Imagine a sudden operational bottleneck cascading through your infrastructure during peak traffic hours, causing a massive system disruption that halts every critical transaction. Your engineering teams scramble blindly in multiple directions because nobody owns the end-to-end reliability of the system, costing your business thousands of dollars every single minute. Consequently, this exact chaotic scenario highlights why organizations must transition from reactive operations to a structured framework known as Site Reliability Engineering.
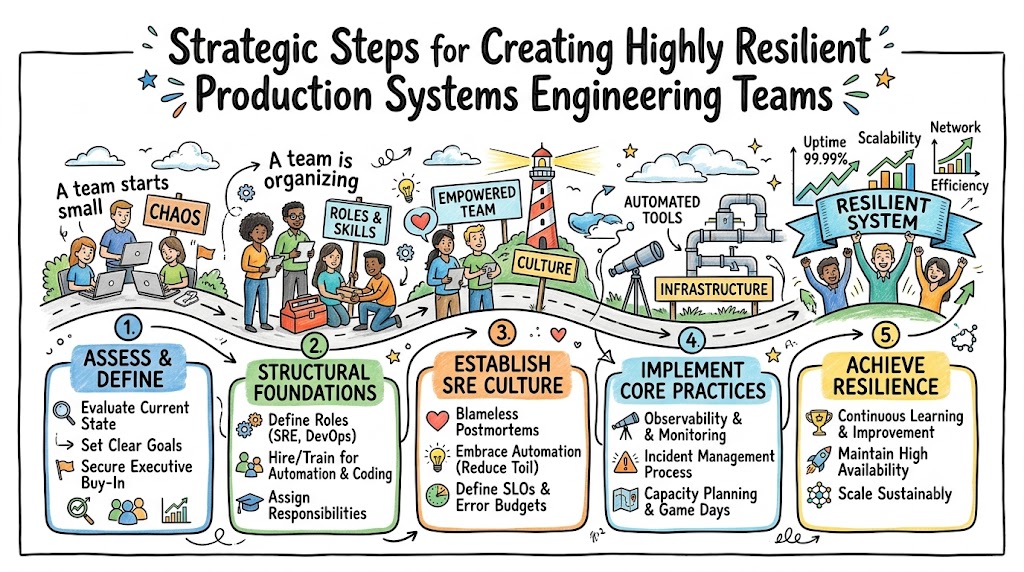
Building a successful Site Reliability Engineering team from scratch involves applying software engineering principles directly to infrastructure and operations problems to create highly scalable, self-healing systems. This comprehensive guide walks you through the foundational pillars, structural blueprints, and cultural changes needed to establish a world-class production health team. You will discover exactly how to define metrics, reduce repetitive manual tasks, select the right automated tools, and structure your engineering hierarchy for long-term stability. If you want to transform your operational workflows and ensure continuous application delivery, you can accelerate your journey by learning professional methodology at Sreschool.
Establishing a Ground-Up Foundation for Production Excellence
When you establish a Site Reliability Engineering framework from the ground up, you fundamentally change how your business views software delivery and infrastructure management. This discipline operates on the premise that operations is a software problem, which requires hiring engineers who love writing code to optimize system architecture.
Historically, companies treated infrastructure as a static entity, but modern cloud environments require dynamic, programmable ecosystems that scale automatically under load. By embedding automated testing, continuous telemetry, and systemic risk budgets into your core engineering pipeline, your newly formed team bridges the traditional gap between rapid feature development and rigid system stability.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
For many decades, traditional enterprise operations relied on a rigid division of labor where developers built applications and separate operations teams deployed them. Because developers faced pressure to ship features quickly, they frequently delivered unoptimized code without considering long-term environmental stability.
Meanwhile, operations teams faced the burden of maintaining uptime, which naturally made them resistant to any frequent software changes or deployments. This misalignment created massive cultural silos, delayed software releases, and caused frequent system failures due to a total lack of communication.
Moving Toward Unified Workflow Automation
As software architectures migrated toward distributed internet services, the traditional wall between development and operations became completely unsustainable. Therefore, progressive organizations began embracing unified workflow automation, combining infrastructure provisioning directly with application development lifecycles.
By treating infrastructure as code, teams successfully automated repetitive provisioning tasks, minimized human configuration errors, and accelerated delivery pipelines. This historical shift broke down legacy operational silos, establishing a shared responsibility model where software performance became a collective engineering goal.
Global Expansion Across Commercial Ecosystems
The immense success of automated infrastructure management quickly caught the attention of large-scale tech enterprises across the globe. As systems grew increasingly complex with thousands of microservices, manual system administration became completely impossible to maintain.
Consequently, these operational frameworks expanded rapidly across commercial ecosystems, transforming from an internal tech methodology into an industry-wide standard. Modern enterprises now recognize that proactive system stabilization is an absolute requirement for surviving in a competitive digital marketplace.
Defining Strategic Operations Management
The Core Operational Structure
The foundational architecture of strategic operations management relies on continuous feedback loops between running applications and engineering teams. Telemetry data constantly flows from production servers into automated analysis engines, which provides real-time visibility into system health.
[Production Systems] ---> (Telemetry Data) ---> [Analysis Engines]
^ |
| v
(Auto-Remediation) <--- [Engineering Platform] <--- (Alerts)
This structural flow allows organizations to treat system health as a predictable, measurable attribute rather than a matter of luck. By standardizing how software communicates its internal state, your infrastructure can automatically detect anomalies and trigger defensive scaling policies before users experience performance degradation.
Daily Tasks of Systems Coordinators
Systems coordinators and reliability engineers spend their days executing a balanced mix of software engineering work and operational support tasks. They write automated scripts to provision cloud resources, build resilient deployment pipelines, and design automated self-healing mechanisms for production environments.
Additionally, they review system performance dashboards, investigate minor operational anomalies, and participate in structured on-call rotations to handle unexpected critical issues. This balanced workload ensures that engineers remain deeply connected to production realities while dedicating significant time to long-term architectural improvements.
Localized Control vs. Broad System Architecture
Managing modern infrastructure requires balancing granular, localized component tracking with high-level, broad multi-system architecture management. Localized control focusing on individual servers or single database instances is no longer sufficient for complex, distributed applications.
Instead, reliability specialists must analyze how hundreds of interconnected components behave collectively under diverse traffic patterns. This holistic approach ensures that optimizing one specific service does not accidentally create a catastrophic bottleneck in a downstream dependency.
The Efficiency Mindset
Transitioning to a modern operational framework requires a profound cultural shift that prioritizes long-term system stability over short-term feature speed. Engineers must develop an efficiency mindset, which means they constantly look for ways to make systems highly repeatable and predictable.
Instead of fixing the same server issue manually multiple times, they dedicate time to engineer a permanent software-driven solution. This relentless focus on sustainable engineering helps organizations scale their digital operations exponentially without needing to hire a matching number of administrators.
The 7 Core Principles of How to Build a Successful SRE Team from Scratch
1. Embracing Risk and Managing Variability
This core principle states that demanding 100% reliability is completely unrealistic and commercially unviable for any software product. Because hardware fails, networks fluctuate, and software contains bugs, teams must accept a calculated amount of systemic risk to innovate quickly.
By managing variability instead of trying to eliminate it entirely, you can establish realistic availability targets that satisfy your users. This approach allows your development teams to launch new features confidently, provided they remain within your agreed operational risk parameters.
2. Establishing Service Level Objectives (SLOs)
Service Level Objectives form the mathematical core of your reliability strategy by defining explicit, measurable targets for system success. These objectives align engineering priorities directly with actual user expectations, ensuring you measure metrics that truly impact customer satisfaction.
+-------------------------------------------------------------+
| SERVICE LEVEL TERMINOLOGY MATRIX |
+------------------------------+------------------------------+
| Term | Core Purpose |
+------------------------------+------------------------------+
| SLI (Indicator) | What specific metric we are |
| | measuring right now. |
+------------------------------+------------------------------+
| SLO (Objective) | The target target number |
| | we agree to maintain. |
+------------------------------+------------------------------+
| SLA (Agreement) | The legal contract detailing |
| | consequences of failure. |
+------------------------------+------------------------------+
By tracking precise objectives, your teams can make data-driven choices about whether to ship features or focus on infrastructure stability. This quantitative framework completely eliminates emotional arguments between product managers and engineering leaders regarding software deployment schedules.
3. Eliminating Toil and Manual Processes
Toil represents the repetitive, manual, operational work that provides no long-term strategic value and scales linearly with system size. Examples include manually restarting servers, running repetitive database cleanups, or manually approving routine infrastructure changes.
A successful reliability team strictly limits this manual overhead to less than half of their total working time. They dedicate the remaining time to engineering projects that permanently automate these tasks away, ensuring the infrastructure remains easily manageable as it expands.
4. Monitoring & Observability Across the Pipeline
True observability goes far beyond basic infrastructure monitoring by providing deep insights into the internal states of your applications. It requires collecting, aggregating, and analyzing comprehensive metrics, structured logs, and distributed request traces across your entire pipeline.
This total visibility ensures that when a complex microservice environment fails, engineers can quickly isolate the exact root cause. Consequently, robust observability eliminates guesswork during critical incidents, drastically reducing the time required to restore standard business operations.
5. Automation Over Manual Coordination
When scaling global tech infrastructure, human coordination quickly becomes the primary bottleneck for operational speed and safety. Therefore, teams must consistently choose automated software solutions over manual intervention to manage deployment and configuration workflows.
Whether you are scaling container clusters, applying security patches, or routing network traffic, automation ensures perfect execution consistency. This systematic removal of manual steps prevents human error, which remains one of the leading causes of production outages.
6. Release Engineering and Deployment Stability
Release engineering focuses on building consistent, predictable, and fully automated strategies for delivering software updates into production environments. This practice requires using advanced deployment patterns like canary releases, blue-green deployments, and automated rolling updates to minimize user impact.
By treating release engineering as a core discipline, your team ensures that every code deployment undergoes rigorous automated testing. If a new software version shows signs of instability, automated systems instantly roll back the change to protect users.
7. Simplicity in Network Architecture
Complex system architectures are inherently difficult to monitor, troubleshoot, secure, and maintain over extended periods. Therefore, successful teams champion simplicity by designing clean, minimal network architectures with clearly defined boundaries between services.
By eliminating redundant software layers and avoiding overly intricate routing configurations, you significantly reduce your overall failure surface. Simple systems fail less frequently, and when they do encounter issues, engineers can understand and fix them much faster.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Understanding the explicit distinctions between these three terms is absolutely essential for managing infrastructure reliability effectively:
- SLI (Service Level Indicator): A compliance metric that quantifies a specific aspect of your system performance, such as request latency or error rate.
- SLO (Service Level Objective): A target value or range of values for a service level that your team commits to achieving, measured by your SLIs over time.
- SLA (Service Level Agreement): A legal and commercial commitment made to your end users that outlines the financial consequences if your system fails to meet its SLO.
Error Budgets — The Game Changer for Operational Risk
An error budget represents the exact amount of acceptable downtime or system instability your product can tolerate over a specific timeframe. For instance, if your service commits to a 99.9% availability objective, your error budget is the remaining 0.1% of allowable failures.
This budget acts as a clear guide for balancing development speed against infrastructure safety. When your error budget is full, developers can launch features rapidly; however, if the budget empties, feature releases pause so engineers can fix reliability issues.
Toil — The Silent Productivity Killer in Infrastructure
Toil acts as a silent productivity killer because it consumes valuable engineering hours that teams should spend on innovation. You can identify toil by looking for tasks that are repetitive, tactical, easily automatable, and lacking in long-term engineering value.
Toil Identification Checklist:
[ ] Is the task manual and repetitive?
[ ] Can the task be fully automated with a script?
[ ] Does the task scale linearly with infrastructure growth?
[ ] Does the task lack long-term strategic value?
To eliminate this operational debt, your team must carefully measure the hours spent on manual fixes each week. Once identified, engineers must build robust automated scripts or self-service tools that permanently remove those tasks from daily operations.
Incident Management & Postmortems
When a major production failure occurs, effective incident management requires clear roles, rapid communication channels, and swift remediation procedures. After resolving the immediate problem, the team must conduct a highly structured, completely blameless postmortem analysis.
The primary goal of a blameless postmortem is to discover exactly why the system allowed a failure to happen, rather than blaming individuals. This healthy culture encourages transparency, uncovers hidden architectural flaws, and creates actionable engineering tasks to prevent the incident from ever repeating.
Capacity Planning
Capacity planning ensures your digital infrastructure can gracefully handle future growth, seasonal traffic spikes, and unexpected shifts in user behavior. This practice involves analyzing historical consumption trends for computing power, memory storage, and network bandwidth.
By combining historical data with upcoming product launch schedules, your team can accurately forecast infrastructure requirements. Proactive capacity planning prevents resource exhaustion outages, allowing your platform to scale smoothly ahead of real-world demand.
The Four Golden Signals of Pipeline Performance
To maintain comprehensive visibility into any distributed ecosystem, engineers must track the four golden signals of system performance:
- Latency: The precise time it takes to service a specific request, making sure to differentiate between successful requests and failed requests.
- Traffic: A measure of how much demand is being placed on your system, commonly tracked via web requests per second or concurrent network connections.
- Errors: The rate of requests that fail explicitly, return internal server errors, or violate predefined system policy constraints.
- Saturation: A measure of how full your system resources are, highlighting the most constrained metrics like CPU utilization or memory storage capacity.
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
Many organizations mistakenly believe that adopting modern reliability engineering simply means purchasing expensive observability tools or installing container orchestration platforms. However, concrete technical implementations represent only one side of the coin; the overarching philosophy requires an equally deep cultural transformation.
While platforms provide the technical mechanisms to scale and automate, culture dictates how engineers interact, learn from failures, and manage risk. Technology without a supportive cultural mindset quickly results in misconfigured tools, alert fatigue, and broken team dynamics.
Roles & Responsibilities Compared
- Platform Implementation Focus:
- Building and maintaining scalable internal developer platforms.
- Configuring automated continuous integration and continuous deployment pipelines.
- Managing cloud infrastructure provisioning via infrastructure-as-code files.
- Setting up centralized logging clusters and metric aggregation tools.
- Cultural Philosophy Focus:
- Facilitating blameless incident reviews across different engineering departments.
- Negotiating realistic reliability targets between product managers and developers.
- Advocating for the systematic reduction of manual toil across the company.
- Teaching development teams how to design highly resilient software applications.
Can You Have Both Disciplines?
Modern, high-growth technology organizations do not choose between platform engineering and reliability culture; instead, they successfully run both disciplines simultaneously. These two approaches support each other perfectly, creating a highly efficient ecosystem where platform tools enforce cultural goals automatically.
For instance, your platform engineering team can build automated guardrails directly into the deployment framework that enforce the reliability standards defined by your culture. This collaborative relationship allows your entire engineering organization to move incredibly fast while maintaining production stability.
Which One Should Your Team Adopt?
Selecting the ideal operational framework depends heavily on your current organizational size, engineering maturity, and immediate structural challenges.
+-------------------------------------------------------------+
| ORGANIZATIONAL ADOPTION FRAMEWORK |
+------------------------------+------------------------------+
| Company Profile | Recommended Focus |
+------------------------------+------------------------------+
| Small Startup | Focus heavily on Reliability |
| | Culture first. |
+------------------------------+------------------------------+
| Mid-Sized Enterprise | Balance Platform Tools with |
| | SRE Principles. |
+------------------------------+------------------------------+
| Large Enterprise | Deploy dedicated Platform |
| | and SRE Teams. |
+------------------------------+------------------------------+
If your company is experiencing frequent production outages and blame-shifting cultures, you must prioritize establishing core reliability principles immediately. Conversely, if your developers are struggling with slow, fragmented deployment processes, investing heavily in platform implementation will yield the highest return.
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Major global software providers use real-time operational metrics to automate their entire business decision-making pipeline. For instance, when automated monitoring detects that a specific service is exceeding its error budget, the deployment system blocks feature updates automatically.
This objective data usage ensures that software quality remains high without requiring constant executive oversight or manual approvals. By relying on clear quantitative data, these tech leaders maintain high consumer trust even while executing hundreds of production deployments daily.
Chaos Engineering Approaches to Resilient Systems
Leading streaming platforms and cloud-native enterprises actively practice chaos engineering to discover hidden architectural weaknesses before they impact customers. They use automated tools to intentionally inject failures, such as shutting down server clusters or introducing artificial network latency in production.
[Inject Failure: Kill Node] ---> [Monitor System Response] ---> [Verify Auto-Healing Works]
By observing how their applications respond to these controlled disruptions, engineers can validate that self-healing systems work perfectly under stress. This proactive experimentation transforms unexpected infrastructure failures into completely non-event anomalies that pass entirely unnoticed by users.
Handling Reliability at Massive Scale
Hyper-scale consumer web services handle hundreds of millions of concurrent global transactions by designing completely stateless, highly distributed microservice architectures. They route incoming internet traffic across multiple geographic regions using advanced automated load-balancing systems.
If an entire data center suffers a catastrophic power outage, automated routing mechanisms immediately shift workloads to healthy regions. This architecture ensures uninterrupted service availability, demonstrating how smart software design completely insulates global users from massive physical hardware failures.
High-Availability in Fintech Operations
Modern financial technology networks operate within a strict zero-tolerance environment for data loss, data corruption, or system downtime. To meet these intense regulatory and customer requirements, fintech reliability engineers implement highly redundant transactional architectures.
They use advanced distributed consensus protocols to ensure every single financial transaction writes safely to multiple physical locations simultaneously. Additionally, they run continuous real-time data auditing tools to detect and isolate processing anomalies before clearing payments.
Scaled-Down but Essential Systems for Startups
Early-stage technology startups obviously lack the massive engineering budgets of global corporations, yet they still require highly reliable systems to retain initial customers. Smart startup founders solve this by applying core reliability principles in a highly efficient, scaled-down manner.
Instead of building complex internal tools, they leverage managed cloud services, automated container deployments, and basic external monitoring checks. This lean approach allows small teams to maintain excellent system uptime and eliminate manual toil without incurring massive operational overhead.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
A very frequent mistake companies make when building a reliability team is simply renaming their traditional system administrators as reliability engineers. If your newly appointed specialists spend all their time manually responding to alerts without writing code, you have not changed anything.
This discipline is explicitly about proactive software engineering, which means your engineers must have the time and skills to build automated solutions. If you trap your team in a non-stop cycle of reactive manual firefighting, your infrastructure will never improve.
Mistake 2 — Setting Unrealistic SLOs
When management teams first discover reliability metrics, they often enthusiastically demand perfect 100% uptime for every application component. However, setting unrealistic objectives creates massive engineering friction, stalls feature delivery, and burns out your smartest engineers completely.
Every extra digit of availability you chase requires exponential investments in infrastructure costs and engineering hours. You must always set your targets based on actual user satisfaction, ensuring your systems are exactly as reliable as your customers need them to be.
Mistake 3 — Ignoring Toil Until It’s Too Late
When engineering organizations prioritize feature speed over system health, they systematically ignore the slow accumulation of manual operational toil. Eventually, the volume of manual interventions, server restarts, and data fixes grows so large that it consumes your team’s entire capacity.
This massive accumulation of operational debt slows your engineering velocity to a complete crawl and frustrates your team. Successful organizations combat this by tracking toil hours closely and pausing feature work whenever manual tasks threaten to overwhelm engineers.
Mistake 4 — Skipping Blameless Postmortems
When a company culture defaults to finding a human scapegoat after a major production failure, engineers naturally become deeply fearful. Consequently, they begin hiding system mistakes, avoiding ambitious architectural upgrades, and withholding critical information during incident investigations.
Skipping truly blameless reviews ensures that the underlying technical and organizational flaws remain completely unaddressed in your system. If you want to build a resilient platform, you must treat every operational failure as a valuable learning opportunity.
Mistake 5 — Monitoring Without Actionable Alerts
Many infrastructure teams suffer from severe alert fatigue because they configure their monitoring platforms to notify engineers for every minor system variance. If an automated page does not require immediate human intervention to prevent user impact, it should never wake up an engineer.
Non-actionable alerts overwhelm your on-call responders, making it highly likely they will miss critical notifications during real infrastructure emergencies. You must clean your alerting systems constantly, ensuring every notification maps directly to a clear, documented response procedure.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Organizations frequently make the costly mistake of consulting their reliability specialists only after an application architecture is completely built and deployed. Consequently, operations engineers are forced to support poorly designed, un-scalable software systems that fail constantly in production environments.
To prevent this operational bottleneck, you must involve reliability experts in your initial system design and architectural phase from day one. Their unique expertise ensures that new services are built from the start with excellent observability, automated scaling, and clean failure domains.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
To maintain deep operational visibility, modern engineering teams rely on powerful metric collection systems like Prometheus combined with flexible visualization engines like Grafana. These tools allow specialists to build real-time infrastructure dashboards, track complex performance trends, and spot emerging bottlenecks instantly.
For enterprise environments requiring comprehensive, out-of-the-box analysis across multi-cloud footprints, platforms like Datadog and New Relic provide deep tracing capabilities. These monitoring frameworks ensure you possess the data needed to understand your system state at any moment.
Incident Management
When production outages occur, teams use dedicated incident response platforms like PagerDuty to orchestrate their human communication workflows. These platforms integrate directly with monitoring engines, ensuring critical alerts route instantly to the specific engineer on-call.
By automating call schedules, escalation paths, and incident updates, these tools reduce communication chaos during major system emergencies. This automated coordination allows your technical experts to focus entirely on fixing the actual infrastructure issue.
CI/CD & Release Engineering
Automating software delivery requires robust continuous integration and deployment engines such as Jenkins, Spinnaker, and Argo CD. These platforms allow teams to declare their deployment pipelines as code, running comprehensive security checks and automated tests before pushing software.
By managing your release pipelines through these automated engines, you ensure every code update deploys in a highly consistent manner. Furthermore, these tools manage advanced rollout strategies like canary testing, keeping your production environment completely safe.
Chaos Engineering
To test system resilience proactively, modern teams use specialized chaos engineering frameworks like Chaos Monkey to safely inject controlled failures. These automation utilities simulate real-world production disasters, such as killing container instances or dropping network packets in a safe manner.
By running these automated failure experiments during normal business hours, engineers can verify that their infrastructure heals itself automatically. This continuous experimentation uncovers hidden software bugs before they can cause major outages for real users.
SLO Management
Tracking service performance against strict consumer objectives requires dedicated reliability platforms such as Nobl9. These specialized applications ingest metric telemetry data from multiple monitoring sources and calculate your exact error budget consumption rates.
By providing clear visibility into your remaining error margins, these tools help align product management goals with engineering priorities. This automation ensures that your organization makes objective, data-driven decisions regarding feature release velocities and stability efforts.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Becoming a world-class infrastructure reliability expert requires a powerful blend of software engineering capabilities and deep systems administration knowledge. You must master command-line terminal navigation, understand advanced Linux networking protocols, and learn scripting languages like Python or Go thoroughly.
Additionally, you need to understand core cloud infrastructure patterns, containerization technologies like Docker, and infrastructure-as-code configuration tools. These technical skills give you the ability to view, analyze, and manipulate complex software environments through code.
The Professional Learning Path
The educational journey into modern systems management begins with mastering basic software development and understanding how operating systems handle resources. Next, you must learn how to configure web servers, manage relational databases, and build basic automated deployment pipelines.
As you progress, you should focus on distributed system design, advanced cloud orchestration platforms like Kubernetes, and complex telemetry aggregation techniques. Finally, achieving a senior architectural level requires developing strong leadership skills, risk management expertise, and cross-departmental communication strategies.
Certifications Worth Pursuing
While real-world engineering experience is always paramount, obtaining industry-recognized professional credentials can significantly validate your infrastructure expertise. Pursuing advanced cloud architecture certifications from major providers like AWS, Google Cloud, or Microsoft Azure establishes a strong operational baseline.
Additionally, earning specialized open-source credentials like the Certified Kubernetes Administrator (CKA) demonstrates deep expertise in modern container orchestration. These structured training paths help round out your technical knowledge, making you a highly competitive asset in the global job market.
Educational Resources with Sreschool
If you want to fast-track your journey toward becoming a senior systems specialist, finding structured educational material is absolutely critical. You can explore a vast library of comprehensive courses, real-world scenario guides, and expert-led training paths at Sreschool.
Their professional training programs focus intensely on practical, hands-on learning, teaching you exactly how to build resilient production architectures from scratch. Investing time in these specialized educational resources ensures you master the exact methodologies demanded by modern technology organizations.
The Future of Systems Management
AI and Automation in System Optimization
The next evolution of infrastructure management is deeply tied to incorporating machine intelligence directly into automated operational workflows. Advanced machine learning models can analyze terabytes of system telemetry data to predict infrastructure failures before they manifest.
[Massive Telemetry Data] ---> [Machine Learning Models] ---> [Predictive Self-Healing Actions]
These intelligent systems speed up root cause analysis during complex outages by instantly pointing engineers to anomalous code lines. By automating routine pattern recognition, intelligent software allows human operators to focus entirely on high-level strategic engineering projects.
Platform Engineering — The Evolution of Infrastructure
Platform engineering represents a major structural evolution where dedicated infrastructure teams build internal self-service portals for their development departments. These internal platforms package complex cloud infrastructure, security guardrails, and deployment pipelines into simple, automated interfaces.
This self-service model allows software developers to provision resources and ship code safely without needing deep operational knowledge. Consequently, platform engineering eliminates organizational friction, accelerating business delivery velocity while ensuring absolute compliance with infrastructure standards.
Management in Cloud-Native & Kubernetes Environments
As global business architectures migrate completely to dynamic, containerized environments managed by Kubernetes, systems management challenges are changing rapidly. Operating thousands of ephemeral containers requires implementing highly scalable service meshes, advanced network policies, and decentralized observability frameworks.
Reliability engineers must build automated systems that track and secure these rapidly shifting microservice environments in real time. Masterfully managing this orchestration complexity remains an absolute priority for businesses looking to unlock the full potential of cloud-native scalability.
Operational Skills That Will Matter Most
In the coming years, the most successful systems specialists will expand their technical skills to include deep financial cost optimization. As cloud environments grow increasingly large, managing cloud spend efficiently while maintaining absolute system reliability is becoming a critical business requirement.
Additionally, engineers must master advanced data observability techniques, learning how to track security indicators directly alongside standard performance metrics. Cultivating this multidimensional engineering mindset ensures you remain an invaluable leader in the evolving technological landscape.
FAQ Section
- What is the typical career path for an engineer entering this discipline?
Most professionals enter this field from either a software development background or a traditional systems administration role. They start as junior reliability engineers, progress to senior infrastructure architects, and eventually move into strategic operational leadership or platform engineering management roles. - How does this methodology differ fundamentally from legacy DevOps setups?
While DevOps provides a broad cultural philosophy focused on breaking down silos between development and operations teams, this methodology acts as a concrete implementation framework. It provides explicit engineering roles, mathematical models, and software-driven practices to achieve those high-level DevOps collaboration goals. - What are the average global salary trends for reliability specialists?
Due to the critical nature of production stability and the rare combination of development and operations skills required, compensation trends remain exceptionally high. Senior reliability engineers and platform architects consistently command premium salaries that rank among the top tiers of the global technology workforce. - How much software programming knowledge is required for this role?
Professionals in this discipline must possess strong programming fundamentals to write automated tools, build internal platforms, and debug complex application code. You do not need to be an expert frontend developer, but you must be highly proficient in backend scripting languages like Python, Go, or Ruby. - Can small early-stage startups benefit from these principles immediately?
Yes, startups can benefit immensely by adopting a reliability mindset early, which prevents the accumulation of crippling technical debt. By implementing simple automation, clear indicators, and blameless cultures from day one, small teams can scale their applications smoothly without experiencing massive operational crises. - What is the best way to handle persistent alert fatigue within a team?
The most effective strategy is to systematically delete or reconfigure any automated page that does not require immediate human intervention. Ensure that non-critical system warnings route directly to email or chat channels for review during standard business hours, keeping urgent paging channels completely clear.
Final Summary
Establishing an exceptional production systems engineering framework requires a deliberate combination of automated platform tooling, clear mathematical objectives, and a supportive engineering culture. By treating operational challenges directly as software problems, your team can eliminate manual toil, mitigate systemic risk, and maintain continuous delivery speed.
As technology environments grow increasingly complex, prioritizing long-term system health remains the ultimate differentiator for successful digital enterprises. Embracing these advanced performance frameworks ensures your business remains resilient, scalable, and fully prepared for future technological evolutions with the expert guidance of Sreschool.