Imagine a sudden, massive system disruption crashing your payment gateway right during peak holiday traffic hours. The engineering team frantically scrambles, yet fingers point in every direction while users vent their frustration on social media platforms. This nightmare scenario highlights the classic operational bottleneck that modern, highly distributed software organizations face every single day. Therefore, shifting toward structured collaboration becomes absolutely critical to maintaining baseline system sanity and software deployment velocity.
Modern tech infrastructure requires a seamless blend of rapid feature deployment and rock-solid architectural stability. To achieve this balance, industry leaders rely heavily on specific methodologies designed to bridge the historical gap between software creation and systems administration. Consequently, understanding how these frameworks function together helps engineering leaders build resilient platforms that scale effortlessly.
This comprehensive guide covers everything from early infrastructure roots to detailed operational execution models. You will explore core principles, key operational concepts, and concrete real-world case studies from major enterprises. Additionally, this guide outlines common implementation pitfalls, essential toolsets, and a complete professional career roadmap for aspiring engineers.
To accelerate your operational journey, you can master these cutting-edge methodologies by exploring the advanced technical programs at Sreschool. Let us dive deep into the mechanics of these powerful engineering disciplines.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
For decades, traditional software development and IT infrastructure teams lived in completely isolated silos. Developers focused solely on writing code and pushing out new features as quickly as possible. Meanwhile, operations teams carried the heavy burden of maintaining system uptime and protecting server stability.
Consequently, this sharp division created a massive wall of confusion inside tech corporations. Developers threw unstable code over the wall, while operations professionals resisted system updates to avoid catastrophic crashes. This constant friction resulted in slow deployments, buggy software releases, and incredibly stressed engineering departments.
Moving Toward Unified Workflow Automation
As the demand for web-scale applications exploded, forward-thinking organizations realized that manual infrastructure handoffs were no longer sustainable. Therefore, early pioneers began automating internal build pipelines and treating infrastructure configuration as code templates.
This cultural shift aimed to unify development and operations into a single continuous workflow. By sharing tools and responsibilities, teams radically accelerated delivery timelines. As a result, software updates moved smoothly from local environments to production environments with significantly less human intervention.
Global Expansion Across Commercial Ecosystems
Over time, these automated workflow practices matured into formalized industry standards across global enterprise networks. Major cloud infrastructure providers and tech giants embraced these agile methodologies to manage millions of concurrent user sessions.
Eventually, this evolution split into complementary engineering pathways designed to solve the scale dilemma. Today, these frameworks form the absolute backbone of modern digital services, cloud applications, and automated corporate platforms.
Defining Strategic Operations Management
The Core Operational Structure
To understand modern environments, we must examine the specific architecture governing how software behaves after deployment. The underlying framework relies on continuous feedback loops connecting monitoring telemetry directly back to code repositories.
[Software Code Development] ---> [Continuous Integration Pipeline]
^ |
| v
[Telemetry & Monitoring Feedback] <--- [Live Production Deployment]
Furthermore, data flows dynamically across automated testing stages, validation gateways, and deployment clusters. This structural framework ensures that any systemic abnormality triggers immediate alerts before affecting end users.
Daily Tasks of Systems Coordinators
Engineers operating within this sphere do not simply sit back and wait for infrastructure pieces to break. Instead, they spend their days writing automation scripts, configuring monitoring dashboards, and building delivery pipelines.
On any given morning, a specialist might tune container orchestration parameters or optimize query performance. Later, they might review infrastructure alerts, update deployment templates, or coordinate emergency response patches.
Localized Control vs. Broad System Architecture
Managing modern applications requires a careful balance between micro-level component tracking and macro-level system architecture design. For instance, an engineer must monitor individual database query latencies to keep specific services responsive.
Simultaneously, they must maintain a holistic view of the entire multi-region cloud cluster topology. Neglecting localized controls causes hidden software bottlenecks, while ignoring broad system architecture leads to total infrastructure fragmentation.
The Efficiency Mindset
At its heart, this approach requires a cultural mindset that prioritizes long-term systemic reliability over short-term feature rushed delivery. Teams must view every single infrastructure failure as an optimization opportunity rather than a simple maintenance chore.
Therefore, investing time into building self-healing systems directly eliminates recurring manual issues. This proactive focus allows digital organizations to maintain extreme agility while safeguarding baseline consumer trust.
The 7 Core Principles of SRE vs DevOps: Understanding the Key Differences
1. Embracing Risk and Managing Variability
First and foremost, modern engineering teams must accept that perfect 100% uptime is a completely unrealistic goal. Every component, network switch, and cloud instance will eventually fail at some point.
Instead of striving for impossible perfection, teams focus on managing acceptable systemic risk profiles. They calculate exactly how much downtime their application can safely tolerate without causing major user dissatisfaction.
2. Establishing Service Level Objectives (SLOs)
To manage risk effectively, engineering teams must define precise, measurable targets for operational success. These metrics guide balancing feature velocity with architectural safety.
| Metric Type | Definition | Focus Area |
| SLI | Service Level Indicator | Real-time objective measurement of system performance |
| SLO | Service Level Objective | Target reliability goal agreed upon by engineering teams |
| SLA | Service Level Agreement | Legal commitment made directly to the end business consumers |
By utilizing these clear metrics, departments make data-driven decisions regarding when to deploy new code.
3. Eliminating Toil and Manual Processes
Toil represents repetitive, manual, operational work that provides no long-term structural value and scales linearly with system size. Examples include manually restarting servers or running routine data cleanups every afternoon.
Modern engineering frameworks aggressively target and eliminate this administrative overhead through programmatic solutions. By engineering automated fixes, specialists free up precious time to focus on strategic scalability projects.
4. Monitoring & Observability Across the Pipeline
You cannot fix or optimize what you cannot see inside your production clusters. Therefore, building deep visibility across the entire deployment pipeline remains a foundational principle.
[System Telemetry Data] ---> [Metrics, Logs, and Traces] ---> [Actionable Observability Dashboards]
Comprehensive observability requires collecting granular metrics, application logs, and distributed request traces. This continuous stream of data prevents operational blind spots and speeds up system troubleshooting during live outages.
5. Automation Over Manual Coordination
Scaling complex software systems by simply hiring more operations staff is an expensive, inefficient strategy. Instead, organizations leverage code-driven automation to manage expanding server fleets.
From automated server provisioning to self-healing scaling policies, code replaces manual administrative coordination. Consequently, this engineering-first approach allows small teams to manage massive cloud footprints successfully.
6. Release Engineering and Deployment Stability
Safe, predictable application delivery requires strict discipline across all release engineering practices. Teams utilize version-controlled configuration files and automated testing suites to validate software updates.
Furthermore, employing canary deployments or blue-green strategies minimizes the blast radius of bad code updates. If a bug slips through, automated rollbacks instantly restore the last known stable system state.
7. Simplicity in Network Architecture
Finally, keeping system architecture clean, minimal, and modular directly reduces the overall failure surface area. Complex, tangled systems make debugging nearly impossible during high-stress production incidents.
Engineers explicitly design systems to be as simple as possible, removing unnecessary components and redundant data paths. This explicit focus on simplicity ensures predictable system behavior under heavy transaction volumes.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Understanding the subtle differences between these three foundational terms is essential for any modern infrastructure specialist.
- Service Level Indicators (SLIs): These are the specific, real-time measurements of your system’s behavior, such as latency or error rates.
- Service Level Objectives (SLOs): This is the target metric your team binds itself to, defining the acceptable boundary for your SLIs.
- Service Level Agreements (SLAs): This represents the overarching business contract promising specific uptime levels to paying clients, often carrying financial penalties.
Error Budgets — The Game Changer for Operational Risk
The error budget is the exact mathematical headroom left after subtracting your SLO target from 100%. For example, a 99.9% uptime objective leaves an error budget of exactly 0.1% allowable downtime.
This metric acts as a dynamic safety valve for development and infrastructure teams. As long as the error budget remains green, developers can push out experimental features rapidly. However, if the budget depletes, feature releases halt instantly so teams can focus entirely on system stabilization.
Toil — The Silent Productivity Killer in Infrastructure
Toil slowly drains engineering energy and blocks organizational growth. To eliminate it, teams must calculate how much time they spend on manual administrative chores.
Total Engineering Time
|--- Operational Toil (Target: Keep below 50%)
|--- Proactive Engineering (Target: Maintain above 50%)
If repetitive tasks consume more than half of a team’s weekly capacity, the system is fundamentally broken. Organizations must systematically automate these tasks away, ensuring engineers spend most of their time on proactive design work.
Incident Management & Postmortems
When severe outages occur, modern organizations run toward the problem using a structured, blameless incident management framework. The primary goal is rapidly restoring service rather than searching for an individual to blame.
Following resolution, teams conduct formal postmortems to uncover the structural root causes of the failure. Writing down these lessons ensures the organization builds permanent technical guardrails to prevent identical breakdowns.
Capacity Planning
Infrastructure demand fluctuates wildly based on seasonal trends, marketing campaigns, and organic business growth. Capacity planning involves analyzing historical telemetry data to forecast future computing resource needs.
Proper planning ensures that networks, databases, and compute clusters scale up smoothly before consumer traffic spikes hit. This proactive forecasting protects user experience while keeping cloud infrastructure expenditures optimized.
The Four Golden Signals of Pipeline Performance
When monitoring complex distributed applications, engineers prioritize four critical performance metrics.
- Latency: The exact time it takes to service a specific request, separating successful responses from failures.
- Traffic: A direct measure of system demand, tracking concurrent users or network requests per second.
- Errors: The rate of requests that fail completely or return incorrect response codes.
- Saturation: A metric tracking how full your system resources are, emphasizing memory, CPU, and disk constraints.
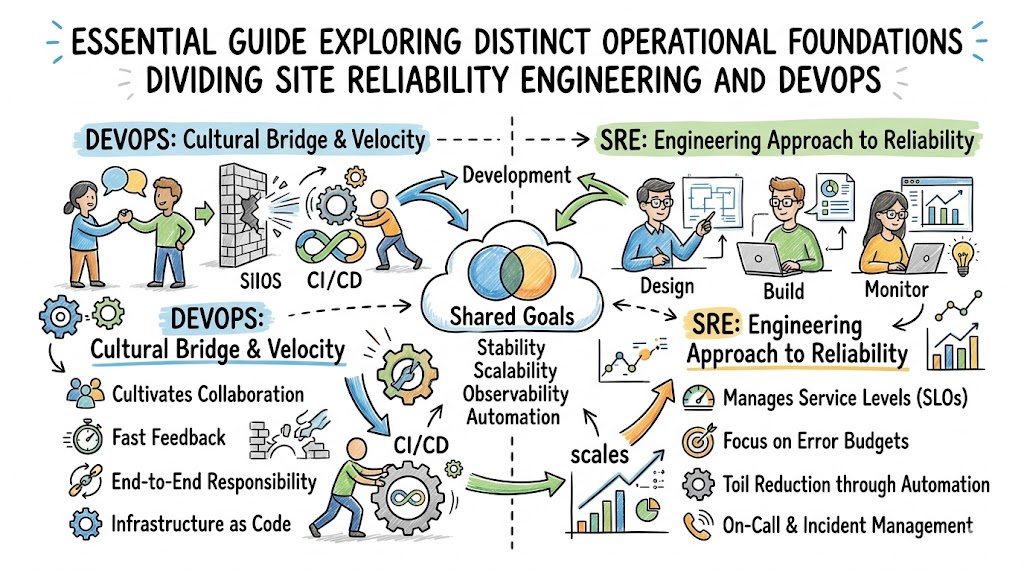
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
DevOps functions primarily as a broad, high-level cultural philosophy aimed at destroying organizational silos. It focuses intensely on shared responsibility, cultural alignment, and rapid feedback loops between people.
Conversely, Site Reliability Engineering (SRE) behaves as a specific, highly technical implementation of that philosophy. As industry veterans often say, SRE happens when you ask a software engineer to design an operations function.
Roles & Responsibilities Compared
To understand how these concepts operate on a day-to-day basis, we can look closely at their core task assignments.
- DevOps Focus Areas:
- Building continuous integration and continuous delivery pipelines.
- Promoting cultural collaboration between developers and operators.
- Standardizing tools across various internal engineering teams.
- Measuring overall delivery velocity and team performance metrics.
- SRE Focus Areas:
- Writing code to automate manual infrastructure processes.
- Managing error budgets and defining system SLOs.
- Conducting deep root-cause analysis during postmortems.
- Optimizing application performance, scaling, and availability.
Can You Have Both Disciplines?
Absolutely, these two operational methodologies are not mutually exclusive competitors. Instead, they complement each other perfectly within a progressive, scaling enterprise organization.
While your cultural advocates promote open communication and tool standardization across the company, your technical specialists dive deep into code automation. Together, they create a highly resilient, hyper-efficient software factory.
Which One Should Your Team Adopt?
Choosing the right starting point depends heavily on your current organizational size and structural maturity.
| Company Size | Recommended Approach | Implementation Focus |
| Early Startups | Culture-First DevOps | Unifying small teams with shared tools and flexible duties |
| Mid-Market Companies | Structured Pipeline Automation | Scaling delivery setups and standardizing cloud environments |
| Large Scale Enterprises | Specialized SRE Teams | Dedicating engineers to strict error budgets and automated scaling |
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
Global streaming networks and massive e-commerce sites process hundreds of thousands of transactions every second. To survive, these enterprises track live telemetry data on massive operational control walls.
If latency numbers tick upward in a specific region, automated systems instantly route traffic to healthy data centers. This real-time metrics tracking ensures that users experience zero disruption, even during major infrastructure adjustments.
Chaos Engineering Approaches to Resilient Systems
Top-tier software organizations do not wait around for natural disasters to test their disaster recovery plans. Instead, they actively inject chaos into production environments during regular business hours using automated tools.
By intentionally killing random server instances, they verify that their applications automatically heal without human intervention. This proactive practice uncovers hidden flaws long before they turn into real-world consumer emergencies.
Handling Reliability at Massive Scale
Distributed microservices architectures bring immense flexibility, but they also introduce severe communication complexities. A single user click might trigger a cascading chain of fifty distinct internal API calls.
Organizations use specialized service meshes and distributed tracing to manage this intricate web of dependencies. This architecture allows them to isolate failing microservices instantly, preserving overall system availability.
High-Availability in Fintech Operations
Financial technology platforms operate under strict regulatory compliance rules and zero-tolerance downtime mandates. A single minute of database lag can disrupt millions of dollars in processing volume.
Therefore, fintech teams implement multi-region, active-active database replication setups along with instant failover automation. They prioritize total data consistency and absolute operational reliability above all else.
Scaled-Down but Essential Systems for Startups
Early-stage startups do not possess the massive engineering budgets of global tech conglomerates. However, they still apply these fundamental principles by leveraging managed cloud services.
By utilizing managed container platforms and basic infrastructure-as-code scripts, a tiny three-person team can run highly resilient applications. This lean approach provides excellent operational stability without creating massive administrative overhead.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
Many organizations make the critical error of simply rebranding their traditional operations staff as modern engineers. They continue drowning these teams in endless manual alerts without giving them time to fix the root causes.
True modern infrastructure engineering requires dedicated time for writing automation code. If your team spends all day fighting fires, they are not practicing proactive reliability engineering.
Mistake 2 — Setting Unrealistic SLOs
Inexperienced management teams often demand perfect 100% uptime goals for their digital applications. This unrealistic expectation creates massive organizational friction and stalls software delivery completely.
Demanding absolute perfection burns out your engineering staff and wastes valuable financial resources on unnecessary infrastructure redundancy. Smart teams set realistic objectives that balance user happiness with operational agility.
Mistake 3 — Ignoring Toil Until It’s Too Late
When engineering departments scale rapidly, manual tasks can quickly accumulate like unmanaged credit card debt. If engineers ignore these minor manual tasks, they eventually become overwhelmed by administrative friction.
[Neglecting Small Toil Chores] ---> [Accumulating Massive Operational Debt] ---> [Total Team Burnout]
Eventually, the entire team’s velocity slows to an absolute crawl. Organizations must establish strict limits on manual work, forcing teams to automate processes before they spin out of control.
Mistake 4 — Skipping Blameless Postmortems
When a major production system crashes, human nature often drives people to find a convenient scapegoat. If leadership punishes individuals for system failures, engineers quickly learn to hide mistakes.
Consequently, this defensive behavior prevents the organization from discovering the true underlying architectural flaws. Running truly blameless reviews is the only way to build a transparent, learning engineering culture.
Mistake 5 — Monitoring Without Actionable Alerts
Drowning your engineering team in hundreds of low-priority email notifications creates severe alert fatigue. When everything is classified as an emergency, nothing gets treated like one.
Engineers eventually tune out notifications, causing them to miss real, critical system failures when they occur. Every single alert hooked to an on-call pager must be clear, actionable, and require immediate human intervention.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Software developers often build complex application features without ever consulting the teams responsible for running them. This disconnect leads to unscalable designs that crash immediately under real-world production stress.
Operational specialists must sit at the design table from day one. Their architectural insights ensure that new software features are born observable, scalable, and highly resilient.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
To maintain deep visibility into complex infrastructure clusters, teams rely on advanced monitoring tools. Platforms like Prometheus and Grafana allow engineers to scrape real-time metrics and visualize them on clean dashboards.
For enterprise environments, Datadog and New Relic offer end-to-end distributed tracing across complex microservices. These systems ensure that performance bottlenecks are caught before they cascade into widespread outages.
Incident Management
When critical production issues strike, teams use specialized incident routing platforms to coordinate their engineering response. Tools like PagerDuty ensure that the right on-call engineer is notified instantly via multiple communication channels.
These platforms manage complex escalation paths, track response metrics, and integrate directly with internal team chat rooms. This automation keeps incident response structured and efficient during high-stress situations.
CI/CD & Release Engineering
Automating the software delivery pipeline requires powerful continuous integration and continuous deployment engines. Jenkins remains a highly reliable workhorse for traditional build automation tasks across many enterprise landscapes.
Meanwhile, cloud-native teams lean heavily on GitOps controllers like Argo CD and advanced deployment platforms like Spinnaker. These technologies ensure that software updates move from repositories to live clusters cleanly and safely.
Chaos Engineering
Building truly resilient systems requires specialized tools designed to inject controlled failures into production. Programs like Chaos Monkey pioneered the practice by randomly terminating virtual machine instances in live environments.
Modern chaos frameworks allow engineers to simulate network latency, disk failures, and region outages safely. Running these controlled experiments helps teams validate that their self-healing mechanisms work perfectly.
SLO Management
Tracking reliability metrics against long-term user thresholds requires dedicated objective management tools. Platforms like Nobl9 help organizations aggregate data from various monitoring sources to calculate real-time error budgets.
These specialized systems give business stakeholders and engineering leaders a clear view of systemic health trends. This high-level visibility guides data-driven conversations regarding feature deployment velocity and stability investments.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
- Linux Terminal Proficiency: Mastering basic shell commands, file system navigation, and process management.
- Scripting and Automation: Writing clean, reusable code in languages like Python or Go to automate tasks.
- Infrastructure as Code: Managing cloud networks and server clusters using tools like Terraform or Ansible.
- Containerization Fundamentals: Understanding how to build, run, and optimize Docker containers efficiently.
The Professional Learning Path
Your journey begins by mastering basic systems administration and understanding how local operating systems handle resources. Next, transition into studying networking protocols, cloud architecture, and modern continuous integration pipelines.
From there, dive deep into container orchestration platforms like Kubernetes and advanced distributed systems design. Finally, focus your attention on mastering data-driven reliability methodologies, error budget budgeting, and long-term capacity planning.
Certifications Worth Pursuing
- Certified Kubernetes Administrator (CKA): Validates your practical ability to set up and manage production clusters.
- AWS Certified DevOps Engineer: Confirms your expertise in automating deployment pipelines on public cloud infrastructure.
- HashiCorp Certified Terraform Associate: Proves your absolute mastery of infrastructure-as-code provisioning concepts.
- SRE Foundation Certification: Demonstrates a solid understanding of reliability engineering principles and metrics.
Educational Resources with Sreschool
Navigating this vast technical landscape on your own can feel incredibly overwhelming for aspiring cloud professionals. Therefore, accessing structured, expert-led training programs becomes a major competitive advantage for your career.
You can fast-track your technical growth by diving into the comprehensive, practical courses designed by industry mentors at Sreschool. Their hands-on labs prepare you to solve real-world infrastructure scaling challenges confidently.
The Future of Systems Management
AI and Automation in System Optimization
The integration of machine learning algorithms into monitoring pipelines is completely transforming how teams handle system anomalies. Future systems will automatically detect subtle performance deviations long before a human engineer notices them.
Furthermore, intelligent automation frameworks will soon execute complex root cause analyses and apply self-healing patches autonomously. This shift drastically reduces recovery times and keeps human engineers focused on creative architectural work.
Platform Engineering — The Evolution of Infrastructure
Platform engineering is rapidly emerging as the modern evolutionary step for scaling cloud infrastructure workflows. Instead of managing individual developer requests manually, operations teams build Internal Developer Platforms (IDPs).
These centralized self-service portals allow developers to provision databases, repositories, and testing environments instantly with built-in guardrails. This automation eliminates internal organizational friction and maximizes overall engineering velocity.
Management in Cloud-Native & Kubernetes Environments
As organizations shift entirely to highly dynamic, multi-cloud Kubernetes deployments, management complexity continues to rise. Orchestrating ephemeral microservices across different geographic cloud zones requires advanced networking configurations.
Future specialists must master complex service meshes, eBPF-based kernel observability, and serverless compute scaling models. Staying ahead in these containerized landscapes requires a deep understanding of cloud-native infrastructure patterns.
Operational Skills That Will Matter Most
The infrastructure professional of tomorrow must look far beyond basic scripting and simple alert configuration dashboards. Financial engineering and cloud cost optimization are quickly becoming critical skills as enterprise budgets tighten globally.
Additionally, mastering deep data observability, secure supply chain automation, and environmental sustainability tracking will define top-tier engineers. Developing these advanced capabilities ensures you remain highly sought after in an evolving digital economy.
FAQ Section
- What is the primary difference between a DevOps engineer and an SRE?DevOps focuses mainly on the cultural alignment, collaboration, and continuous delivery pipelines connecting development and operations teams. SRE acts as a specific technical implementation of that philosophy, applying software engineering practices directly to infrastructure reliability.
- How do error budgets balance feature velocity with system stability?An error budget defines the acceptable amount of system downtime your application can tolerate over a specific period. As long as the budget remains green, developers can ship features rapidly; if it depletes, work shifts entirely to stabilization.
- What are the four golden signals used in modern system monitoring?The four critical performance metrics that engineers track closely are latency, traffic, errors, and system saturation levels. Monitoring these signals ensures teams can diagnose performance degradation before it impacts the end consumer.
- Can a small early-stage startup implement site reliability engineering practices?Yes, startups can adopt these core principles early by leveraging managed cloud services and automation tools. Focusing on basic SLOs and eliminating manual toil prevents structural operational debt from piling up as the business scales.
- What programming languages are most important for modern infrastructure experts?Python and Go are the most widely used languages for building infrastructure automation, tooling, and cloud-native applications. Mastery of bash scripting also remains vital for managing daily operations inside Linux terminal environments.
- What is the role of a blameless postmortem in engineering culture?A blameless postmortem focuses on discovering the structural root causes of a system failure rather than punishing individuals. This open approach encourages teams to document lessons honestly and build permanent technical guardrails against future outages.
Final Summary
Maintaining consistent system health across modern distributed cloud architecture requires a deliberate blend of cultural alignment and rigorous code-driven automation. By implementing clear service level objectives and aggressively eliminating repetitive manual toil, engineering organizations build highly resilient platforms capable of scaling indefinitely. Ultimately, balancing rapid software deployment with rock-solid structural stability separates market leaders from struggling enterprises. Elevate your organization’s performance framework and master these critical operational methodologies today by partnering with the professional engineering mentors at Sreschool.
Organizational structure can significantly influence how DevOps and SRE practices succeed. Even with clearly defined responsibilities, misaligned ownership, communication gaps, or conflicting priorities between teams can create bottlenecks that affect both delivery speed and system reliability.