Chaos Engineering has become one of the most valuable practices in modern Site Reliability Engineering (SRE). As organizations build highly distributed systems across cloud platforms, containers, microservices, and hybrid infrastructures, the possibility of unexpected failures increases significantly. Traditional testing methods often focus on expected behaviors, while real-world environments introduce unpredictable situations such as network latency, service outages, infrastructure failures, and resource exhaustion. Chaos Engineering helps organizations prepare for these scenarios before they affect customers.
Instead of waiting for failures to occur in production, teams intentionally introduce controlled disruptions to understand system behavior under stress. This approach enables engineers to identify weaknesses, strengthen resilience, improve recovery processes, and build confidence in system reliability. As digital services become increasingly important to business operations, Chaos Engineering serves as a proactive strategy that helps organizations maintain service availability, minimize downtime, and enhance user experiences.
Organizations seeking structured learning and practical implementation strategies often explore training resources offered by Sreschool, where professionals gain deeper insights into reliability engineering, operational excellence, and modern system resilience practices.
What Is Chaos Engineering and Why Does It Matter?
Chaos Engineering is the discipline of experimenting on distributed systems by intentionally introducing failures in a controlled environment. The primary goal is to uncover weaknesses before they become major incidents. Rather than assuming systems will always operate correctly, Chaos Engineering accepts that failures are inevitable and focuses on preparing systems to withstand them.
Modern applications rely on numerous interconnected components. A single service failure can cascade through multiple systems and impact business operations. Chaos Engineering allows teams to observe how applications respond when dependencies fail, networks slow down, databases become unavailable, or infrastructure resources become constrained. Through controlled experimentation, engineers gain valuable insights into resilience mechanisms and recovery capabilities.
This approach shifts reliability from a reactive process to a proactive practice. Teams no longer wait for production incidents to expose weaknesses. Instead, they deliberately test assumptions, verify system behavior, and strengthen operational readiness. As a result, organizations reduce downtime, improve customer satisfaction, and increase confidence in system stability.
The Evolution of Chaos Engineering in Modern SRE
Site Reliability Engineering focuses on maintaining reliable, scalable, and efficient systems. As cloud-native architectures became more complex, traditional testing methods struggled to validate real-world failure scenarios. Chaos Engineering emerged as a practical solution to bridge this gap.
Early infrastructure environments consisted of monolithic applications hosted on a limited number of servers. Failures were relatively straightforward to identify and troubleshoot. Today, organizations operate thousands of microservices, containerized workloads, cloud resources, and third-party integrations. The increased complexity creates countless potential failure points.
Chaos Engineering evolved as a systematic way to validate system resilience within these dynamic environments. SRE teams now use chaos experiments to test fault tolerance, recovery automation, observability systems, alerting mechanisms, and operational processes. This evolution transformed reliability testing from occasional disaster recovery exercises into a continuous operational discipline.
Organizations that adopt Chaos Engineering often discover hidden dependencies, misconfigured failover systems, insufficient monitoring coverage, and inefficient recovery procedures. These discoveries allow teams to strengthen reliability before customers experience service disruptions.
Core Principles of Chaos Engineering
Chaos Engineering follows several foundational principles that guide experimentation and ensure meaningful outcomes. Understanding these principles helps organizations conduct effective experiments while minimizing unnecessary risk.
The first principle involves establishing a steady-state baseline. Engineers must understand normal system behavior before introducing disruptions. Key metrics such as response times, error rates, throughput, and resource utilization help define expected performance levels.
The second principle focuses on identifying real-world events. Experiments should simulate realistic failure scenarios that could occur naturally within production environments. Examples include server crashes, network interruptions, database latency, and cloud service outages.
Another important principle involves minimizing blast radius. Experiments begin with small, controlled disruptions before expanding to larger scenarios. This gradual approach reduces risk while allowing teams to gain valuable insights.
Continuous learning represents another key principle. Every experiment should generate actionable findings. Teams analyze outcomes, identify weaknesses, implement improvements, and repeat experiments to validate enhancements.
Finally, automation plays a critical role. Automated chaos experiments enable organizations to continuously validate resilience as systems evolve. This ongoing validation helps maintain reliability despite frequent infrastructure and application changes.
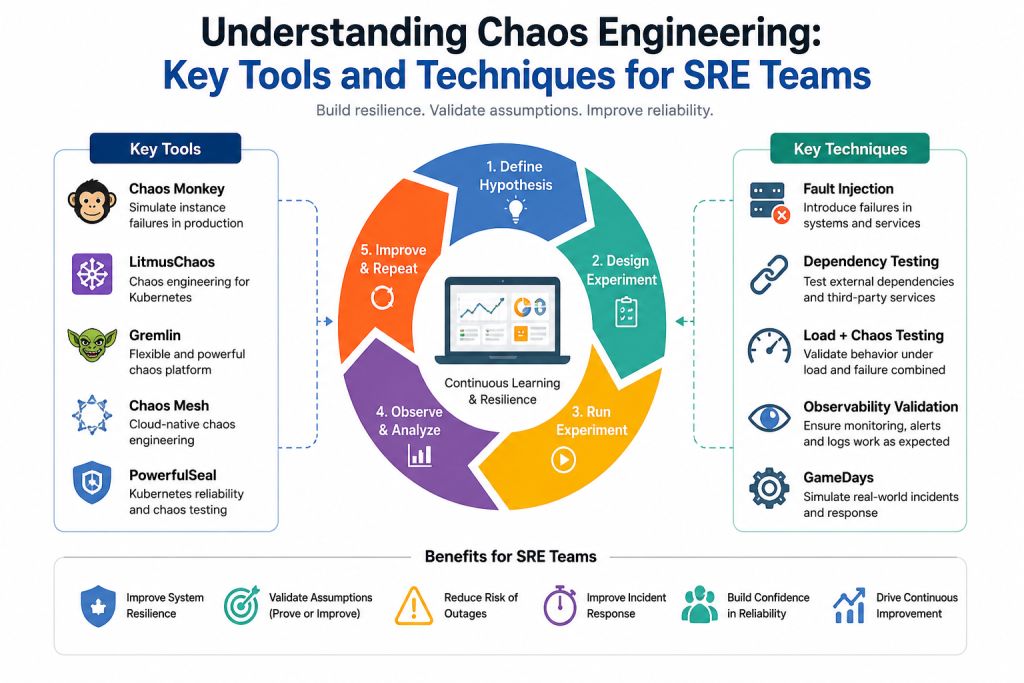
Key Tools and Techniques for SRE
Chaos Engineering relies on specialized tools and methodologies that enable controlled experimentation. These tools help engineers inject failures, observe system behavior, and analyze resilience capabilities.
One widely used technique involves fault injection. Engineers deliberately introduce failures such as service crashes, CPU spikes, memory exhaustion, and network interruptions. These disruptions simulate real-world incidents and reveal how systems respond under adverse conditions.
Another technique focuses on dependency testing. Modern applications depend on databases, messaging systems, APIs, and cloud services. Chaos experiments validate how applications behave when these dependencies become unavailable or experience degraded performance.
Load-based chaos testing combines performance testing with failure injection. Teams evaluate system behavior under heavy traffic while simultaneously introducing disruptions. This approach reveals weaknesses that may not appear during isolated testing.
Observability validation is another important technique. Chaos experiments help verify monitoring systems, alerting mechanisms, logging pipelines, and incident response workflows. Effective observability ensures teams can quickly detect and resolve issues during actual incidents.
Automation frameworks further enhance Chaos Engineering programs by enabling repeatable experiments. Automated testing reduces manual effort and ensures resilience remains validated throughout the software lifecycle.
Popular Chaos Engineering Tools Used by SRE Teams
Several tools have become industry standards for Chaos Engineering initiatives. These platforms provide capabilities for fault injection, experiment management, observability integration, and resilience testing.
Chaos Monkey remains one of the most recognized tools in the industry. Originally developed to test cloud infrastructure resilience, it randomly terminates instances within production environments. This encourages engineers to design systems that tolerate infrastructure failures without service disruption.
LitmusChaos has gained significant popularity in Kubernetes environments. It provides extensive experiment libraries that simulate container failures, network disruptions, resource exhaustion, and node-level issues. Its cloud-native architecture aligns well with modern microservices deployments.
Gremlin offers a comprehensive Chaos Engineering platform with user-friendly interfaces and extensive experiment capabilities. Organizations use Gremlin to test infrastructure resilience, application behavior, and operational readiness across various environments.
Chaos Mesh serves Kubernetes-based environments by enabling network chaos, pod failures, CPU stress testing, disk faults, and time manipulation experiments. Its integration with Kubernetes ecosystems makes it a preferred choice for containerized applications.
PowerfulSeal focuses on Kubernetes reliability testing by simulating node failures, pod terminations, and infrastructure disruptions. It helps teams validate cluster resilience and workload recovery mechanisms.
Each tool supports different experimentation strategies, allowing organizations to select solutions that align with their operational requirements and technical environments.
Designing Effective Chaos Experiments
Successful Chaos Engineering programs depend on carefully designed experiments. Random disruptions without clear objectives provide limited value and may introduce unnecessary risks.
The process begins by defining a hypothesis. Engineers identify expected system behavior during specific failure conditions. For example, a team might hypothesize that an application will maintain availability if one database node becomes unavailable.
Next, teams establish baseline measurements. Key performance indicators provide visibility into normal system behavior and help evaluate experiment outcomes.
Failure injection follows baseline establishment. Engineers introduce controlled disruptions while continuously monitoring system responses. Observability tools capture metrics, logs, traces, and alerts throughout the experiment.
After completing the experiment, teams analyze results and compare observed behavior against original expectations. Deviations often reveal resilience gaps that require remediation.
Finally, organizations document findings and implement improvements. Effective Chaos Engineering transforms experimental insights into operational enhancements that strengthen long-term reliability.
Chaos Engineering in Cloud-Native Environments
Cloud-native architectures introduce unique challenges that make Chaos Engineering increasingly valuable. Dynamic scaling, container orchestration, service meshes, and distributed microservices create complex interactions that traditional testing cannot fully validate.
Containerized workloads frequently move across nodes, scale automatically, and interact with numerous dependencies. Chaos experiments help validate these dynamic behaviors under failure conditions. Teams verify whether orchestration platforms correctly restart failed containers, redistribute workloads, and maintain service availability.
Service meshes introduce additional layers of complexity through traffic routing, load balancing, and security policies. Chaos Engineering tests these components under adverse conditions to ensure reliable communication between services.
Cloud infrastructure itself can experience outages, resource constraints, and networking issues. Chaos experiments validate failover mechanisms, multi-region deployments, backup strategies, and disaster recovery procedures.
By continuously testing cloud-native systems, organizations maintain confidence in their ability to withstand unexpected disruptions while delivering consistent customer experiences.
Key Operational Concepts You Must Know
Operations engineering extends beyond maintaining infrastructure. It involves designing, operating, monitoring, and continuously improving systems that support business services. Several operational concepts form the foundation of successful reliability programs.
Reliability represents the ability of systems to perform expected functions consistently. Engineers measure reliability using service-level indicators and service-level objectives. These metrics guide operational decision-making and prioritize improvement efforts.
Observability provides visibility into system behavior through metrics, logs, and distributed traces. Without strong observability, identifying root causes becomes significantly more difficult.
Incident management ensures rapid detection, response, communication, and resolution during service disruptions. Mature organizations establish structured workflows that reduce recovery times and improve coordination.
Automation reduces manual effort and minimizes human error. Infrastructure provisioning, deployments, monitoring, remediation, and scaling processes benefit significantly from automation.
Capacity planning ensures sufficient resources exist to support current and future workloads. Effective planning prevents performance degradation while optimizing operational costs.
Together, these concepts create a framework that enables reliable, scalable, and resilient operations across complex technology environments.
Platform Implementation vs. Culture — What’s the Real Difference?
Many organizations invest heavily in technology platforms while overlooking cultural transformation. Although platform implementation and culture both contribute to operational excellence, they serve fundamentally different purposes.
Platform implementation focuses on tools, processes, automation frameworks, monitoring systems, cloud infrastructure, and deployment pipelines. These technical capabilities enable operational efficiency and consistency. Without appropriate platforms, teams struggle to manage modern systems effectively.
Culture, however, determines how people interact with these technologies. A strong operational culture encourages collaboration, accountability, continuous learning, experimentation, and shared ownership. Teams proactively identify risks, share knowledge, and work together to improve reliability.
Organizations often assume new platforms automatically improve reliability. In reality, technology alone cannot solve operational challenges. Even advanced tools provide limited value if teams lack collaboration, communication, and improvement mindsets.
The most successful organizations combine strong platforms with healthy cultures. Technology enables operational capabilities, while culture ensures those capabilities are used effectively. Together, they create sustainable foundations for long-term reliability and operational excellence.
Real-World Use Cases of Modern Operations
Modern operations teams support diverse business requirements across industries. Chaos Engineering and reliability practices provide measurable value through numerous real-world applications.
E-commerce organizations use chaos experiments to validate resilience during high-traffic shopping events. By testing infrastructure under peak demand and failure conditions, teams ensure uninterrupted customer experiences during critical revenue periods.
Financial institutions leverage Chaos Engineering to strengthen transaction processing systems. Controlled disruptions help validate failover mechanisms, redundancy architectures, and recovery procedures while maintaining regulatory compliance.
Healthcare providers depend on highly available digital services. Chaos experiments ensure patient records, scheduling platforms, and communication systems remain operational despite infrastructure failures.
Streaming platforms test content delivery networks, media processing systems, and traffic routing mechanisms using Chaos Engineering. These experiments help maintain uninterrupted viewing experiences for millions of users.
Cloud service providers continuously validate infrastructure resilience through automated chaos testing. This proactive approach strengthens platform reliability and improves customer confidence.
Across industries, modern operations practices help organizations identify weaknesses, improve resilience, and reduce the impact of unexpected disruptions.
Common Mistakes in Operations Engineering
Operations engineering requires careful planning, disciplined execution, and continuous improvement. Unfortunately, several common mistakes can undermine reliability initiatives and create operational risks.
One frequent mistake involves focusing solely on uptime metrics. While availability remains important, organizations must also evaluate performance, recovery capabilities, customer experience, and operational efficiency.
Another common issue involves insufficient observability. Teams often deploy monitoring tools without ensuring comprehensive visibility across applications, infrastructure, and dependencies. Limited visibility increases troubleshooting complexity during incidents.
Many organizations delay Chaos Engineering adoption because they fear introducing failures. However, avoiding controlled experimentation often results in larger, uncontrolled failures later.
Overreliance on manual processes creates additional risks. Manual deployments, incident response activities, and infrastructure management increase the likelihood of human error and inconsistent outcomes.
Failure to document operational knowledge presents another challenge. When critical information resides with a few individuals, organizations become vulnerable to knowledge gaps and delayed incident resolution.
Addressing these mistakes strengthens operational maturity and improves long-term reliability outcomes.
How to Become an Operations Expert — Career Roadmap
Building expertise in operations engineering requires a combination of technical knowledge, practical experience, and continuous learning. The journey often begins with foundational infrastructure concepts such as operating systems, networking, databases, and cloud computing.
Aspiring professionals should develop strong Linux administration skills because many production systems rely on Linux-based environments. Networking knowledge also proves essential for understanding connectivity, routing, load balancing, and security principles.
Cloud platforms represent another critical learning area. Understanding compute services, storage systems, networking components, and identity management helps engineers operate modern environments effectively.
Automation skills significantly accelerate career growth. Engineers should learn scripting languages, infrastructure-as-code practices, and configuration management techniques. Automation improves efficiency while reducing operational risk.
Observability expertise remains highly valuable. Professionals should understand monitoring architectures, log analysis, distributed tracing, and alerting strategies.
Recommended skill progression includes:
- Infrastructure fundamentals
- Linux administration
- Networking concepts
- Cloud platforms
- Monitoring and observability
- Automation and scripting
- Container technologies
- Kubernetes administration
- Site Reliability Engineering
- Chaos Engineering practices
- Incident management leadership
Continuous experimentation and hands-on experience ultimately transform theoretical knowledge into operational expertise.
FAQ Section
What is Chaos Engineering?
Chaos Engineering is the practice of intentionally introducing controlled failures into systems to evaluate resilience and improve reliability.
Why is Chaos Engineering important for SRE?
It helps SRE teams identify weaknesses, validate recovery mechanisms, strengthen operational readiness, and reduce production risks.
Can Chaos Engineering be performed in production?
Yes. Many organizations conduct carefully controlled production experiments with limited blast radius and extensive monitoring.
What types of failures can be simulated?
Teams can simulate network latency, server crashes, resource exhaustion, dependency failures, database outages, and infrastructure disruptions.
Is Chaos Engineering only for large companies?
No. Organizations of all sizes can benefit from controlled resilience testing and reliability validation.
How often should chaos experiments be conducted?
Many mature organizations integrate automated chaos testing into continuous delivery pipelines and perform experiments regularly.
Which tools are commonly used for Chaos Engineering?
Popular tools include Chaos Monkey, LitmusChaos, Gremlin, Chaos Mesh, and PowerfulSeal.
Does Chaos Engineering replace traditional testing?
No. Chaos Engineering complements traditional testing by validating resilience under real-world failure conditions.
What skills are required to implement Chaos Engineering?
Engineers benefit from knowledge of cloud platforms, distributed systems, observability, automation, incident management, and SRE practices.
How does Chaos Engineering improve customer experience?
By identifying weaknesses before failures occur, organizations reduce downtime, improve reliability, and deliver more consistent services.
Final Summary
Chaos Engineering has emerged as a critical discipline within modern Site Reliability Engineering. As organizations operate increasingly complex cloud-native environments, traditional testing methods alone cannot validate resilience against real-world failures. Chaos Engineering addresses this challenge by introducing controlled disruptions that reveal weaknesses before customers experience service interruptions.
Through systematic experimentation, teams strengthen failover mechanisms, improve observability, validate recovery processes, and enhance operational readiness. Popular tools such as Chaos Monkey, LitmusChaos, Gremlin, Chaos Mesh, and PowerfulSeal provide practical ways to conduct resilience testing across diverse environments.
Successful implementation requires more than technology. Organizations must combine strong operational platforms with cultures that encourage learning, collaboration, accountability, and continuous improvement. When integrated into broader SRE practices, Chaos Engineering becomes a powerful mechanism for building highly reliable systems.
Professionals who master reliability engineering, observability, automation, cloud infrastructure, and chaos experimentation position themselves as valuable operations experts capable of supporting modern digital businesses. As systems continue to grow in complexity, Chaos Engineering will remain a foundational practice for achieving resilience, reliability, and operational excellence.