigger to your CI/CD pipeline (e.g., Jenkins).
aws backup start-backup-job --backup-vault-name AppVault --resources arn:aws:ec2:region:account-id:instance/instance-idReal-World Use Cases
- E-Commerce Platform:
- Scenario: An e-commerce site uses AWS RDS for its product catalog. A faulty update corrupts the database.
- Application: AWS Backup restores the database to the last incremental backup, minimizing data loss (RPO < 5 minutes).
- Outcome: Customer transactions resume within 30 minutes, meeting the SLO of 99.9% uptime.
- Healthcare Application:
- Scenario: A hospital’s patient management system on Kubernetes experiences a node failure.
- Application: Velero restores the cluster state from a backup stored in S3, ensuring compliance with HIPAA regulations.
- Outcome: Patient data is recovered without breaching privacy standards.
- Financial Services:
- Scenario: A banking app faces a ransomware attack, encrypting critical data.
- Application: Multi-region backups in GCP Cloud Storage allow restoration from an unaffected region.
- Outcome: Rapid recovery prevents financial loss and maintains customer trust.
- Media Streaming Service:
- Scenario: A streaming platform’s content database fails during a peak traffic event.
- Application: Incremental backups and automated failover to a secondary region ensure uninterrupted streaming.
- Outcome: User experience remains seamless, aligning with a 99.99% availability SLO.
Benefits & Limitations
Key Advantages
- Reliability: Ensures data and system availability, meeting SLOs.
- Automation: Reduces manual toil, aligning with SRE principles.
- Scalability: Supports distributed systems with multi-region storage.
- Compliance: Meets regulatory requirements (e.g., GDPR, HIPAA) via encryption and auditing.
Common Challenges or Limitations
- Cost: Storing frequent backups in cloud environments can be expensive.
- Complexity: Managing multi-region replication and recovery workflows requires expertise.
- Backup Overhead: Frequent backups may impact system performance.
- Data Growth: Rapidly growing data volumes can strain backup infrastructure.
Best Practices & Recommendations
Security Tips
- Encrypt Backups: Use tools like AWS KMS or GCP Cloud KMS for data-at-rest encryption.
- Access Control: Implement least-privilege IAM roles for backup operations.
- Audit Trails: Log backup and restore activities using tools like AWS CloudTrail.
Performance
- Optimize Backup Frequency: Balance RPO with system performance (e.g., daily full, hourly incremental).
- Use Compression: Reduce storage costs with tools like gzip or deduplication.
- Monitor Latency: Ensure backup processes don’t degrade application performance.
Maintenance
- Regular Testing: Conduct quarterly disaster recovery drills to validate backups.
- Retention Policies: Define lifecycle rules (e.g., delete backups after 90 days).
- Automation: Use Infrastructure as Code (e.g., Terraform) to manage backup configurations.
Compliance Alignment
- Align with standards like GDPR, HIPAA, or PCI-DSS by ensuring encrypted backups and audit logs.
- Document backup processes for compliance audits.
Automation Ideas
- Integrate backups with CI/CD pipelines for post-deployment snapshots.
- Use serverless functions (e.g., AWS Lambda) to trigger and monitor backups.
- Automate backup validation with scripts to check integrity.
Comparison with Alternatives
| Feature | Backup Strategy (SRE) | Traditional Backup | Cloud-Native Backup Tools |
|---|---|---|---|
| Automation | High (CI/CD, IaC) | Low (Manual) | Medium (Cloud-specific) |
| Scalability | High (Multi-region) | Low (On-premises) | High (Cloud-based) |
| RTO/RPO | Low (Minutes) | High (Hours) | Low (Minutes) |
| Cost | Moderate to High | Low to Moderate | High |
| Use Case | Distributed Systems | Legacy Systems | Cloud-Native Apps |
When to Choose a Backup Strategy in SRE
- Choose SRE Backup Strategy: For cloud-native, distributed systems requiring high availability, automation, and integration with CI/CD.
- Choose Traditional Backup: For small, on-premises systems with limited scalability needs.
- Choose Cloud-Native Tools: For fully managed cloud solutions with minimal configuration but higher costs.
Conclusion
A robust backup strategy is essential for SREs to ensure system reliability, minimize downtime, and protect data integrity. By automating backups, integrating with CI/CD, and leveraging cloud tools, SREs can meet stringent SLOs and enhance customer trust. As systems grow in complexity, future trends like AI-driven backup optimization and zero-trust security will shape the evolution of backup strategies. To get started, explore the resources below and experiment with tools like AWS Backup or Velero in your environment.
Resources
- Official Docs: AWS Backup, Velero
- Communities: SREcon, r/SRE on Reddit