Introduction
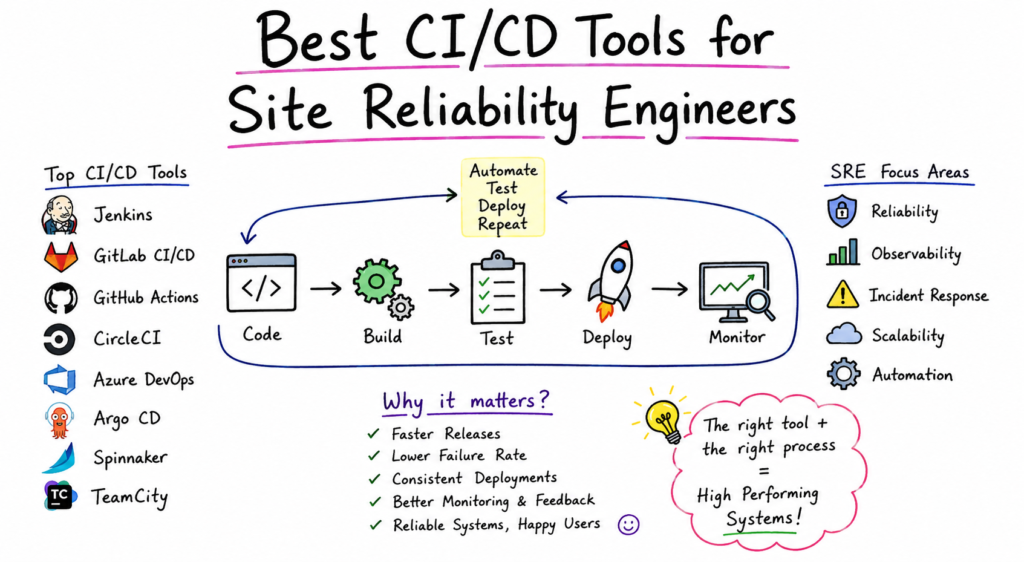
Modern software systems depend on speed, reliability, and automation. Organizations are expected to release new features quickly while maintaining stable and secure services. This is where Continuous Integration and Continuous Delivery (CI/CD) become essential. CI/CD practices help teams automate software building, testing, deployment, and monitoring processes, reducing manual effort and minimizing the risk of errors.
For Site Reliability Engineers (SREs), CI/CD tools play a critical role in maintaining service availability, improving deployment consistency, and ensuring operational excellence. These tools allow engineers to automate repetitive tasks, detect issues early, and create reliable deployment pipelines that support business growth.
Professionals looking to build expertise in modern reliability engineering can learn practical CI/CD implementation techniques through Sreschool, which focuses on industry-relevant operational skills and reliability practices.
In this comprehensive guide, we will explore the best CI/CD tools for Site Reliability Engineers, understand their benefits, examine operational concepts, discuss real-world applications, and provide a roadmap for building a successful career in operations and reliability engineering.
Understanding CI/CD in Site Reliability Engineering
Before exploring specific tools, it is important to understand how CI/CD aligns with the responsibilities of a Site Reliability Engineer.
Continuous Integration refers to the practice of automatically integrating code changes into a shared repository. Every change is tested and validated to ensure it does not break existing functionality.
Continuous Delivery extends this process by ensuring that validated code can be deployed quickly and safely to production environments.
For SRE teams, CI/CD provides several advantages:
- Faster software releases
- Reduced deployment failures
- Improved operational consistency
- Better incident response
- Automated testing and validation
- Increased system reliability
- Enhanced collaboration between development and operations teams
Instead of relying on manual deployments, SREs use automated pipelines that enforce quality standards throughout the software lifecycle.
Why CI/CD Matters for Site Reliability Engineers
Reliability engineering focuses on maintaining system stability while enabling rapid innovation. Without automation, achieving both goals becomes difficult.
CI/CD helps SRE teams by:
Reducing Human Error
Manual deployments often introduce mistakes. Automated pipelines follow predefined procedures, reducing inconsistencies.
Improving Deployment Frequency
Organizations can release updates more often without sacrificing quality.
Accelerating Recovery
Automated rollback mechanisms help teams recover quickly when deployments cause unexpected issues.
Strengthening Monitoring Integration
Modern CI/CD systems integrate directly with observability platforms, allowing engineers to validate system health after deployments.
Supporting Scalability
As organizations grow, automation becomes essential for managing increasing workloads and infrastructure complexity.
Best CI/CD Tools for Site Reliability Engineers
The market offers many CI/CD solutions. However, some platforms stand out because of their reliability, scalability, and operational capabilities.
Jenkins
Jenkins remains one of the most widely used CI/CD platforms in the industry.
Key Features
- Open-source architecture
- Extensive plugin ecosystem
- Flexible pipeline configuration
- Large community support
- Integration with cloud providers
Benefits for SRE Teams
Jenkins enables highly customized workflows. Engineers can create complex deployment pipelines that match specific operational requirements.
Challenges
- Plugin management can become complex
- Requires ongoing maintenance
- User interface may feel outdated
Despite these challenges, Jenkins remains a powerful solution for organizations seeking maximum flexibility.
GitLab CI/CD
GitLab provides a fully integrated DevOps platform that includes source control, CI/CD, security testing, and monitoring.
Key Features
- Built-in pipeline management
- Infrastructure automation support
- Security scanning capabilities
- Kubernetes integration
- Unified platform experience
Benefits for SRE Teams
GitLab reduces tool sprawl by centralizing multiple workflows within a single platform.
Challenges
- Resource-intensive deployments
- Learning curve for advanced features
GitLab works especially well for organizations seeking an all-in-one DevOps solution.
GitHub Actions
GitHub Actions has become a popular choice due to its simplicity and seamless integration with GitHub repositories.
Key Features
- Native GitHub integration
- Event-driven automation
- Marketplace of reusable actions
- Easy workflow creation
- Strong community support
Benefits for SRE Teams
Engineers can automate testing, deployment, monitoring, and incident response workflows directly within GitHub.
Challenges
- Advanced workflows may require customization
- Enterprise-scale governance may require additional planning
GitHub Actions is ideal for teams already using GitHub for source control.
CircleCI
CircleCI focuses on speed, scalability, and developer productivity.
Key Features
- Fast build execution
- Parallel testing
- Cloud-native architecture
- Container support
- Performance optimization tools
Benefits for SRE Teams
CircleCI helps reduce deployment times while maintaining pipeline reliability.
Challenges
- Advanced configurations can become complex
- Pricing may increase with large workloads
Organizations prioritizing deployment speed often choose CircleCI.
Azure DevOps Pipelines
Azure DevOps offers enterprise-grade CI/CD capabilities with strong integration across Microsoft technologies.
Key Features
- Multi-stage pipelines
- Infrastructure automation
- Security controls
- Cloud integration
- Release management capabilities
Benefits for SRE Teams
Azure DevOps supports large-scale operational environments with extensive governance requirements.
Challenges
- Complexity for smaller teams
- Requires familiarity with Azure ecosystem
Large enterprises frequently adopt Azure DevOps due to its robust capabilities.
TeamCity
TeamCity is a mature CI/CD solution known for its reliability and advanced build management features.
Key Features
- Intelligent build history
- Distributed build support
- Detailed reporting
- Strong version control integration
- Flexible deployment workflows
Benefits for SRE Teams
TeamCity provides deep visibility into build performance and deployment processes.
Challenges
- Licensing considerations
- More administration compared to lightweight alternatives
Organizations with complex build requirements often benefit from TeamCity.
Argo CD
Argo CD has become increasingly popular for Kubernetes-based environments.
Key Features
- GitOps workflow model
- Kubernetes-native architecture
- Automated synchronization
- Rollback capabilities
- Declarative deployment management
Benefits for SRE Teams
Argo CD simplifies infrastructure management and improves deployment consistency.
Challenges
- Kubernetes knowledge required
- Initial setup complexity
For cloud-native operations, Argo CD is one of the strongest deployment solutions available.
Spinnaker
Spinnaker specializes in multi-cloud deployment automation.
Key Features
- Advanced deployment strategies
- Multi-cloud support
- Canary deployments
- Automated rollbacks
- Continuous delivery focus
Benefits for SRE Teams
Spinnaker enables safer releases across complex cloud environments.
Challenges
- Significant operational overhead
- Steeper learning curve
Large-scale organizations often choose Spinnaker for sophisticated deployment requirements.
Comparison Table of Leading CI/CD Tools
| Tool | Best For | Complexity | Scalability |
|---|---|---|---|
| Jenkins | Custom workflows | High | High |
| GitLab CI/CD | Integrated DevOps | Medium | High |
| GitHub Actions | GitHub users | Low | Medium |
| CircleCI | Fast pipelines | Medium | High |
| Azure DevOps | Enterprise operations | High | High |
| TeamCity | Build management | Medium | High |
| Argo CD | Kubernetes deployments | Medium | High |
| Spinnaker | Multi-cloud delivery | High | Very High |
Key Operational Concepts You Must Know
Site Reliability Engineers must understand several operational concepts beyond CI/CD tooling.
Infrastructure as Code
Infrastructure should be defined through code rather than manual configuration.
Benefits include:
- Consistency
- Version control
- Repeatability
- Faster provisioning
Popular tools include Terraform and Ansible.
Observability
Observability helps teams understand system behavior through:
- Metrics
- Logs
- Traces
Strong observability enables faster troubleshooting and performance optimization.
Incident Management
Every operational team must have a structured incident response process.
Important elements include:
- Alerting
- Escalation procedures
- Communication plans
- Post-incident reviews
Automation
Automation eliminates repetitive tasks and improves operational efficiency.
Examples include:
- Deployment automation
- Infrastructure provisioning
- Monitoring setup
- Backup management
Reliability Engineering
Reliability engineering focuses on maintaining service quality through measurable objectives.
Common concepts include:
- Service Level Indicators
- Service Level Objectives
- Error budgets
- Capacity planning
These metrics help teams balance innovation with stability.
Platform Implementation vs. Culture — What’s the Real Difference?
Many organizations mistakenly believe that adopting CI/CD tools automatically creates operational excellence.
The reality is different.
Technology is only one part of the equation.
Platform Implementation
Platform implementation focuses on technical capabilities.
Examples include:
- CI/CD pipelines
- Infrastructure automation
- Monitoring systems
- Deployment frameworks
- Security integrations
These tools enable automation but do not guarantee success.
Operational Culture
Culture determines how teams use technology.
Important cultural elements include:
- Shared ownership
- Continuous improvement
- Learning from failures
- Collaboration
- Accountability
Organizations with strong culture often outperform teams using better technology but poor collaboration practices.
Why Culture Usually Wins
Even the most advanced platform can fail when teams:
- Ignore monitoring alerts
- Avoid documentation
- Resist automation
- Work in isolated silos
Meanwhile, teams with strong collaboration often achieve excellent reliability using relatively simple tools.
The most successful organizations combine technical excellence with operational discipline.
Real-World Use Cases of Modern Operations
Understanding practical applications helps demonstrate the value of CI/CD and reliability engineering.
Automated Production Deployments
Organizations use CI/CD pipelines to release software automatically after successful testing.
Benefits include:
- Faster delivery
- Reduced risk
- Consistent deployments
Blue-Green Deployments
Traffic shifts gradually from an old version to a new version.
Advantages include:
- Minimal downtime
- Easy rollback
- Reduced deployment risk
Canary Releases
New features are released to a small group of users before broader rollout.
Benefits include:
- Early issue detection
- Reduced impact
- Safer releases
Infrastructure Provisioning
Infrastructure as Code enables automatic creation of servers, networks, and cloud resources.
Advantages include:
- Consistency
- Faster deployment
- Reduced manual work
Disaster Recovery Automation
Automation ensures systems can recover quickly after failures.
Capabilities include:
- Backup restoration
- Failover activation
- Environment rebuilding
Security Compliance Validation
Modern pipelines automatically verify compliance requirements before deployment.
Examples include:
- Vulnerability scanning
- Configuration validation
- Secret detection
This reduces operational risk significantly.
Common Mistakes in Operations Engineering
Many teams encounter avoidable problems while implementing operational practices.
Over-Automating Too Early
Automation should solve real problems.
Automating unstable processes often amplifies existing issues.
Ignoring Monitoring
Deployments without monitoring create blind spots.
Teams must validate system health continuously.
Weak Documentation
Operational knowledge should never exist only in someone’s memory.
Documentation supports scalability and knowledge sharing.
Lack of Rollback Strategies
Every deployment plan should include rollback procedures.
Recovery planning is just as important as release planning.
Alert Fatigue
Too many alerts reduce effectiveness.
Engineers eventually begin ignoring notifications.
Teams should focus on meaningful alerts that require action.
Treating Reliability as an Afterthought
Reliability should be built into systems from the beginning.
Waiting until production problems occur often increases costs and complexity.
Neglecting Security
Security must be integrated into CI/CD pipelines rather than handled separately.
This approach reduces vulnerabilities and strengthens operational resilience.
How to Become an Operations Expert — Career Roadmap
Operations engineering offers excellent career opportunities for individuals interested in automation, infrastructure, reliability, and cloud technologies.
Step 1: Learn Linux Fundamentals
Linux knowledge forms the foundation of most operational environments.
Focus on:
- Command line skills
- Process management
- Networking basics
- File systems
Step 2: Understand Networking
Networking knowledge is essential for troubleshooting distributed systems.
Learn:
- DNS
- TCP/IP
- Load balancing
- Firewalls
- Routing
Step 3: Master Cloud Platforms
Modern operations heavily rely on cloud services.
Key areas include:
- Compute services
- Storage systems
- Networking
- Identity management
Step 4: Learn Infrastructure as Code
Automation is a core operational skill.
Focus on:
- Terraform
- Configuration management
- Environment provisioning
Step 5: Develop Programming Skills
Operations professionals increasingly write code.
Useful languages include:
- Python
- Go
- Bash
Programming enables automation and tooling development.
Step 6: Learn CI/CD Platforms
Gain practical experience with:
- Jenkins
- GitLab CI/CD
- GitHub Actions
- Argo CD
Build real deployment pipelines to strengthen your skills.
Step 7: Study Observability
Understand:
- Metrics
- Logging
- Tracing
- Alerting
Observability is critical for maintaining reliability.
Step 8: Practice Incident Management
Participate in troubleshooting exercises and outage simulations.
Experience is one of the best teachers in operations engineering.
Step 9: Build Real Projects
Create:
- Automated deployment pipelines
- Monitoring systems
- Infrastructure automation projects
- Cloud environments
Hands-on practice accelerates learning.
Step 10: Develop Reliability Mindset
Operations experts think proactively.
They focus on:
- Prevention
- Automation
- Scalability
- Continuous improvement
This mindset separates excellent engineers from average practitioners.
Role-Based CI/CD Tool Recommendations
Different roles may benefit from different CI/CD platforms.
Startup Teams
Recommended tools:
- GitHub Actions
- GitLab CI/CD
- CircleCI
Reasons:
- Fast implementation
- Lower operational overhead
- Rapid development cycles
Enterprise Organizations
Recommended tools:
- Jenkins
- Azure DevOps
- TeamCity
Reasons:
- Extensive governance
- Custom workflows
- Large-scale support
Cloud-Native Teams
Recommended tools:
- Argo CD
- GitLab CI/CD
- Spinnaker
Reasons:
- Kubernetes integration
- GitOps workflows
- Multi-cloud deployment support
Reliability-Focused Teams
Recommended tools:
- Jenkins
- Argo CD
- GitLab CI/CD
Reasons:
- Strong automation capabilities
- Advanced deployment controls
- Operational flexibility
FAQ Section
What is CI/CD in Site Reliability Engineering?
CI/CD is a set of practices that automate software integration, testing, and deployment processes to improve reliability and delivery speed.
Why do SREs use CI/CD tools?
SREs use CI/CD tools to automate deployments, reduce human error, improve consistency, and maintain system reliability.
Which CI/CD tool is best for beginners?
GitHub Actions is often considered beginner-friendly because of its simple setup and strong integration with source code repositories.
Is Jenkins still relevant?
Yes. Jenkins remains widely used because of its flexibility, large plugin ecosystem, and support for complex workflows.
What is GitOps?
GitOps is an operational model where infrastructure and deployment configurations are managed through version-controlled repositories.
Do Site Reliability Engineers need programming skills?
Yes. Programming helps automate repetitive tasks, build operational tools, and improve infrastructure management.
What is the difference between CI and CD?
Continuous Integration focuses on code validation and testing, while Continuous Delivery focuses on safely deploying validated changes.
Why is observability important?
Observability helps teams understand system behavior, identify issues quickly, and improve reliability through data-driven insights.
Can small teams benefit from CI/CD?
Absolutely. Automation helps teams of all sizes improve efficiency, consistency, and deployment quality.
What is the most important skill for operations engineers?
A strong understanding of automation, troubleshooting, systems thinking, and reliability principles is essential.
Final Summary
CI/CD has become a fundamental component of modern Site Reliability Engineering. As organizations continue to prioritize faster software delivery and higher service availability, automation-driven workflows provide the foundation for operational success.
Tools such as Jenkins, GitLab CI/CD, GitHub Actions, CircleCI, Azure DevOps, TeamCity, Argo CD, and Spinnaker each offer unique strengths. The best choice depends on organizational goals, infrastructure complexity, team expertise, and scalability requirements.
However, successful operations extend beyond technology alone. Reliability depends on a combination of automation, observability, incident management, documentation, collaboration, and continuous improvement. Teams that combine strong operational culture with effective platform implementation consistently achieve better outcomes.
For aspiring operations professionals, mastering Linux, networking, cloud platforms, infrastructure automation, CI/CD pipelines, observability systems, and reliability engineering principles provides a clear path toward long-term career growth. By developing both technical expertise and operational mindset, engineers can build resilient systems capable of supporting modern business demands while maintaining the high standards of reliability that users expect.
Many teams select CI/CD tools based on deployment speed, but reliability often depends on rollback automation and deployment observability. Evaluating how quickly a platform detects failures and supports safe recovery can be just as important as release velocity.
One missing angle is CI/CD pipeline reliability itself. Tool selection matters, but SRE teams also need to think about rollback speed, deployment observability, flaky pipeline behavior, and how release automation integrates with incident response when a bad change reaches production.