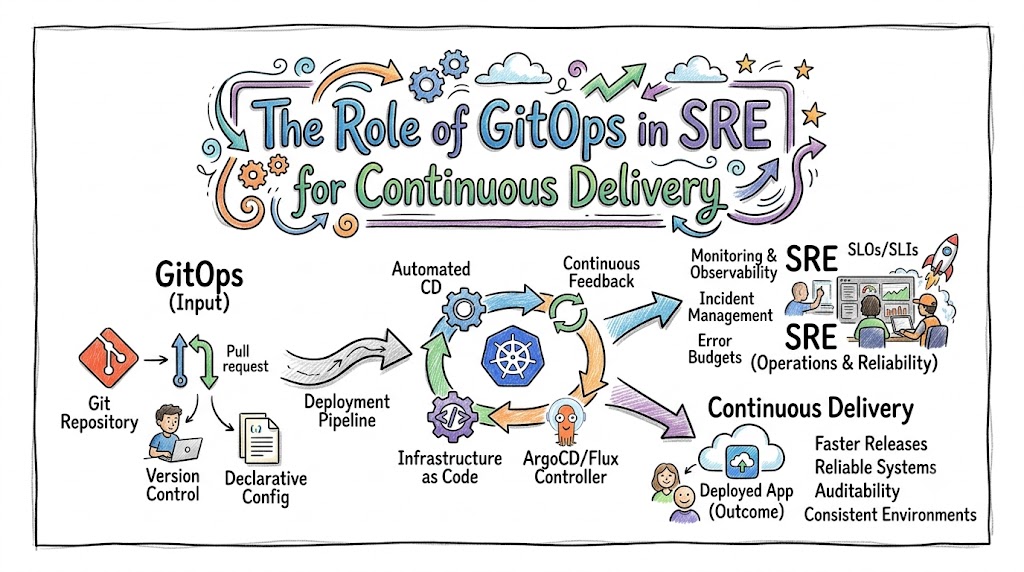
Introduction
Modern software engineering requires rapid deployment cycles and rock-solid system reliability. Because of this demand, organizations frequently struggle to balance the speed of development with production stability. Site Reliability Engineering (SRE) focuses heavily on maintaining uptime and optimizing system performance. However, traditional infrastructure management often introduces human errors and configuration drift into these environments. Fortunately, GitOps provides a declarative, version-controlled approach that perfectly aligns with SRE principles to automate continuous delivery seamlessly.
To bridge this operational gap effectively, teams turn to specialized educational platforms. For instance, Sreschool provides excellent hands-on training to help engineering teams master these modern cloud-native workflows. By using Git as the single source of truth, infrastructure changes go through the exact same automated pipelines as regular application code. Consequently, this methodology eliminates manual interventions and ensures that production environments remain consistent, auditable, and resilient against unexpected failures.
Ultimately, integrating GitOps into an SRE framework changes how organizations handle continuous delivery. This guide explores how declarative configurations, automated reconciliation loops, and collaborative pull requests enhance system reliability. Throughout the following sections, we will break down critical architectural patterns, cultural shifts, and practical roadmaps. Therefore, you will gain a deep understanding of how to build self-healing, highly scalable platform infrastructures.
Key Operational Concepts You Must Know
Declarative Infrastructure and Single Source of Truth
Declarative infrastructure represents a fundamental shift away from manual imperative scripting. Instead of writing sequential commands to build a server, engineers define the desired final state using configuration files. As a result, the system automatically understands what resources it needs to provision. Git acts as the immutable, single source of truth for both your application code and cluster state. Consequently, any modifications to the infrastructure must go through a structured version-control workflow.
This approach offers immense advantages for tracking changes and auditing environments over time. Since every single modification is recorded in Git history, you can easily pinpoint who made a change and why. Furthermore, rollback operations become incredibly trivial because you simply revert to a previous git commit. Therefore, teams avoid the classic problem of configuration drift where environments slowly become inconsistent due to manual hotfixes.
Automated Reconciliation Loops and State Drift Correction
The core engine behind GitOps functionality is the automated reconciliation loop. Software agents continuously monitor the live production environment and compare it directly with the desired state stored in Git. If a developer manually changes a setting in the production cluster, the agent instantly detects this discrepancy. Subsequently, the tool automatically overwrites the unauthorized change to match the configuration repo precisely.
This continuous feedback loop drastically reduces the mean time to repair (MTTR) for infrastructure anomalies. SRE teams no longer need to spend hours troubleshooting silent configuration changes that break applications. Instead, the self-healing mechanism guarantees that the actual state always mirrors the approved repository state. Accordingly, this automation provides a highly stable foundation for running high-availability cloud applications without constant human intervention.
Git-Driven Workflows and Pull Request Automation
Utilizing pull requests for infrastructure modifications introduces a highly collaborative gatekeeping mechanism. When an engineer needs to scale a database or update a network policy, they propose changes via a git branch. Consequently, peers can review the configuration code, run automated validation linting, and discuss architectural impacts before deployment. Once the team approves and merges the pull request, the delivery pipeline triggers automatically.
This shift-left approach to infrastructure management integrates security and quality assurance early in the lifecycle. Automated CI webhooks validate the syntax and security compliance of files before they ever touch production. Therefore, human errors are caught during the review phase rather than causing catastrophic live outages. Ultimately, pull request automation converts operations into a transparent, repeatable, and deeply collaborative software engineering practice.
Platform Implementation vs. Culture — What’s the Real Difference?
Technical Execution and Tooling Integration
Platform implementation focuses heavily on the technical architecture, continuous integration pipelines, and cluster management tools. Engineers spend time configuring webhook listeners, setting up secret management backends, and tuning state reconciliation tools like ArgoCD or Flux. Additionally, this side of operations involves writing reusable Terraform modules, Helm charts, and custom resource definitions. The primary objective is building a robust, automated platform capable of executing deployment commands flawlessly.
However, simply installing these advanced cloud-native tools does not guarantee operational success. Without a structured workflow, teams might bypass the automation and apply manual fixes directly to clusters. Technical implementation provides the necessary machinery, but it requires strict guardrails to prevent configuration fragmentation. Therefore, platform execution must be treated as an ongoing engineering project that continuously evolves alongside application requirements.
Cultural Alignment and Shared Accountability
On the other side of the spectrum lies operational culture, which dictates how humans interact with the platform. A true SRE and GitOps culture breaks down the traditional silos separating development teams from operations engineers. Instead of tossing code over the wall, developers share ownership of the deployment configurations and runtime stability. This collaborative mindset encourages transparency, blameless post-mortems, and a shared commitment to keeping production systems healthy.
When cultural alignment is missing, engineers view automated platforms as bureaucratic obstacles rather than helpful accelerators. Cultivating a healthy engineering culture requires leadership support, comprehensive documentation, and continuous psychological safety. Teams must feel empowered to learn from deployment failures rather than fearing punishment for breaking a pipeline. Thus, culture forms the psychological framework that allows advanced technical tools to succeed over the long haul.
Comparing Technical Implementation and Culture
To visualize how these two domains interact, we can analyze their distinct characteristics across key operational dimensions. While tools provide capabilities, culture determines behavior and ultimate project outcomes.
| Operational Dimension | Platform Implementation (The Machinery) | Organizational Culture (The Mindset) |
| Primary Focus | Tool selection, API integration, and automation scripts. | Shared responsibility, empathy, and continuous learning. |
| Success Metrics | Pipeline speed, cluster utilization, and uptime SLAs. | Deployment confidence, collaboration, and psychological safety. |
| Core Artifacts | YAML files, Helm charts, Jenkinsfiles, and Terraform code. | Post-mortems, playbooks, team values, and feedback loops. |
| Failure Resolution | Automated rollbacks, state reconciliation, and alerting. | Blameless analysis, root-cause identification, and training. |
Real-World Use Cases of Modern Operations
Multi-Region Disaster Recovery and Environment Replication
Imagine a critical banking application suffering a catastrophic cloud provider outage across an entire geographical region. In a traditional infrastructure setup, rebuilding that complex environment from scratch could take days of manual configuration. However, with GitOps, the entire infrastructure state lives as declarative code in a centralized repository. SREs can quickly point a new cluster in a different region to the existing Git repository.
[ Git Repository ] ---> ( ArgoCD / Flux Sync ) ---> [ Replicated Cluster: Region A ]
---> [ Replicated Cluster: Region B ]
As a result, the automated GitOps controller reads the configurations and completely provisions identical networks, security policies, and microservices within minutes. This rapid environment replication capability reduces recovery point objectives (RPO) and recovery time objectives (RTO) significantly. Furthermore, it allows organizations to confidently run identical development, staging, and production environments without manual configuration drift. Consequently, companies can guarantee continuous business availability even during major infrastructure disruptions.
Automated Canary Deployments and Progressive Delivery
Deploying a major software update to millions of users simultaneously carries an immense amount of operational risk. Modern operations teams leverage progressive delivery techniques, such as canary deployments, to mitigate this hazard. When a new container image tag updates in Git, the GitOps controller applies the change to a tiny fraction of production traffic. SRE monitoring systems continuously analyze performance metrics like error rates and latency on the new version.
If the system detects a spike in errors, the automated metrics analyzer triggers an instant rollback in the Git repository. Because the reconciliation engine tracks the git state, it safely reverts the application to the previous stable version immediately. This automated gatekeeping ensures that buggy software updates only affect a minuscule percentage of users before being contained. Therefore, organizations can deploy software multiple times a day with complete confidence and minimal blast radiuses.
Policy Enforcement and Governance at Scale
Large enterprises face the daunting challenge of ensuring security compliance across hundreds of independent development teams. By incorporating policy-as-code engines into the GitOps pipeline, organizations can enforce strict compliance rules automatically. For example, a policy can state that no container can run with root privileges or open insecure public ports. When a team submits a pull request, validation tools scan the configuration files against these rules.
If the proposed configuration violates any organizational policy, the continuous integration pipeline blocks the merge automatically. This automated gatekeeping prevents non-compliant infrastructure from ever getting deployed into live cloud environments. Consequently, security teams transition from manual, slow auditing procedures to continuous, automated compliance enforcement. This approach gives developers autonomy to deploy quickly while maintaining airtight organizational governance and data security.
Common Mistakes in Operations Engineering
Bypassing Version Control for Manual Emergency Fixes
When a massive production outage occurs, engineers often panic and apply manual hotfixes directly to the live environment using command-line interfaces. While this might resolve the immediate symptom, it breaks the core philosophy of git-driven operations completely. The live environment becomes detached from the desired state stored in the git repository. Consequently, the next time an automated pipeline runs, it will overwrite that manual fix and reintroduce the bug.
To prevent this dangerous loop, teams must practice applying emergency fixes strictly through accelerated git workflows. Hotfix branches should go through expedited automated testing and peer review before merging. This practice ensures that even under extreme stress, your documentation and infrastructure code remain perfectly synchronized. Keeping all modifications inside version control prevents long-term technical debt and mysterious recurring outages.
Treating Secret Management as an Afterthought in Git
A frequent and dangerous mistake in declarative operations is accidentally committing sensitive passwords, API keys, and certificates into public or private Git repositories. Because git maintains a permanent ledger of history, deleting a secret from a current commit does not erase it from past revisions. Malicious actors scan repositories constantly for leaked credentials to compromise cloud accounts. Therefore, storing plain text secrets in version control represents a catastrophic security vulnerability.
[ Plain-Text Secret ] ---> ( Committed to Git ) ---> [ Permanent History Leak Risk ] ❌
[ Sealed/Encrypted Secret ] ---> ( Committed to Git ) ---> [ Decrypted inside Cluster Only ] Decrypted inside Cluster Only ]
Organizations must adopt robust secret management utilities like HashiCorp Vault, Mozilla Sops, or Bitnami Sealed Secrets to encrypt data before committing. These tools allow engineers to safely store encrypted tokens inside Git because only the destination cluster holds the decryption keys. This separation of configuration and sensitive data maintains repository integrity while ensuring deep cryptographic protection. Protecting your credentials from day one prevents devastating security breaches and compliance failures.
Over-Engineering Automation and Creating Brittle Pipelines
Automating manual tasks is a primary goal of SRE, but teams often over-engineer pipelines by adding excessive layers of custom scripting. When pipelines become too complex, they turn brittle and difficult for individual team members to troubleshoot during failures. A single minor update to an obscure shell script can completely paralyze the entire continuous delivery pipeline. This over-complexity frustrates developers and slows down the overall velocity of features.
Engineers should strive for simplicity by using standard, well-maintained open-source tools rather than building custom internal frameworks. Focus on creating modular, reusable pipeline templates that follow industry best practices and clear separation of concerns. Document all automation logic thoroughly and ensure that pipeline steps are easy to run locally for debugging purposes. Keeping workflows clean and maintainable guarantees long-term operational agility and reduces cognitive load.
How to Become an Operations Expert — Career Roadmap
Mastering Core Skills and Cloud Architecture
Starting a career path toward operations mastery requires building a rock-solid foundation in operating system fundamentals and networking protocols. You must understand Linux systems deeply, including process management, file structures, and performance optimization commands. Additionally, learn core networking concepts such as DNS configuration, TCP/IP routing, load balancing algorithms, and modern security protocols. These foundational skills allow you to troubleshoot complex distributed systems effectively when high-pressure incidents occur.
Once you master operating systems, transition your focus toward major public cloud infrastructure vendors and containerization technologies. Learn how to write declarative configurations using industry-standard tools like Terraform to provision infrastructure predictably. Study containerization architectures thoroughly by building optimized Dockerfiles and managing container lifecycles effectively. This combination of deep OS knowledge and cloud infrastructure capability forms the starting bedrock of modern site reliability engineering.
Career Level Requirements and Expectations
Progressing through an engineering career requires shifting your focus from executing simple tasks to designing massive distributed systems. The following table highlights the core responsibilities and technical focuses across different career stages.
- Junior SRE / Operations Engineer
- Focuses on monitoring system alerts and learning core infrastructure tools.
- Resolves well-documented incident tickets using established team playbooks.
- Assists in writing basic CI/CD pipeline steps and minor automation scripts.
- Mid-Level SRE / Platform Engineer
- Designs and maintains scalable continuous delivery systems and GitOps workflows.
- Leads root-cause analysis sessions for complex production system outages.
- Optimizes monitoring dashboards, alerting thresholds, and infrastructure resource utilization.
- Senior / Principal SRE Architect
- Defines the long-term architectural vision for organizational platform infrastructure.
- Mentors engineering teams and cultivates a healthy blameless operational culture.
- Architects high-availability disaster recovery strategies across multiple cloud regions.
FAQ Section
- What is the primary difference between traditional CI/CD and GitOps?
Traditional CI/CD pipelines use push-based models to inject configurations directly into clusters via external scripts. Conversely, GitOps utilizes a pull-based model where an internal cluster agent pulls configurations from Git. This approach ensures continuous state reconciliation and automatically prevents configuration drift over time.
- Can we implement GitOps workflows for legacy non-containerized applications?
Yes, you can implement GitOps workflows for legacy applications using specialized configuration management tools. Tools like Ansible, Chef, or Puppet can read declarative configurations from Git and apply them to virtual machines. However, containerized environments like Kubernetes provide the most seamless experience for automated state reconciliation loops.
- How do GitOps practices improve the developer experience during deployments?
GitOps simplifies the deployment workflow by allowing developers to use familiar git tools like pull requests. Developers do not need to learn complex cloud provider dashboards or direct cluster access commands to deploy software. Consequently, this abstraction increases deployment velocity while maintaining strong architectural guardrails and peer review transparency.
- What happens if the centralized Git repository goes down completely?
If the Git repository becomes unavailable, the running production environment continues to operate normally based on its last synced state. However, new deployments and infrastructure modifications will be temporarily paused until Git connectivity is fully restored. Because Git is distributed, you can quickly restore the repository from local developer clones without data loss.
- How does Site Reliability Engineering handle security auditing in a GitOps model?
Security auditing becomes incredibly streamlined because every single infrastructure modification is logged inside the Git commit history. Auditors can view the exact cryptographic history, reviewer approvals, and pull request discussions for every live component. This transparent ledger eliminates the need for manual, error-prone back-and-forth security checks.
Final Summary
Integrating GitOps workflows into Site Reliability Engineering transforms how modern software delivery pipelines operate at scale. By using Git as the definitive single source of truth, organizations gain total visibility, auditability, and automated reconciliation for their infrastructure. This strategy reduces human errors, accelerates deployment speed, and maintains high availability for complex cloud platforms. Furthermore, automated reconciliation loops ensure that configuration drift is instantly corrected before causing production anomalies.
However, achieving operational excellence requires balancing technical tool deployment with a deeply collaborative engineering culture. Teams must invest heavily in proper secret management, policy enforcement, and simplified automation workflows to avoid common engineering pitfalls. As you advance along your operations career roadmap, prioritize mastering both cloud-native tools and architectural patterns. Ultimately, building reliable, self-healing platforms empowers organizations to innovate rapidly while guaranteeing unparalleled system stability.