Introduction
Site Reliability Engineering (SRE) focuses on creating reliable, scalable, and efficient systems while reducing manual operational work. As organizations grow, managing infrastructure manually becomes difficult, error-prone, and time-consuming. This challenge led to the adoption of Infrastructure as Code (IaC), a practice that allows teams to define, provision, and manage infrastructure using code.
Terraform has become one of the most widely adopted Infrastructure as Code tools because it enables teams to automate infrastructure deployment across multiple cloud providers and platforms. Instead of manually creating servers, networks, storage resources, and security policies, teams can define everything in configuration files and deploy consistent environments repeatedly.
Organizations that want to improve reliability, automation, and operational efficiency often learn modern infrastructure practices through providers such as Sreschool. By combining Terraform with SRE principles, teams can achieve greater consistency, faster deployments, improved disaster recovery, and reduced operational risks.
In this guide, you will learn how Terraform supports Infrastructure as Code in SRE environments, how it works, implementation strategies, operational best practices, common mistakes, real-world use cases, and the roadmap for becoming an operations expert.
Understanding Infrastructure as Code in SRE
Infrastructure as Code is the practice of managing infrastructure through machine-readable configuration files rather than manual processes.
Traditionally, system administrators logged into servers, configured resources manually, installed software, and maintained infrastructure through repetitive tasks. Although this method worked for small environments, it created inconsistencies and operational risks as systems expanded.
SRE teams require infrastructure that can be deployed consistently and repeatedly. Every environment must behave predictably. Terraform helps achieve this objective by allowing engineers to define infrastructure declaratively.
Instead of documenting steps in a manual process, engineers write configuration files describing the desired infrastructure state. Terraform then calculates the required actions and provisions the resources automatically.
This approach provides several advantages:
- Repeatable deployments
- Reduced human errors
- Faster provisioning
- Version-controlled infrastructure
- Improved disaster recovery
- Better collaboration between teams
- Simplified compliance management
Infrastructure becomes a software asset that can be reviewed, tested, and improved continuously.
What is Terraform?
Terraform is an Infrastructure as Code tool that allows users to define infrastructure using configuration files.
Terraform uses a declarative language called HashiCorp Configuration Language (HCL). Engineers describe the desired end state rather than specifying every operational step.
For example, instead of manually creating:
- Virtual machines
- Load balancers
- Storage accounts
- Databases
- Security groups
- DNS records
Terraform can provision all these resources automatically through code.
The tool supports multiple platforms including:
- AWS
- Azure
- Google Cloud
- Kubernetes
- VMware
- Oracle Cloud
- Alibaba Cloud
- GitHub
- Datadog
- Cloudflare
This flexibility makes Terraform valuable for organizations operating across different environments.
Why SRE Teams Prefer Terraform
SRE teams focus on reliability, automation, scalability, and operational excellence.
Terraform directly supports these goals.
Consistency Across Environments
Development, testing, staging, and production environments often drift apart when managed manually.
Terraform ensures all environments are built from the same configuration files.
As a result:
- Configuration differences decrease
- Deployment failures reduce
- Troubleshooting becomes easier
Faster Infrastructure Deployment
Provisioning infrastructure manually can take hours or days.
Terraform automates resource creation and significantly reduces deployment times.
Engineers can create complete environments within minutes.
Improved Disaster Recovery
Infrastructure definitions remain stored in version control systems.
If an environment fails, teams can recreate it quickly using Terraform configurations.
This capability improves resilience and business continuity.
Better Change Management
Every infrastructure modification becomes a code change.
Teams can:
- Review changes
- Track history
- Approve updates
- Roll back when necessary
This process improves governance and operational visibility.
Scalability
As applications grow, infrastructure requirements increase.
Terraform allows teams to scale resources through code modifications rather than manual intervention.
Core Terraform Components
Understanding Terraform’s architecture is essential for successful implementation.
Providers
Providers connect Terraform to external platforms.
Examples include:
- AWS Provider
- Azure Provider
- Kubernetes Provider
- GitHub Provider
Providers translate Terraform configurations into API calls.
Resources
Resources represent infrastructure components.
Examples include:
- Virtual machines
- Databases
- Networks
- Security groups
- Containers
Resources form the building blocks of infrastructure definitions.
Variables
Variables make configurations reusable.
Instead of hardcoding values, teams can define variables for:
- Regions
- Instance sizes
- Environment names
- Network ranges
This improves flexibility and maintainability.
Outputs
Outputs expose information after deployment.
Examples include:
- Server IP addresses
- Database endpoints
- Load balancer URLs
Outputs help integrate Terraform with other tools.
State Files
Terraform maintains a state file that tracks deployed resources.
The state file allows Terraform to understand:
- Existing infrastructure
- Required changes
- Resource dependencies
State management is one of the most important aspects of Terraform operations.
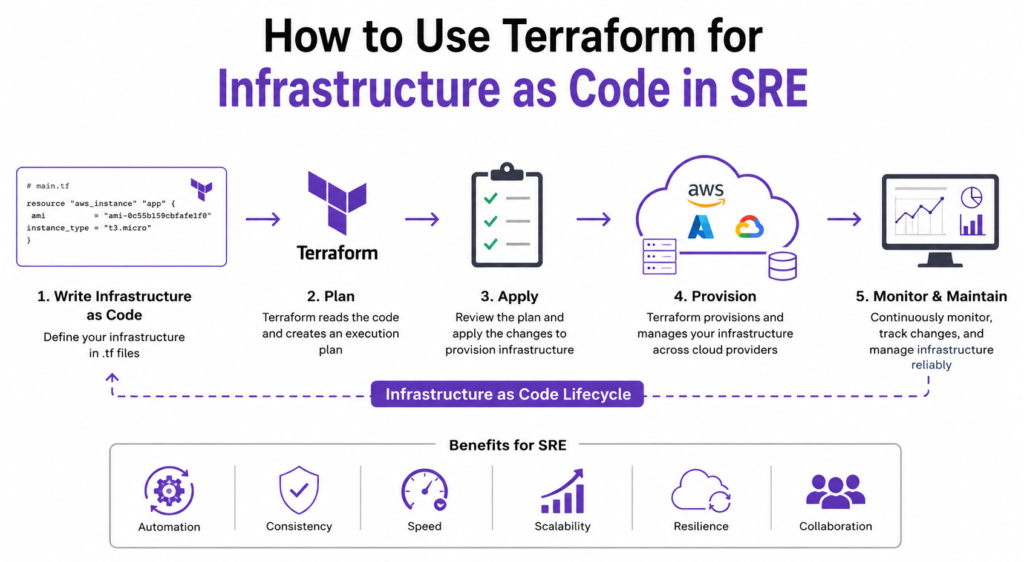
Terraform Workflow in SRE
Terraform follows a structured workflow.
Step 1: Write Configuration
Engineers create infrastructure definitions using HCL.
The configuration specifies the desired infrastructure.
Step 2: Initialize Terraform
Initialization downloads required providers and modules.
This prepares the working environment.
Step 3: Validate Configuration
Validation checks configuration syntax and identifies errors.
This step helps prevent deployment failures.
Step 4: Generate Execution Plan
Terraform compares the desired state with the existing state.
The execution plan shows:
- Resources to create
- Resources to modify
- Resources to remove
This transparency improves operational confidence.
Step 5: Apply Changes
Terraform executes the approved plan.
Resources are created or updated automatically.
Step 6: Monitor Infrastructure
SRE teams monitor deployed resources to verify reliability and performance.
Monitoring systems validate operational health after deployment.
Terraform and Reliability Engineering
Reliability is the foundation of SRE.
Terraform contributes directly to reliability objectives.
Standardized Infrastructure
Infrastructure standards reduce operational variability.
Every deployment follows the same blueprint.
This consistency reduces unexpected failures.
Reduced Configuration Drift
Manual changes often introduce inconsistencies.
Terraform continuously maintains the desired state.
This minimizes drift between environments.
Faster Recovery
Infrastructure can be recreated rapidly from code.
Recovery times improve significantly.
Controlled Changes
Every change passes through review and approval processes.
Risky modifications become easier to identify.
Automation
Automation removes repetitive manual tasks.
As a result:
- Human errors decrease
- Operational efficiency increases
- Reliability improves
Key Operational Concepts You Must Know
Successful Terraform adoption requires understanding several operational principles.
Desired State Management
Terraform focuses on the desired end state.
Engineers define what infrastructure should look like rather than specifying every procedural step.
Terraform determines the necessary actions automatically.
Immutable Infrastructure
Instead of modifying servers manually, teams replace outdated resources with new versions.
This approach improves consistency and reduces configuration drift.
Infrastructure Version Control
Infrastructure code should be stored in repositories.
Version control enables:
- Change tracking
- Collaboration
- Auditing
- Rollbacks
Change Review Process
Infrastructure changes should undergo peer review.
Reviews improve quality and reduce deployment risks.
State Management
State files contain critical infrastructure information.
Teams must secure, back up, and manage state carefully.
Poor state management can cause operational failures.
Automation Pipelines
Terraform works best when integrated into CI/CD pipelines.
Automation ensures:
- Consistency
- Faster deployment
- Reduced manual effort
Terraform Best Practices for SRE Teams
Organize Code Properly
Use logical directory structures.
Separate:
- Development
- Testing
- Production
This improves maintainability.
Use Remote State Storage
Avoid storing state locally.
Remote state improves:
- Collaboration
- Security
- Availability
Implement State Locking
State locking prevents multiple users from modifying infrastructure simultaneously.
This avoids corruption and deployment conflicts.
Follow Naming Standards
Consistent naming improves visibility and management.
Create naming conventions for:
- Servers
- Databases
- Networks
- Security groups
Use Modules
Modules allow code reuse.
Benefits include:
- Reduced duplication
- Easier maintenance
- Standardization
Apply Least Privilege
Terraform accounts should have only the permissions required to perform assigned tasks.
This improves security.
Platform Implementation vs. Culture — What’s the Real Difference?
Many organizations assume implementing Terraform automatically creates operational excellence.
In reality, technology alone does not solve operational challenges.
Platform Implementation
Platform implementation focuses on tools, automation, infrastructure, and technical capabilities.
Examples include:
- Terraform deployment
- Cloud infrastructure
- Monitoring platforms
- CI/CD pipelines
- Incident management tools
These technologies provide the foundation for efficient operations.
However, tools alone cannot guarantee reliability.
Operational Culture
Culture defines how people work together.
Strong operational culture emphasizes:
- Ownership
- Accountability
- Collaboration
- Learning
- Continuous improvement
Teams with strong culture use tools effectively.
Teams with weak culture often struggle despite having advanced technology.
Why Culture Matters More
A highly automated environment can still experience outages if teams:
- Ignore monitoring alerts
- Skip reviews
- Avoid documentation
- Fail to communicate
Operational excellence emerges when culture and technology support each other.
Terraform provides automation, but culture ensures responsible usage.
Real-World Use Cases of Modern Operations
Modern organizations use Terraform in many operational scenarios.
Cloud Infrastructure Provisioning
Companies deploy entire cloud environments through code.
Resources include:
- Networks
- Servers
- Storage
- Databases
Provisioning becomes faster and more consistent.
Kubernetes Deployment
Organizations automate Kubernetes infrastructure creation.
Terraform manages:
- Clusters
- Node groups
- Networking
- Security settings
This simplifies container platform management.
Disaster Recovery Automation
Recovery environments can be recreated quickly from Terraform configurations.
Business continuity improves significantly.
Multi-Cloud Management
Organizations operating across multiple providers use Terraform to manage infrastructure consistently.
This reduces operational complexity.
Security Standardization
Terraform automates security controls.
Examples include:
- Firewall rules
- IAM policies
- Network segmentation
This improves compliance and reduces risk.
Environment Replication
Development teams often require environments identical to production.
Terraform enables rapid environment replication.
Testing accuracy improves substantially.
Common Mistakes in Operations Engineering
Even experienced teams make operational mistakes.
Understanding these issues helps avoid failures.
Ignoring State Security
State files often contain sensitive information.
Failure to secure them creates security risks.
Always apply strict access controls.
Manual Infrastructure Changes
Direct changes outside Terraform create configuration drift.
Eventually, environments become inconsistent.
All modifications should flow through Terraform.
Poor Module Design
Large monolithic configurations become difficult to maintain.
Create reusable and focused modules.
Lack of Documentation
Infrastructure code should include documentation.
Future team members need context and operational guidance.
Skipping Reviews
Unreviewed changes increase deployment risk.
Peer reviews catch mistakes early.
Overcomplicated Configurations
Complex infrastructure definitions become difficult to troubleshoot.
Keep configurations simple and maintainable.
Inadequate Testing
Infrastructure changes require validation before production deployment.
Testing reduces operational surprises.
How to Become an Operations Expert — Career Roadmap
Operations engineering combines infrastructure, automation, reliability, security, and problem-solving skills.
A structured learning path accelerates professional growth.
Step 1: Learn Operating Systems
Understand:
- Linux fundamentals
- System administration
- Process management
- Networking basics
Strong foundations are essential.
Step 2: Master Cloud Platforms
Learn core cloud services.
Focus on:
- Compute
- Networking
- Storage
- Identity management
Cloud knowledge is now a core requirement.
Step 3: Learn Infrastructure as Code
Develop expertise in Terraform.
Practice:
- Resource creation
- Module development
- State management
- Automation workflows
Hands-on experience matters most.
Step 4: Understand Monitoring
Learn monitoring and observability concepts.
Study:
- Metrics
- Logs
- Traces
- Alerting systems
Visibility drives reliability.
Step 5: Build Automation Skills
Automation increases operational efficiency.
Learn:
- Shell scripting
- Python
- CI/CD pipelines
Automation expertise distinguishes strong engineers.
Step 6: Study Reliability Engineering
Understand:
- Service Level Indicators
- Service Level Objectives
- Error budgets
- Incident management
These concepts define modern operations.
Step 7: Develop Troubleshooting Skills
Operations experts solve problems efficiently.
Practice diagnosing:
- Infrastructure failures
- Performance issues
- Application outages
Experience builds confidence.
Step 8: Improve Communication
Technical expertise alone is not enough.
Operations leaders communicate effectively during:
- Incidents
- Reviews
- Planning sessions
- Cross-team collaboration
Strong communication improves outcomes.
Terraform Implementation Strategy for Enterprise SRE Teams
Large organizations require structured implementation plans.
Assessment Phase
Evaluate:
- Existing infrastructure
- Current deployment processes
- Security requirements
- Compliance constraints
Understanding the starting point is critical.
Pilot Phase
Begin with non-critical workloads.
This approach allows teams to gain experience safely.
Standardization Phase
Create:
- Modules
- Naming conventions
- Security policies
- Deployment workflows
Standards improve consistency.
Automation Phase
Integrate Terraform into deployment pipelines.
Reduce manual processes wherever possible.
Optimization Phase
Continuously improve:
- Performance
- Cost efficiency
- Security
- Reliability
Operational maturity grows over time.
Measuring Terraform Success in SRE
Organizations should track measurable outcomes.
Key metrics include:
| Metric | Operational Impact |
|---|---|
| Deployment Time | Faster infrastructure delivery |
| Change Failure Rate | Reduced deployment issues |
| Recovery Time | Faster disaster recovery |
| Infrastructure Drift | Improved consistency |
| Automation Coverage | Reduced manual effort |
| Incident Frequency | Better reliability |
| Provisioning Accuracy | Fewer configuration errors |
Monitoring these metrics helps validate success.
FAQ Section
What is Terraform in SRE?
Terraform is an Infrastructure as Code tool that helps SRE teams automate infrastructure provisioning, management, and scaling through configuration files.
Why do SRE teams use Terraform?
SRE teams use Terraform to improve consistency, reliability, automation, scalability, and disaster recovery capabilities.
Does Terraform support multiple cloud providers?
Yes. Terraform supports AWS, Azure, Google Cloud, Kubernetes, VMware, and many other platforms through providers.
What is a Terraform state file?
A state file stores information about deployed infrastructure and allows Terraform to track resources and changes.
Why is Infrastructure as Code important?
Infrastructure as Code reduces manual work, improves consistency, enables automation, and supports repeatable deployments.
Can Terraform help with disaster recovery?
Yes. Terraform allows teams to recreate infrastructure quickly from code, improving recovery speed and reliability.
What skills should an operations engineer learn?
Operations engineers should learn Linux, networking, cloud platforms, Terraform, automation, monitoring, reliability engineering, and troubleshooting.
Is Terraform suitable for enterprise environments?
Yes. Terraform supports enterprise-scale infrastructure management through modules, automation, policy controls, and multi-cloud capabilities.
How does Terraform improve operational reliability?
Terraform standardizes deployments, reduces human errors, prevents configuration drift, and supports automated recovery processes.
What is the biggest mistake teams make with Terraform?
One of the most common mistakes is making manual infrastructure changes outside Terraform, which creates configuration drift and operational inconsistencies.
Final Summary
Terraform has become a foundational technology for Infrastructure as Code and modern Site Reliability Engineering practices. By defining infrastructure through code, organizations achieve consistency, automation, scalability, and operational efficiency. Instead of relying on manual provisioning and configuration management, teams can create predictable environments that support reliability objectives.
Successful Terraform adoption requires more than writing configuration files. Teams must understand state management, automation pipelines, infrastructure version control, operational reviews, security practices, and reliability principles. When Terraform integrates with strong operational culture, organizations gain significant improvements in deployment speed, recovery capabilities, governance, and system stability.
SRE teams that embrace Infrastructure as Code create environments that are easier to maintain, easier to recover, and easier to scale. As infrastructure complexity continues to grow, Terraform remains one of the most effective tools for building reliable and automated operations. For engineers pursuing careers in operations, cloud engineering, platform engineering, or reliability engineering, mastering Terraform is a valuable step toward becoming a highly effective operations expert.
dasdasdad
One area that deserves more attention is Terraform state management at scale. As teams grow, remote state locking, access control, and recovery from state corruption become critical operational concerns. Many production incidents are caused not by the infrastructure code itself, but by poorly managed state files and out-of-band changes that introduce configuration drift.
A practical gap in Terraform discussions is state management at scale. Once multiple teams and environments share infrastructure workflows, remote state locking, module versioning, drift detection, and safe rollback practices become just as important as writing the Terraform code itself.