Complete Analytical Breakdown of Site Reliability Engineering Principles and Toolsets
Site Reliability Engineering tools form the foundational technical bedrock of modern digital architecture, providing the deep visibility, programmatic automation, and architectural guardrails required to keep complex distributed cloud systems functional. Site Reliability Engineering, commonly known as SRE, bridges the operational gap between software development and IT infrastructure management by applying rigorous software engineering principles directly to complex production challenges. Rather than relying on traditional manual intervention, engineers utilize these specialized technologies to shift their workload away from reactive firefighting and toward proactive system design.
By integrating these advanced platforms, organizations can accurately measure user experiences, automate rapid software rollouts, orchestrate immediate incident responses, and deliberately inject faults to uncover structural vulnerabilities before they impact customers. Consequently, choosing the correct engineering stack directly influences how efficiently a business maintains its service level agreements while driving continuous code innovation.
Imagine a sudden, massive system disruption hitting your core production environment during peak traffic hours, crashing transaction pipelines and locking users out completely. Operational bottlenecks like these happen instantly when infrastructure lacks resilient automation and deep architectural visibility.
Modern engineering teams need robust site reliability engineering frameworks to maintain scale, handle rapid deployment paces, and ensure continuous high availability. This comprehensive guide covers the essential monitoring, incident response, deployment automation, and chaos testing tools that empower teams to defend system uptime and track critical performance metrics seamlessly.
To build deep operational expertise and master these production environments, you can explore the specialized curriculum and hands-on learning paths available at Sreschool.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
Traditional enterprise operations relied heavily on isolated, siloed departments where software developers built features independently while system administrators managed live server environments. Consequently, this sharp division created massive operational bottlenecks because developers focused entirely on speed of feature delivery, whereas administrators focused strictly on infrastructure stability.
Whenever a new application update crashed in production, teams wasted hours finger-pointing rather than resolving the core architectural issues. Manual setups, undocumented scripts, and inconsistent environments further aggravated these systemic delays, leading to frequent outages and slowed deployment cycles.
Moving Toward Unified Workflow Automation
As enterprise systems expanded, breaking down these traditional departmental silos became absolutely essential for business survival. Organizations recognized that unifying software development workflows with operational safety could drastically eliminate systemic friction and reduce downtime.
Accordingly, engineers began automating repetitive provisioning tasks, treating infrastructure setup exactly like software application code. This structural shift transformed corporate infrastructure by introducing predictable release patterns, standardizing deployment pipelines, and ensuring that operational feedback influenced software architecture from the earliest design stages.
Global Expansion Across Commercial Ecosystems
The rapid rise of cloud computing and microservices accelerated the global expansion of these automated operational frameworks across modern large-scale tech enterprises. Suddenly, web-scale companies had to manage thousands of distributed virtual servers running simultaneous code deployments every single day.
As a result, the old methods of manual server tracking completely failed to keep pace with consumer demand. These advanced operational philosophies quickly spread across global commercial ecosystems, establishing new baseline industry standards for system resilience, data visibility, and rapid incident recovery.
Defining Strategic Operations Management
The Core Operational Structure
The foundational architecture of strategic operations management centers on a continuous loop of telemetry data collection, automated analysis, and programmatic adjustment. Systems must constantly emit detailed performance logs, metrics, and trace statements from every active microservice layer.
+-----------------------------------------------------------+
| The SRE Telemetry Loop |
+-----------------------------------------------------------+
| |
| +------------------+ +--------------------+ |
| | System Emits |---------> Automated Metric | |
| | Telemetry Data | | Analysis Engine | |
| +------------------+ +---------+----------+ |
| ^ | |
| | v |
| +--------+---------+ +--------------------+ |
| | Programmatic | <-------+ Actionable Alert | |
| | Adjustment | | Triggered | |
| +------------------+ +--------------------+ |
| |
+-----------------------------------------------------------+
Then, automated tracking systems ingest this massive data stream to evaluate overall system health against pre-defined performance thresholds. Whenever performance deviates from these metrics, the architecture triggers actionable alerts or initiates automated self-healing scripts to stabilize the platform.
Daily Tasks of Systems Coordinators
Reliability specialists spend their shifts balancing engineering projects with tactical infrastructure maintenance to optimize software environments. On a daily basis, these professionals design automated CI/CD pipelines, configure granular monitoring dashboards, and review recent system alerts to eliminate noise.
Furthermore, they facilitate comprehensive postmortem meetings following production incidents and write automated scripts to handle sudden traffic spikes. Rather than manually clicking through server configurations, they dedicate their time to writing clean, reusable software code that hardens system defenses.
Localized Control vs. Broad System Architecture
Managing modern enterprise infrastructure requires balancing localized, granular component tracking against broad multi-system architecture oversight. For instance, localized control focuses on monitoring specific metrics like a single database instance’s CPU utilization or an individual container’s memory usage.
Conversely, managing broad system architecture requires understanding how hundreds of interconnected microservices behave collectively under heavy concurrent user loads. Reliability engineers must master both perspectives, ensuring individual components remain healthy while optimizing the end-to-end user journey across the entire global infrastructure.
The Efficiency Mindset
Achieving long-term system stability requires a profound cultural shift that prioritizes structural sustainability over temporary quick fixes. Teams with an efficiency mindset view system failures as highly valuable learning opportunities to improve automation rather than reasons to assign blame.
Therefore, engineers consistently invest upfront time to build resilient, self-healing platforms that gracefully tolerate underlying hardware or network drops. This proactive approach ensures that systems remain reliably performant even as application complexity and user bases scale exponentially.
The 7 Core Principles of Site Reliability Engineering
1. Embracing Risk and Managing Variability
Perfect uptime is a technical illusion because all software components, underlying hardware networks, and cloud providers will eventually experience failure. Reliability engineering explicitly acknowledges this reality by identifying exactly how much risk an application can safely tolerate without impacting user satisfaction.
By actively managing systemic variability instead of striving for impossible perfection, teams preserve precious engineering energy. Consequently, businesses can balance rapid feature innovation with baseline infrastructure safety, treating minor failures as completely normal operational occurrences.
2. Establishing Service Level Objectives (SLOs)
Teams must define clear, quantifiable targets for system success to align engineering priorities with actual user expectations. Service Level Objectives act as the definitive metric that determines whether a platform is performing acceptably from the consumer’s point of view.
By grounding operational discussions in objective mathematical metrics, organizations completely eliminate emotional debates regarding system stability. These clear boundaries help product owners and reliability engineers decide exactly when to accelerate feature releases or when to pause deployments to focus on stability.
3. Eliminating Toil and Manual Processes
Toil represents the repetitive, tactical, manual work that keeps a system running but lacks long-term strategic value. Examples include manually resetting stuck server threads, performing routine database lookups, or executing repetitive configuration updates.
Reliability frameworks mandate that engineers systematically identify this repetitive work and write software automation to eliminate it permanently. Restricting toil ensures that technical teams retain ample time to focus on creative engineering projects that genuinely improve systemic capacity.
4. Monitoring & Observability Across the Pipeline
Deep visibility across the entire operational environment prevents dangerous technical blind spots from hiding deep within complex distributed systems. True observability requires gathering comprehensive metrics, structured application logs, and distributed request traces from every infrastructure layer.
[ Infrastructure Pipeline Layers ]
+--------------------------------+
| Application Layer | ---> Distributed Traces
+--------------------------------+
| Container Layer | ---> Structured Logs
+--------------------------------+
| Cloud Layer | ---> System Metrics
+--------------------------------+
This multi-dimensional data approach allows engineers to quickly trace how a single user request flows across multiple microservices. As a result, operations teams can identify subtle memory leaks, network delays, or database bottlenecks before they cause a widespread outage.
5. Automation Over Manual Coordination
Scaling modern digital workflows efficiently requires a strict engineering commitment to software automation over human operational coordination. Whenever a system requires manual intervention to scale up or recover from an error, the architecture introduces a human point of failure.
Therefore, engineers build smart programmatic systems that automatically provision cloud servers, balance network traffic, and patch software versions. Automation ensures that infrastructure operations remain incredibly fast, highly repeatable, and completely free from manual configuration mistakes.
6. Release Engineering and Deployment Stability
Consistent, predictable, and safe application delivery strategies are vital for maintaining system health during frequent software updates. Release engineering focuses on building automated testing and deployment pipelines that catch bugs long before they hit live users.
By utilizing advanced deployment strategies like canary testing or blue-green rollouts, teams can safely expose updates to small user groups. If the new software code exhibits anomalies, automated systems instantly roll back the deployment to protect the broader user base.
7. Simplicity in Network Architecture
Keeping infrastructure environments clean, minimal, and highly structured directly reduces overall failure surfaces and simplifies troubleshooting during live incidents. Complex, intertwined network configurations make it incredibly difficult for engineers to isolate problems quickly under high pressure.
By adhering to strict architectural simplicity, teams ensure that system dependencies remain explicit and easy to map out. Clean architecture makes systems far easier to monitor, automate, and scale, which dramatically limits unexpected behavioral side effects during high-traffic events.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Understanding the explicit distinctions between these three foundational reliability metrics is critical for driving clear engineering and business communication:
- SLA (Service Level Agreement): The formal commitment made directly to external customers, defining promised system performance and the explicit financial or legal penalties if the company fails to meet it.
- SLO (Service Level Objective): The stricter internal target set by engineering teams to keep systems healthy and ensure the organization never actually breaches the formal external SLA.
- SLI (Service Level Indicator): The precise, real-time mathematical measurement of current system performance, such as the exact percentage of successful API requests processed over the last hour.
Error Budgets — The Game Changer for Operational Risk
An error budget represents the exact amount of system downtime or performance degradation that an application can legally experience before violating its internal SLO. Calculated simply as $100\% – \text{SLO}$, this metric provides a clear mathematical buffer for taking calculated risks.
For instance, if your system maintains a $99.9\%$ uptime SLO, your available error budget sits at exactly $0.1\%$ over a given tracking window. Product teams can freely spend this budget by launching experimental features, executing rapid code deployments, or conducting live architecture updates. However, if unexpected outages completely exhaust the error budget, the team must immediately halt all new feature updates and dedicate full engineering capacity to hardening stability.
Toil — The Silent Productivity Killer in Infrastructure
Toil is the repetitive operational work that scales linearly alongside system growth, requiring continuous manual effort without improving the infrastructure’s long-term capability. If left unchecked, toil quickly consumes an engineering team’s entire weekly schedule, causing severe project delays and widespread developer burnout.
+-----------------------------------------------------------+
| Systematic Toil Elimination |
+-----------------------------------------------------------+
| |
| 1. IDENTIFY IT --> Spot manual, repetitive, non-triage|
| tasks during weekly operations. |
| |
| 2. MEASURE IT --> Calculate the exact percentage of |
| engineering hours spent manually. |
| |
| 3. AUTOMATE IT --> Write clean, reusable software |
| scripts to execute the task. |
| |
| 4. ELIMINATE IT --> Remove the manual workflow from the|
| standard production environment. |
| |
+-----------------------------------------------------------+
To systematically eliminate this productivity killer, teams must consistently log manual tasks during weekly operations. Once identified, engineers write reusable software scripts or deploy orchestration tools to handle these tasks automatically, permanently freeing up valuable engineering time.
Incident Management & Postmortems
When unexpected outages inevitably hit production, a highly structured incident management framework ensures the engineering team responds calmly and efficiently. Organizations must cultivate an explicitly blameless culture that assumes engineers always make decisions with the best available information.
Following the successful mitigation of an outage, teams conduct a detailed postmortem to perform a deep root cause analysis. This process documents exactly what went wrong, why the safeguards failed, and what concrete engineering tasks must be scheduled to prevent the issue from reoccurring.
Capacity Planning
Capacity planning allows infrastructure teams to forecast system resource consumption accurately and prepare platforms well ahead of major demand spikes. Without proactive planning, unexpected seasonal traffic spikes can instantly overwhelm backend databases and cause widespread system failure.
Engineers analyze historical trends, evaluate hardware constraints, and execute simulated load tests to understand how systems behave under heavy strain. This data allows companies to purchase cloud resources efficiently, optimize software efficiency, and set up dynamic auto-scaling rules that handle fluid user traffic.
The Four Golden Signals of Pipeline Performance
To gain complete, immediate clarity on infrastructure health, reliability specialists focus intensely on tracking the four golden signals:
- Latency: The precise time it takes for a system to process a specific request, distinguishing carefully between successful transactions and failed operations.
- Traffic: A direct measurement of overall demand being placed on the network infrastructure, such as total HTTP requests per second or concurrent database connections.
- Errors: The exact rate of requests that fail completely, fail to return the correct data payload, or trigger unexpected system exceptions.
- Saturation: A metric defining how full the underlying system resources are, highlighting constraints like memory utilization, disk I/O limits, or network bandwidth caps.
Platform Implementation vs. Culture — What’s the Real Difference?
| Operational Vector | Technical Platform Implementation | Cultural Reliability Framework |
| Primary Focus | Managing specific software tools, script automation, and live telemetry infrastructure. | Driving collaborative team mindsets, operational accountability, and shared engineering goals. |
| Execution Method | Deploying monitoring tools, configuring CI/CD pipelines, and writing automation code. | Practicing blameless postmortems, defining error budgets, and actively managing systemic risk. |
The Philosophy Difference
Technical platform implementation focuses entirely on deploying software tools, configuring automated monitoring stacks, and maintaining physical or virtual cloud servers. This mechanical layer provides the raw telemetry data and automation scripts required to run modern applications smoothly.
In sharp contrast, cultural reliability frameworks focus deeply on shifting human mindsets, establishing shared organizational responsibilities, and eliminating operational friction between teams. Deploying advanced telemetry tools provides zero business value if the underlying culture continues to blame individual engineers for systemic architectural failures.
Roles & Responsibilities Compared
- Platform Engineers: Design, build, and continuously maintain the internal self-service cloud infrastructure, deployment pipelines, and centralized tooling that application development teams utilize daily.
- Reliability Specialists: Partner directly with software developers to optimize live application performance, manage production risk, configure SLOs, and orchestrate real-time incident response workflows.
- Development Teams: Focus primarily on writing clean application features, fixing software bugs, and spending their available error budgets safely to drive rapid business value.
Can You Have Both Disciplines?
Modern technology organizations absolutely can—and should—embrace both technical platform implementation and cultural reliability disciplines simultaneously to maximize operational efficiency. In fact, these two engineering philosophies naturally support and reinforce each other across the enterprise lifecycle.
The platform engineering team builds the automated self-service infrastructure foundations that make observing systems and deploying code incredibly easy. Meanwhile, the reliability framework ensures the organization uses those tools effectively to defend user experiences, track error budgets, and learn from systemic outages.
Which One Should Your Team Adopt?
Choosing whether to prioritize platform engineering or cultural reliability frameworks depends heavily on your current organization size and engineering maturity:
- Small Startups: Focus first on establishing a shared cultural reliability framework to keep team dependencies clear and prevent early operational silos.
- Mid-Sized Companies: Begin building standardized platform automation pipelines to ensure deployments remain highly repeatable across multiple expanding software teams.
- Large Enterprises: Maintain distinct, collaborative platform engineering and reliability teams to manage massive global infrastructure footprints efficiently at scale.
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Global technology leaders leverage real-time operational metrics to automate critical business decisions and protect massive digital pipelines. For example, prominent streaming providers track granular playback latency metrics across millions of concurrent client applications worldwide.
If regional network performance drops below an established service level indicator, internal routing engines instantly shift user traffic to alternative data centers. This automated redirection happens seamlessly in seconds, ensuring consumers enjoy uninterrupted streaming experiences without even realizing a major infrastructure fault occurred behind the scenes.
Chaos Engineering Approaches to Resilient Systems
Advanced engineering groups practice chaos engineering to proactively uncover hidden architectural vulnerabilities before they manifest as catastrophic user outages. These teams intentionally inject controlled failures—such as shutting down random microservices, introducing artificial network latency, or corrupting specific database records—directly into live production environments.
+-----------------------------------------------------------+
| Chaos Engineering Workflow |
+-----------------------------------------------------------+
| |
| 1. INJECT FAULT --> Intentionally turn off servers or |
| introduce artificial latency. |
| |
| 2. OBSERVE --> Watch how surrounding systems and |
| automated alerts respond. |
| |
| 3. RECOVER --> Verify that self-healing systems |
| automatically stabilize traffic. |
| |
| 4. HARDEN --> Fix any discovered structural |
| weaknesses permanently. |
| |
+-----------------------------------------------------------+
By observing how surrounding systems respond to real-world stress, engineers verify whether automated self-healing mechanisms function as designed. This proactive experimentation allows teams to discover edge-case bugs and harden system defenses during normal business hours.
Handling Reliability at Massive Scale
Hyper-scale e-commerce platforms manage millions of checkout transactions simultaneously by decoupling critical application layers into isolated, independent microservices. If the non-essential product recommendation engine crashes under heavy promotional traffic, the primary payment gateway continues processing orders completely uninterrupted.
Reliability engineers implement robust circuit breakers, rate limiters, and fallback queues across these distributed pipelines. These software guardrails ensure that localized component failures never cascade across the entire environment, keeping the core revenue-generating business operations functional.
High-Availability in Fintech Operations
Financial technology platforms operate within hyper-strict regulatory environments that demand zero tolerance for transaction downtime, data loss, or network latency. To meet these rigorous demands, reliability specialists implement multi-region, active-active database cluster configurations that sync financial ledger records continuously.
Advanced monitoring systems constantly track message delivery rates and cryptographic handshake times down to the millisecond layer. Any minor performance anomaly instantly triggers automated failover protocols, ensuring financial transactions route through secure backup pipelines without disrupting global payment flows.
Scaled-Down but Essential Systems for Startups
Early-stage startups do not require massive, expensive multi-region setups, yet they still require foundational reliability practices to survive market competition. Small technical teams apply core operations principles efficiently by utilizing managed cloud services that offer built-in logging, automated backups, and basic scaling rules.
By defining simple, practical SLOs early on, a startup can avoid over-engineering its infrastructure while maintaining excellent visibility into user-facing bugs. This lean approach protects the young company’s limited engineering velocity, allowing it to iterate features rapidly without sacrificing baseline application uptime.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
A frequent and costly mistake organizations make is treating reliability engineers as an exclusive, reactive team dedicated solely to handling overnight alerts. When teams operate with this flawed perspective, they completely fail to fix the underlying architectural flaws causing the alerts in the first place.
True reliability management is a proactive software engineering discipline focused on building automation to prevent incidents entirely. If engineers spend their whole shift firefighting live production issues, they never gain the time required to build sustainable, self-healing systems.
Mistake 2 — Setting Unrealistic SLOs
Many product leaders mistakenly demand perfect $100\%$ uptime metrics, believing that higher reliability targets always yield better business outcomes. However, demanding flawless performance stalls software feature releases completely, forces engineers into endless compliance meetings, and rapidly burns out technical talent.
[ Uptime Target Trade-offs ]
+------------------------------------------+
| 100% Target: Stalled Releases & Burnout |
+------------------------------------------+
| 99% Target: Rapid Innovation Buffer |
+------------------------------------------+
An unrealistic reliability target leaves absolutely zero error budget for shipping experimental features or conducting necessary infrastructure maintenance. Smart teams recognize that user satisfaction plateaus after a certain threshold, choosing reasonable objectives that preserve operational agility.
Mistake 3 — Ignoring Toil Until It’s Too Late
Ignoring repetitive manual tasks causes massive operational debt to accumulate silently within an expanding engineering organization. In the early stages, running a manual script or resetting a server thread once a day seems like a harmless minor chore.
However, as the application scales to thousands of active cloud instances, that minor chore multiplies into a massive bottleneck that devours engineering velocity. If leadership fails to prioritize automated toil elimination, the technical team eventually becomes completely paralyzed by routine operational maintenance.
Mistake 4 — Skipping Blameless Postmortems
When teams search for a human scapegoat following an expensive production outage, they severely damage the organization’s long-term engineering health. In a culture of blame, engineers actively hide technical mistakes, avoid touching fragile legacy code, and cover up operational vulnerabilities to protect themselves.
Skipping honest, blameless postmortems prevents an organization from identifying the true systemic flaws that allowed the human error to occur. Cultivating a safe, transparent learning environment is the only way to convert operational failures into robust system defenses.
Mistake 5 — Monitoring Without Actionable Alerts
Flooding engineering communication channels with hundreds of low-priority notifications creates dangerous alert fatigue across the technical organization. When sirens sound constantly for minor warnings that require no immediate human intervention, engineers naturally begin ignoring all alerts entirely.
Eventually, a catastrophic production outage strikes silently because the critical notification was buried deep inside a mountain of irrelevant operational noise. Teams must ensure that every active alert is strictly actionable, clearly documented, and routed directly to the appropriate engineer.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Excluding reliability professionals from initial application architecture discussions represents a major planning failure that introduces severe downstream operational risks. Software developers often build features assuming ideal laboratory conditions, completely overlooking real-world variables like network latency, partial dependencies, and scaling limits.
+-----------------------------------------------------------+
| Collaborative Architecture Lifecycle |
+-----------------------------------------------------------+
| |
| 1. DESIGN STAGE --> Dev + SRE collaborate to ensure |
| production-ready architecture. |
| |
| 2. BUILD STAGE --> Automated pipelines test and build|
| resilient code artifacts. |
| |
| 3. OPERATE STAGE --> Production telemetry monitors real|
| user journeys smoothly. |
| |
+-----------------------------------------------------------+
When systems are thrown over the wall to operations at the last minute, they frequently crash under real production stress. Involving reliability experts from day one ensures platforms are built with robust logging, clear metrics, and graceful degradation paths.
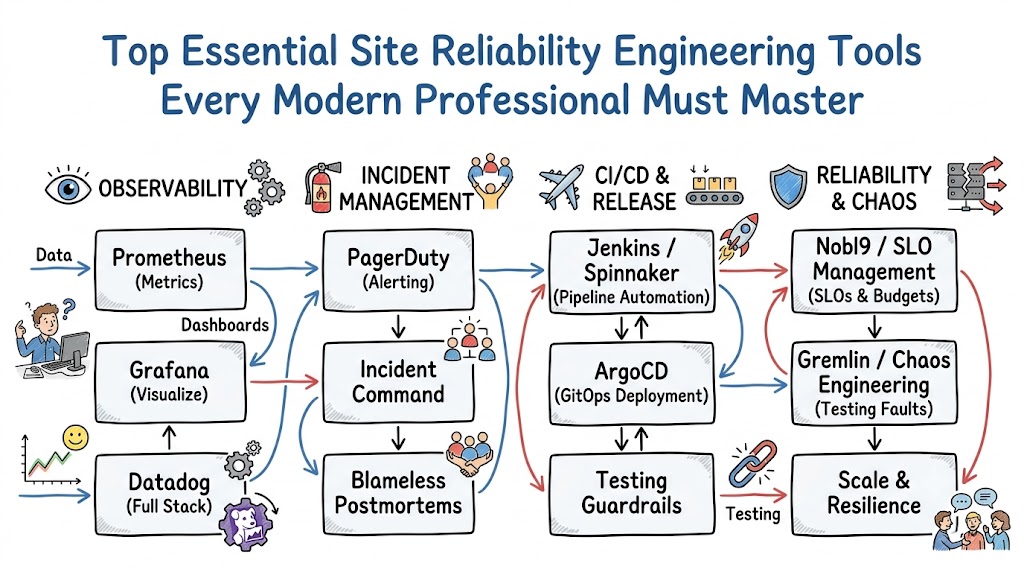
Essential Infrastructure Tools & Technologies
| Tool Category | Core Industry Platforms | Primary Engineering Function |
| Monitoring & Observability | Prometheus, Grafana, Datadog, New Relic | Gathering detailed metrics, visualizing dashboards, and tracing distributed requests across environments. |
| Incident & Deployment | PagerDuty, Jenkins, Spinnaker, Argo CD | Organizing real-time emergency responses and automating application software deployment pipelines. |
Monitoring & Observability
Engineers utilize core industry platforms like Prometheus and Grafana to gather detailed performance metrics and visualize live infrastructure trends over time. For enterprise environments requiring centralized data views, platforms such as Datadog and New Relic provide deep, end-to-end trace visibility across complex cloud applications.
These monitoring technologies act as the team’s eyes in production, constantly measuring resource consumption and application health. By establishing robust telemetry collection networks, organizations can detect microscopic anomalies long before they escalate into noticeable user-facing outages.
Incident Management
When critical systems breach their established performance thresholds, incident management platforms like PagerDuty orchestrate rapid, structured engineering responses. These intelligent platforms ingest alert streams from monitoring tools, filter out irrelevant noise, and immediately wake up the specific on-call engineer assigned to that infrastructure layer.
Additionally, they provide clear escalation pathways, secure emergency communication channels, and links to pre-written runbooks to accelerate resolution. Effective incident management tools ensure teams coordinate calmly, minimize costly downtime, and keep external stakeholders informed throughout the resolution window.
CI/CD & Release Engineering
Automating the testing and delivery of software updates requires powerful release engines like Jenkins, Spinnaker, and Argo CD. These platforms systematically package application code, run comprehensive security scans, and deploy updates smoothly across cloud environments without requiring manual intervention.
By utilizing GitOps workflows with Argo CD, teams ensure that the live infrastructure state always matches the exact configuration defined in secure code repositories. This automated precision guarantees that deployments remain completely repeatable, transparently auditable, and highly resilient against human configuration errors.
Chaos Engineering
Injecting controlled disruptions into live environments requires specialized tools like Chaos Monkey and advanced chaos testing suites. These frameworks are designed to safely terminate random production instances or inject artificial packet loss into isolated application networks.
By forcing infrastructure to experience unexpected stress under controlled conditions, engineers can actively verify whether their automated failover systems respond correctly. This intentional testing exposes weak timeout configurations, hidden single points of failure, and flawed auto-scaling rules before they trigger actual user downtime.
SLO Management
Tracking long-term reliability metrics against explicit consumer thresholds requires dedicated SLO management platforms like Nobl9. These systems aggregate raw telemetry data from multiple monitoring sources to calculate real-time error budgets and predict future SLO violations.
By providing clear, intuitive dashboards detailing exactly how much error budget remains, Nobl9 helps bridge the communication gap between business managers and technical teams. This clear data ensures that organizations make objective, metric-driven decisions regarding feature release velocities and stability investments.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
To launch a successful career in this highly technical field, you must build a commanding mastery over foundational software engineering and infrastructure concepts. First, you need deep, hands-on familiarity with Linux terminal commands, shell scripting, and advanced networking protocols like TCP/IP and DNS.
Next, you must master modern cloud infrastructure concepts, focusing intensely on containerization with Docker and cluster orchestration with Kubernetes. Finally, learning a versatile programming language like Python or Go is absolutely essential for writing custom automation tools and managing infrastructure as code.
[ Essential Operations Skill Stack ]
+----------------------------------+
| Automation (Python, Go, IaC) |
+----------------------------------+
| Containerization & K8s Orchestrate|
+----------------------------------+
| Linux Terminal & Core Networking |
+----------------------------------+
The Professional Learning Path
The learning path begins by working as a standard system administrator or junior software engineer to understand how applications behave in live environments. From there, transition into learning infrastructure automation by mastering tools like Terraform, Ansible, and basic CI/CD pipeline structures.
Next, focus your studies on advanced observability architectures, learning how to configure distributed tracing networks and define mathematically sound SLOs. Finally, step into senior architecture roles where you design massive, fault-tolerant systems that automatically self-heal and handle unpredictable global traffic swings.
Certifications Worth Pursuing
Earning industry-recognized credentials validates your specialized technical knowledge and opens up lucrative career paths globally. Aspiring reliability professionals should pursue advanced cloud certifications like the AWS Certified DevOps Engineer or Google Cloud Professional Cloud DevOps Engineer.
Additionally, securing the Certified Kubernetes Application Developer (CKAD) or Certified Kubernetes Administrator (CKA) credential proves you can manage containerized workloads under high pressure. These rigorous certifications demonstrate to enterprise employers that you possess the practical skills required to defend complex production infrastructure.
Educational Resources with Sreschool
Mastering these complex technologies requires structured, hands-on guidance from industry veterans who have managed real-world production crises at massive scale. Aspiring specialists can explore the comprehensive educational courses, interactive labs, and deep-dive technical materials provided directly by Sreschool.
The specialized curriculum is carefully designed to transform theoretical system engineering concepts into practical, day-to-day infrastructure management skills. By working through realistic production failure scenarios, students build the deep operational confidence required to manage enterprise-grade cloud platforms efficiently.
The Future of Systems Management
AI and Automation in System Optimization
Artificial intelligence and advanced machine learning models are fundamentally transforming how enterprises monitor and optimize their production pipelines. Modern AIOps platforms analyze billions of telemetry data points in real time to detect complex anomaly patterns that human operators would completely miss.
These smart systems can predict potential hardware failures, automatically adjust auto-scaling limits ahead of traffic surges, and instantly isolate root causes during major outages. By accelerating incident triage, machine intelligence empowers reliability teams to resolve structural issues long before users experience a service drop.
Platform Engineering — The Evolution of Infrastructure
Platform engineering is rapidly reshaping modern application delivery by creating standardized internal developer platforms that simplify the entire software lifecycle. Instead of forcing software developers to navigate complex cloud setups independently, platform teams provide secure, automated self-service portals.
+-----------------------------------------------------------+
| Internal Developer Platform (IDP) |
+-----------------------------------------------------------+
| |
| +-------------+ +-------------------+ |
| | Application | ----> | Secure, Automated | |
| | Developers | | Self-Service | |
| +-------------+ | Internal Platform | |
| +---------+---------+ |
| | |
| v |
| +-------------------+ |
| | Pure Cloud Infra | |
| +-------------------+ |
| |
+-----------------------------------------------------------+
With a single click or terminal command, a developer can safely provision a database, configure network routes, and launch a compliant testing environment. This evolutionary shift eliminates repetitive tickets, hardens security boundaries, and allows engineering organizations to scale feature velocity safely.
Management in Cloud-Native & Kubernetes Environments
As enterprise applications transition fully into dynamic, containerized cloud-native topologies, managing infrastructure stability requires entirely new tracking paradigms. Traditional static server monitoring is completely obsolete when container instances spin up and shut down every few minutes across massive Kubernetes clusters.
Modern operations teams utilize service meshes like Istio and advanced eBPF-based telemetry tools to track network communication paths directly within the operating system kernel. These cloud-native approaches provide instant visibility into microservice interactions, securing dynamic cluster environments at scale.
Operational Skills That Will Matter Most
In the coming years, the most successful infrastructure professionals will possess a unique blend of deep technical observability and sharp financial literacy. As corporate cloud computing environments expand globally, businesses are prioritizing financial cost optimization, commonly known as FinOps, alongside baseline system performance.
Engineers must learn to design highly efficient system architectures that maximize application throughput while minimizing cloud resource waste. Additionally, mastering deep data observability and cross-platform security automation will remain critical as enterprise environments grow increasingly complex.
FAQ Section
- What is the typical career path to becoming a Site Reliability Engineer?Most professionals start as software developers or system administrators, then learn cloud automation, container orchestration, and observability tools before transitioning into dedicated reliability engineering roles.
- How do Site Reliability Engineering practices differ from traditional DevOps workflows?DevOps is a broad cultural philosophy focused on breaking down organizational silos, whereas reliability engineering is a specific, concrete implementation of that philosophy using explicit software engineering practices.
- What are the entry-level salary trends for infrastructure specialists in this domain?Entry-level salaries remain highly competitive across major tech hubs, typically starting well into six figures due to the specialized nature of the automation and system safety skills required.
- Why is an error budget considered a critical tool for product development velocity?An error budget provides a clear, mathematical metric that balances code innovation speed with system safety, defining exactly when a team can ship features or when they must focus on stability.
- Which coding languages are most important for automated infrastructure scripting?Python and Go are the dominant programming languages utilized across modern cloud infrastructure due to their extensive libraries, excellent performance, and deep integration with popular automation tools.
- How does Chaos Engineering help protect financial transaction platforms from major outages?By intentionally injecting controlled network delays or server faults, chaos engineering allows fintech teams to verify that automated backup clusters and self-healing mechanisms protect transactions seamlessly during real emergencies.
Final Summary
Maintaining optimal system health within modern distributed architectures requires a continuous, disciplined commitment to deep monitoring visibility, automated toil elimination, and objective metric-driven error budgets. By shifting away from reactive manual firefighting and embracing a proactive software engineering approach, organizations build resilient platforms that gracefully survive real-world production stress. True operational excellence is achieved when engineering mindsets and advanced automation platforms align seamlessly to defend user journeys. To master these advanced architectural strategies and accelerate your professional infrastructure career, explore the industry-leading learning paths and expert mentorship available at Sreschool.
Many SRE tool discussions focus on capabilities, but tool integration complexity often determines long-term success. As organizations adopt multiple platforms for monitoring, incident management, automation, and observability, maintaining consistent data flow and reducing alert silos becomes a significant operational challenge that requires ongoing governance.